Delta Merge When Matched AND Conditions
2,022 views
Skip to first unread message

Logan Boyd
Jun 1, 2021, 11:11:04 PM6/1/21
to Delta Lake Users and Developers
We are using Delta Table Merge statement but we would like to only update rows in the destination when both the ID between our source and destination are matched AND the data in that row is actually different. I've accomplished this in the past in SQL Server DW by using an EXCEPT clause to produce a set of rows where the data in at least one column was different
Example:
Source Table
ID - NAME - CITY
1 - Logan - Austin
2 - Boyd - Houston
Destination Table
ID - NAME - CITY
1 - Logan - Austin
2 - Boyd - Austin
merge into destination using sourceExample:
Source Table
ID - NAME - CITY
1 - Logan - Austin
2 - Boyd - Houston
Destination Table
ID - NAME - CITY
1 - Logan - Austin
2 - Boyd - Austin
on destination.id = source.id
when matched and (source.name != destination.name or source.city != destination.city) then
update set *
when not matched then insert *
The result of the merge should be the row with ID=2 gets updated in the destination but ID=1 does not since values would not change.
I would like to be able to do this in an effective way for tables that have 100+ columns.
Is creating an MD5 hash of the set of columns to potentially be updated a good option?
What other options do I have besides a giant list of not equals conditions?
Is creating an MD5 hash of the set of columns to potentially be updated a good option?
What other options do I have besides a giant list of not equals conditions?
The rows that actually get updated or inserted from the merge would have a timestamp on them that would indicate to downstream processes so they could update their datasets too. Passing millions of records along that didn't have any data changed will flood our API with too much data.
thanks,
Logan
Austin, TX

Tathagata Das
Jun 2, 2021, 1:07:42 AM6/2/21
to Logan Boyd, Delta Lake Users and Developers
Doing a hash of the columns seems like a viable option to me. However, you probably still have to put the full list of columns (except the timestamp column?) in the md5 hash function. That is probably easier to maintain than generating `x = x` for all columns.
Spark SQL does not support EXCEPT clause yet. I think it's not a SQL standard yet, only SQL Server supported it.
--
You received this message because you are subscribed to the Google Groups "Delta Lake Users and Developers" group.
To unsubscribe from this group and stop receiving emails from it, send an email to delta-users...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/delta-users/cecb9da1-aefb-40d1-a9da-15815b430d05n%40googlegroups.com.

Tomas Bartalos
Jun 2, 2021, 5:26:33 AM6/2/21
to Tathagata Das, Logan Boyd, Delta Lake Users and Developers
Hello,
I tried to solve the same problem - searching for changes in rows. Eventually I ended up generating `x = x` for all columns because I was afraid of hash collisions causing false positives.
Is the probability of collision so low that we can just ignore it ?
regards,
Tomas
st 2. 6. 2021 o 7:07 Tathagata Das <td...@databricks.com> napísal(a):
To view this discussion on the web visit https://groups.google.com/d/msgid/delta-users/CA%2BAHuKkNb-R_hCjG3ggZ5xxc6Uds50A6wcWOL36NmMKJTpYKOQ%40mail.gmail.com.

Gowtham Vudaigiri
Jun 2, 2021, 5:17:03 PM6/2/21
to Delta Lake Users and Developers
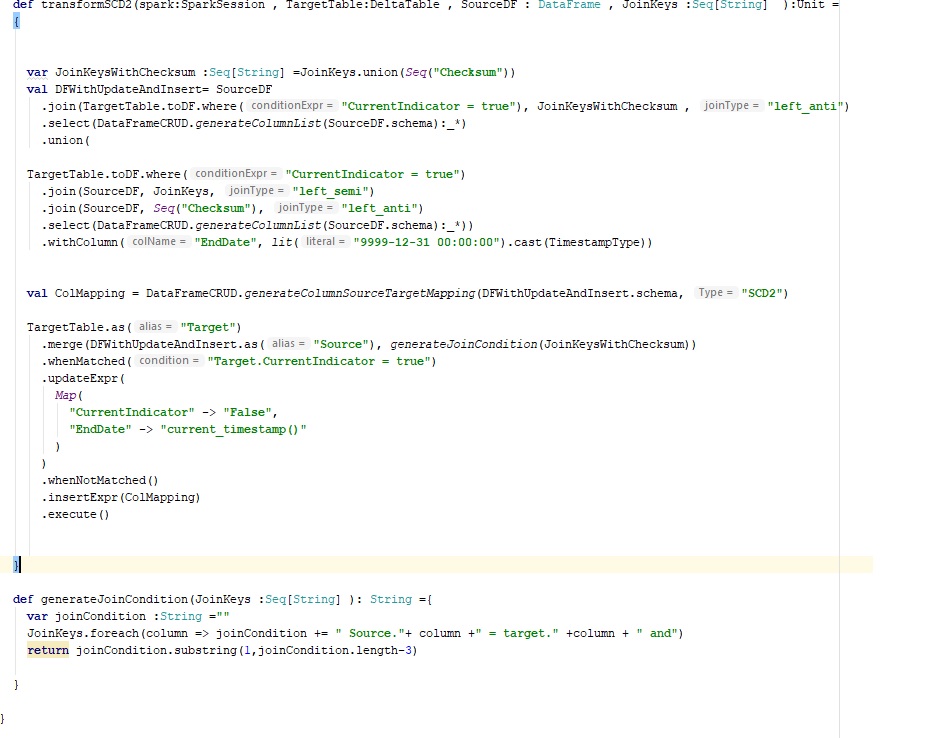
I have built a generic method to manage data in SCD2 type 2 format using Delta. Below is the method implementation. Use this if it helps.
Reply all
Reply to author
Forward
0 new messages