Dpark的性能怎么样?
188 views
Skip to first unread message

kenneth
Jul 5, 2013, 6:47:24 AM7/5/13
to dpark...@googlegroups.com
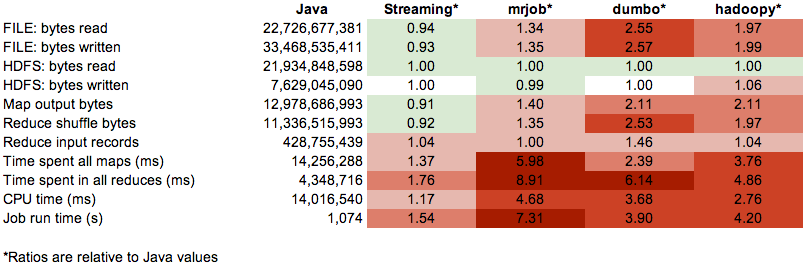
我今天看到一个Hadoop性能的比较图,就想和Dpark比较一下。
希望高手能对Dpark做一个profile图的观点是这样:
Java明显最快,,Streaming要多花一半时间,Python框架花的时间更多。从mrjob mapper的profile数据来看,它在序列化/反序列化上花费了大量时间。dumbo和hadoopy在这方面要好一点。如果用了combiner 的话dumbo 还可以更快。

--
http://www.mvmap.com
--
http://www.mvmap.com

muxueqz(张明源)
Jul 5, 2013, 7:41:39 AM7/5/13
to dpark...@googlegroups.com
没Hadoop环境对比,之后可能会有,届时再测试看看
--
You received this message because you are subscribed to the Google Groups "DPark Users" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dpark-users...@googlegroups.com.
For more options, visit https://groups.google.com/groups/opt_out.
明源
http://muxueqz.laou.me
Twitter: @muxueqz

Davies Liu
Jul 5, 2013, 8:36:41 AM7/5/13
to dpark...@googlegroups.com
DPark+MooseFS 应该可以做到被所有基于Hadoop的Python框架更快, 因为它底层的依赖最轻, 没有JVM的拖累启动任务也很快. DPark 在Shuffle时不排序, Reduce 时尽量多使用内存.
因此文件系统的差异, 一般不会部署 MooseFS 和 HDFS 两套, 实际使用者不太好做评测. 有兴趣的同学可以帮忙填补这个空白.
--
You received this message because you are subscribed to the Google Groups "DPark Users" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dpark-users...@googlegroups.com.
For more options, visit https://groups.google.com/groups/opt_out.
- Davies
muxueqz(张明源)
Oct 9, 2013, 11:13:17 PM10/9/13
to dpark...@googlegroups.com
对了,有用pypy做过性能对比吗?我之前用pypy运行dpark遇到一些问题,屏蔽掉之后也比CPython要慢很多
Davies Liu
Oct 9, 2013, 11:47:42 PM10/9/13
to dpark...@googlegroups.com
我做过单机版的测试,在对DPark做一些针对 pypy 优化后(比如itertools相关),两者性能相当,部分模块CPython快,部分代码pypy快。
目前看来使用PyPy的话,除非个别特殊情况,不会有明显的性能提升,还会增加不少使用麻烦,不推荐使用。
Davies
- Davies

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
田忠博
Oct 10, 2013, 3:20:19 AM10/10/13
to dpark...@googlegroups.com
To muxueqz,
几天前为兼容pypy做了一些调整,已经提交。但是测试结果并没有显示pypy对比CPython有更多优势。如果有兴趣的话可以一起来研究下如何在pypy下加速dpark
另外为dpark增加了Numba(https://github.com/numba/numba)的jit的支持,可以将函数上的Numba decorator应用在远端。这样某些计算密集的函数可以利用llvm来做jit,加速执行。
几天前为兼容pypy做了一些调整,已经提交。但是测试结果并没有显示pypy对比CPython有更多优势。如果有兴趣的话可以一起来研究下如何在pypy下加速dpark
另外为dpark增加了Numba(https://github.com/numba/numba)的jit的支持,可以将函数上的Numba decorator应用在远端。这样某些计算密集的函数可以利用llvm来做jit,加速执行。
{kind=link}
{kind=link}
田忠博
Oct 10, 2013, 4:21:27 AM10/10/13
to dpark...@googlegroups.com
Numba 的确不是万能灵药,但是对部分场景还是有用处的。
目前DPark的功能看上去是基本完善了,性能评测看起来还是没有什么大问题。主体部分大概还是以修正bug为主。
dpark的附加部分 dquery 和 dstreaming 会根据使用情况进行进一步的完善。
正在考虑中的新功能包括:
类似dpark中GraphX的对图数据结构的支持
对TableRDD的重构和改进
目前暂不考虑跟进spark的fair scheduler以及yarn支持,如果大家对此有需求也有兴趣的话欢迎贡献pr。
目前DPark的功能看上去是基本完善了,性能评测看起来还是没有什么大问题。主体部分大概还是以修正bug为主。
dpark的附加部分 dquery 和 dstreaming 会根据使用情况进行进一步的完善。
正在考虑中的新功能包括:
类似dpark中GraphX的对图数据结构的支持
对TableRDD的重构和改进
目前暂不考虑跟进spark的fair scheduler以及yarn支持,如果大家对此有需求也有兴趣的话欢迎贡献pr。
{kind=link}
Reply all
Reply to author
Forward
0 new messages