Debezium lag constantly increases on Oracle
96 views
Skip to first unread message

Petar Partlov
Feb 3, 2023, 10:04:03 AM2/3/23
to debezium
Hi all,
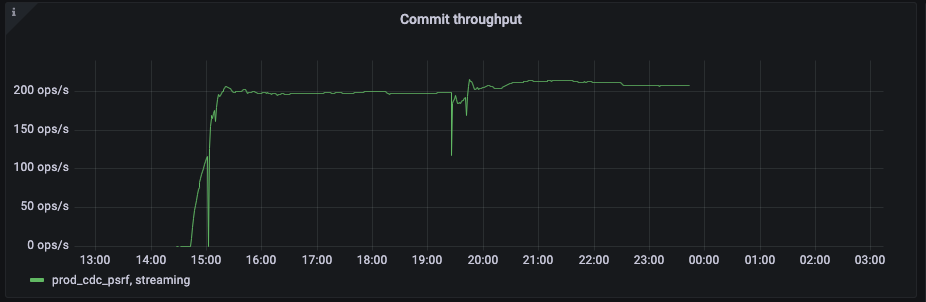
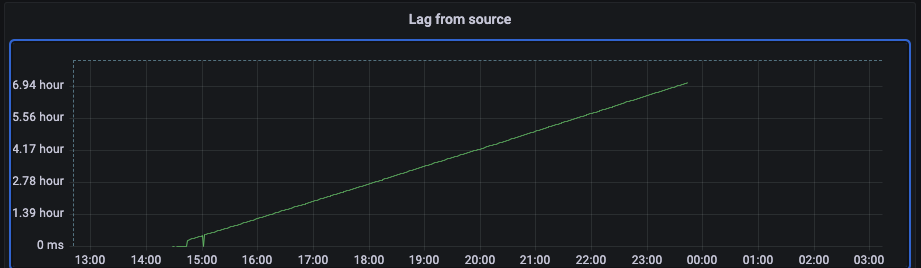
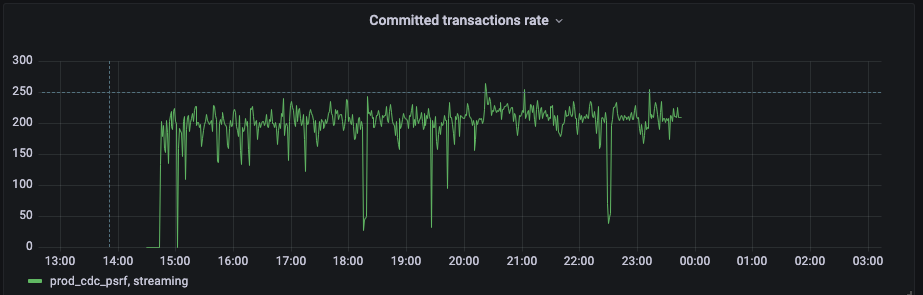
I already saw couple of questions with similar issues but most of them are quite old and I wanted to better understand if I would be able to use Debezium for this load or not.
So, first of all I'm using currently lates version of Debezium 2.1.2, Kafka is also newest 3.3.2. Oracle version is 19.
Here are relevant parts of configuration:
key.converter: io.confluent.connect.avro.AvroConverter
key.converter.schema.registry.url: "..."
value.converter: io.confluent.connect.avro.AvroConverter
value.converter.schema.registry.url: "..."
value.converter.schema.registry.url: "..."
table.include.list: "<61 tables>"
schema.history.internal.kafka.topic: "..."
schema.history.internal.kafka.bootstrap.servers: "..."
log.mining.username.exclude.list: SYS,SYSTEM
log.mining.batch.size.max: experimented with 100_000 to 1_000_000
log.mining.batch.size.min: experimented with 1000, 10000 and 100000
log.mining.batch.size.default: experimented with 100_000 to 500_000
snapshot.mode: schema_only
log.mining.strategy: online_catalog
transforms: unwrap
transforms.unwrap.type: io.debezium.transforms.ExtractNewRecordState
transforms.unwrap.drop.tombstones: true
transforms.unwrap.delete.handling.mode: rewrite
transforms.unwrap.add.fields: op,source.ts_ms
schema.history.internal.kafka.topic: "..."
schema.history.internal.kafka.bootstrap.servers: "..."
log.mining.username.exclude.list: SYS,SYSTEM
log.mining.batch.size.max: experimented with 100_000 to 1_000_000
log.mining.batch.size.min: experimented with 1000, 10000 and 100000
log.mining.batch.size.default: experimented with 100_000 to 500_000
snapshot.mode: schema_only
log.mining.strategy: online_catalog
transforms: unwrap
transforms.unwrap.type: io.debezium.transforms.ExtractNewRecordState
transforms.unwrap.drop.tombstones: true
transforms.unwrap.delete.handling.mode: rewrite
transforms.unwrap.add.fields: op,source.ts_ms
Here are some images of relevant metrics:
As you can see lag increases very quickly (basically it manages to consume about one third of events). Number of transactions on our server is about 800 per second and sometimes even 1K.
At this moment I exhausted my knowledge and configuration options so I'm reaching to you for some proposition or advice.
Thanks
Petar Partlov
Feb 3, 2023, 3:00:39 PM2/3/23
to debezium
One note, Debezium version is actually 2.0.0.
Petar Partlov
Feb 6, 2023, 4:02:28 AM2/6/23
to debezium
Hi all once again,
After some more investigation of code and adding more metrics I finally figured our what is main issue. Apparently i was missing to explicitly set query.fetch.size parameter and Oracle's default config of 10 is far of making Debezium usable in our use case.
My suggestion is to put some sensible default value here and not rely on Oracle's default value. Putting any normal value increase max throughput at least 100 times and I think that a lot of people miss to set this option.

Chris Cranford
Feb 6, 2023, 7:54:58 AM2/6/23
to debe...@googlegroups.com
Hi Petar -
I'm glad you've figured out the issue. I'm certainly not opposed to setting {{query.fetch.size}} to a value that is greater than 0. I've opened DBZ-6079 [1] as a task to work on this, with a suggestion to use a similar default that is used for {{snapshot.fetch.size}}, which should be far more reasonable. I think we may also want to review the documentation and see whether we may need to make a call-out on this setting as well.
Thanks for this gem!
Chris
[1]: https://issues.redhat.com/browse/DBZ-6079
I'm glad you've figured out the issue. I'm certainly not opposed to setting {{query.fetch.size}} to a value that is greater than 0. I've opened DBZ-6079 [1] as a task to work on this, with a suggestion to use a similar default that is used for {{snapshot.fetch.size}}, which should be far more reasonable. I think we may also want to review the documentation and see whether we may need to make a call-out on this setting as well.
Thanks for this gem!
Chris
[1]: https://issues.redhat.com/browse/DBZ-6079
--
You received this message because you are subscribed to the Google Groups "debezium" group.
To unsubscribe from this group and stop receiving emails from it, send an email to debezium+u...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/debezium/8137dc1c-be56-4af9-a625-53382df07a41n%40googlegroups.com.
Petar Partlov
Feb 6, 2023, 8:45:58 AM2/6/23
to debezium
Thanks Chris, that makes sense.
There is also one more thing I noticed when experimented with newer version of Debezium (2.1.2). At first it looks like it works slower than version 2.0.0 and I think the reason for that is that you moved filtering of V$LOGMNR_CONTENTS entries from database query to Java. This is sometimes an issue (like in our case) when we are actually interested in part of the schema and there are huge amount of changes in other tables we don't track. This leads to situation where we fetch huge amount of data from database to Debezium which we are not interested in, and Debezium spends far more time in I/O operations in this case.
This is just maybe think you should revisit and try to test this part again to check its performance.
Chris Cranford
Feb 6, 2023, 1:52:18 PM2/6/23
to debe...@googlegroups.com
Hi Petar -
This is great feedback, so let me first start my explaining my reasoning for this change.
First, as you may have noticed in the code, we used the REGEXP_LIKE operator previously in order to apply regex based predicates against the contents of V$LOGMNR_CONTENT. These predicates were based on the schema and table include/exclude configuration properties, which allowed us to target only the rows of interest based on your connector's configuration. However, it was identified through both community and customers that this approach did not perform as well as we would have liked, especially in situations where the include/exclude lists had a dozen or more tables or schemas or in database environments that had tens of thousands of tables.
Secondly, we want to get to a point where we finish & implement the changes needed for DBZ-3401 [1]. This issue centers around the notion that we will phase out the default log.mining.strategy "redo_in_catalog" mode and will instead utilize the "online_catalog" mode permanently. The goal with this change is that this avoids the need to write the data dictionary to the redo logs, which will mean that the frequency that archive logs are generated will go down substantially, and LogMiner's performance will increase per iteration because the dictionary data won't need to be parsed & loaded.
The main ongoing drawback with "online_catalog" is that it's schema evolution philosophy is very rigid, users must capture all changes for the table before applying the schema change, and then the schema change must be captured and handled by the connector before any further data changes occur. In effect, this means the data needs to be locked from user mutation, and then the schema change done in lock-step with the connector. This isn't ideal and isn't always viable for high availability environments.
Each redo entry stores the table's object id and version along with the column ids associated with the table at the time the table is mutated. LogMiner uses the data dictionary to resolve these table and column object ids back to their logical names. But if there is an inconsistency and "online_catalog" is used, the SQL cannot be reconstructed. Previously when using REGEXP_LIKE, these records would be omitted because LogMiner could populate the table name with "OBJ#xxxxxxx" rather than the logical table name because the name resolution failed and the REGEXP_LIKE predicate wouldn't match. By removing this predicate from the query, we are now able to get these rows but at the cost that we always read all redo entries and this paves the way for us to identify this use case, and perform the logic needed for DBZ-3401 where we manually resolve the table/column names ourselves.
That said, maybe there is a compromise here I hadn't considered.
At a minimum, we want to avoid the use of REGEXP_LIKE. But maybe there is world where we still read every START, COMMIT, ROLLBACK, and DDL operation, but perhaps we can use the table ids as a way to limit the records that get read related to DML operations. The comparison of the numeric value should be substantially faster than the REGEXP_LIKE and in theory should also be faster than if we built an IN-clause and NOT IN-clause based on the names of all tables that matched the include/exclude filters. If this is based on the table's object ids, then technically this wouldn't impact the future of DBZ-3401 at all and it might address your concerns around I/O.
I'm certainly open to other ideas or thoughts if anyone has any. What's your take on this?
Chris
This is great feedback, so let me first start my explaining my reasoning for this change.
First, as you may have noticed in the code, we used the REGEXP_LIKE operator previously in order to apply regex based predicates against the contents of V$LOGMNR_CONTENT. These predicates were based on the schema and table include/exclude configuration properties, which allowed us to target only the rows of interest based on your connector's configuration. However, it was identified through both community and customers that this approach did not perform as well as we would have liked, especially in situations where the include/exclude lists had a dozen or more tables or schemas or in database environments that had tens of thousands of tables.
Secondly, we want to get to a point where we finish & implement the changes needed for DBZ-3401 [1]. This issue centers around the notion that we will phase out the default log.mining.strategy "redo_in_catalog" mode and will instead utilize the "online_catalog" mode permanently. The goal with this change is that this avoids the need to write the data dictionary to the redo logs, which will mean that the frequency that archive logs are generated will go down substantially, and LogMiner's performance will increase per iteration because the dictionary data won't need to be parsed & loaded.
The main ongoing drawback with "online_catalog" is that it's schema evolution philosophy is very rigid, users must capture all changes for the table before applying the schema change, and then the schema change must be captured and handled by the connector before any further data changes occur. In effect, this means the data needs to be locked from user mutation, and then the schema change done in lock-step with the connector. This isn't ideal and isn't always viable for high availability environments.
Each redo entry stores the table's object id and version along with the column ids associated with the table at the time the table is mutated. LogMiner uses the data dictionary to resolve these table and column object ids back to their logical names. But if there is an inconsistency and "online_catalog" is used, the SQL cannot be reconstructed. Previously when using REGEXP_LIKE, these records would be omitted because LogMiner could populate the table name with "OBJ#xxxxxxx" rather than the logical table name because the name resolution failed and the REGEXP_LIKE predicate wouldn't match. By removing this predicate from the query, we are now able to get these rows but at the cost that we always read all redo entries and this paves the way for us to identify this use case, and perform the logic needed for DBZ-3401 where we manually resolve the table/column names ourselves.
That said, maybe there is a compromise here I hadn't considered.
At a minimum, we want to avoid the use of REGEXP_LIKE. But maybe there is world where we still read every START, COMMIT, ROLLBACK, and DDL operation, but perhaps we can use the table ids as a way to limit the records that get read related to DML operations. The comparison of the numeric value should be substantially faster than the REGEXP_LIKE and in theory should also be faster than if we built an IN-clause and NOT IN-clause based on the names of all tables that matched the include/exclude filters. If this is based on the table's object ids, then technically this wouldn't impact the future of DBZ-3401 at all and it might address your concerns around I/O.
I'm certainly open to other ideas or thoughts if anyone has any. What's your take on this?
Chris
To view this discussion on the web visit https://groups.google.com/d/msgid/debezium/d6022698-fe44-4257-bec2-5e1ce4733b62n%40googlegroups.com.

David Ridge
Feb 6, 2023, 7:40:47 PM2/6/23
to debezium
Hi Petar,
I'm very interested in this.
Can you please let me know what were the "sensible default values" used?
Thanks
Petar Partlov
Feb 7, 2023, 1:33:51 PM2/7/23
to debezium
Hi Chris,
Yes this solution seams reasonable. Regarding filtering I was aware of bad influence of REGEX so in our use case (as we basically put complete table names and not regex) I just changed Query builder to use IN clause. I gave version of 2.1.2 another try and it works good at this moment. I use this period to experiment as it will be much harder once it is in on production.
At this moment, however, I'm little afraid of fact that if for any reason (database issue, or Debezium fail) we create lag of more than 4 hours behind production Debezium can't catch up as querying log miner view lasts very long. I will try to see with my DBA if we can somehow improve this but in any case I will need some recovery procedure if that happens. I suppose that after some amount of archived files query just lasts to long.
As an example if lag is small (about half an hour) I have transaction throughput of 6k transactions per second. We have about 800 of them so this should be fin. But, if lag is for example 11 hours, transactions throughput drops under 100 per second which is basically less than database produces.
Petar Partlov
Feb 7, 2023, 1:36:01 PM2/7/23
to debezium
@David
I used 10K for query.fetch.size and it works OK. I think any value between 1K and 10K would be fine, but with value greater than 10K performance start being worse.
Chris Cranford
Feb 8, 2023, 8:52:01 AM2/8/23
to debe...@googlegroups.com
Hi Petar -
So I think if we aligned this query.fetch.size with snapshot.fetch.size, which defaults to 2000, that should be more than reasonable as a better default value than relying on the driver.
Thanks,
Chris
So I think if we aligned this query.fetch.size with snapshot.fetch.size, which defaults to 2000, that should be more than reasonable as a better default value than relying on the driver.
Thanks,
Chris
--
You received this message because you are subscribed to the Google Groups "debezium" group.
To unsubscribe from this group and stop receiving emails from it, send an email to debezium+u...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/debezium/ccc506b5-bf4a-42bb-af39-3b81f8976f2bn%40googlegroups.com.
Reply all
Reply to author
Forward
0 new messages