Adhoc Snapshot using signals for tables without primary key
306 views
Skip to first unread message

Mukesh Kumar
Mar 13, 2023, 3:32:18 AM3/13/23
to debezium
Hello,
I need to initiate Ad-Hoc snapshot for tables not having any primary key.
is it supported in Debezium Source connector ?
Regards
Mukesh
Mukesh Kumar
Mar 16, 2023, 2:18:55 AM3/16/23
to debe...@googlegroups.com
Hello
Any suggestions ?
--
You received this message because you are subscribed to the Google Groups "debezium" group.
To unsubscribe from this group and stop receiving emails from it, send an email to debezium+u...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/debezium/da3fa45b-484f-41b0-a6f4-cfbac3053095n%40googlegroups.com.

Nathan Smit
Mar 16, 2023, 2:27:22 AM3/16/23
to debezium
Hey there,
Do you have any more details? Which connector are you using? If your table has no primary key, do you have a collection of columns that could serve as a proxy for a primary key?
I currently have a situation like this in my Oracle source data. What I do is make use of the message.key.columns config to "simulate" a primary key based on multiple columns in my source data (see below). If you do this, the incremental ad hoc snapshot will run and you won't get that error about not having a primary key. You'll have to check the documentation though for your specific connector.
message.key.columns=DC.DC_CRANE_INSTRUC_CARTON_TRACK:CRANE_MOVEMENT_ID_NO,CRANE_SOURCE_MOVEMENT_ID_NO,COMPANY_NAME,PALLET_ID_NO,ORDER_NO
Mukesh Kumar
Mar 17, 2023, 2:35:55 AM3/17/23
to debe...@googlegroups.com
Thanks Nathan,
I am using the sqlServer source connector.
Few of my tables have columns that can serve as unique keys.
Few of my tables have columns that can serve as unique keys.
But there are still chances where tables do not have any unique column combinations - not sure how to handle that.
I will work in this direction.
I will work in this direction.
Thanks again for your help
Regards
Mukesh Kumar
To view this discussion on the web visit https://groups.google.com/d/msgid/debezium/76239ad9-9b8e-49e7-bc6c-cdbf8f76265an%40googlegroups.com.

Chris Cranford
Mar 17, 2023, 9:04:49 AM3/17/23
to debe...@googlegroups.com
Hi Nathan/Mukesh -
I would also take a look at the new "surrogate-key" feature for Incremental Snapshots added in 2.0.0.Alpha3.
I added a blurb about this in our recent release announcement [1].
Thanks,
Chris
[1]: https://debezium.io/blog/2023/03/08/debezium-2-2-alpha3-released/
I would also take a look at the new "surrogate-key" feature for Incremental Snapshots added in 2.0.0.Alpha3.
I added a blurb about this in our recent release announcement [1].
Thanks,
Chris
[1]: https://debezium.io/blog/2023/03/08/debezium-2-2-alpha3-released/
To view this discussion on the web visit https://groups.google.com/d/msgid/debezium/CAL65_gEN7ANGxZzdcztVwx%2B2gGXhi1vKkJ71q8G7GasDKMQa3w%40mail.gmail.com.
Nathan Smit
Mar 17, 2023, 10:42:51 AM3/17/23
to debezium
Hey Chris, wow, hot off the presses!
"You may ask, why does a table have no primary key, and we aren’t going to debate that here today" This is something I ask our source teams often!
I think this is cool, but seems less flexible to me than (in my case) using the message key columns. The only issue I've had on this (which I've mentioned elsewhere) is the handling of Nulls when doing the snapshot. I still think something like this could be really powerful if we had the ability to create computed columns (like a hash of all the columns for example). Although I assume you could do this with an SMT potentially and then use that as your surrogate key?
Chris Cranford
Mar 18, 2023, 2:11:50 PM3/18/23
to debe...@googlegroups.com
Hi Nathan -
So with regard to NULL handling, is it safe for me to assume you're referring to the idea of "NULLS [FIRST|LAST]" in the ORDER BY clause or is there something else about NULLs that are problematic?
Thanks,
Chris
So with regard to NULL handling, is it safe for me to assume you're referring to the idea of "NULLS [FIRST|LAST]" in the ORDER BY clause or is there something else about NULLs that are problematic?
Thanks,
Chris
To view this discussion on the web visit https://groups.google.com/d/msgid/debezium/4a88f45d-ccad-4073-83a6-c507907224e7n%40googlegroups.com.
Nathan Smit
Mar 27, 2023, 9:10:47 AM3/27/23
to debezium
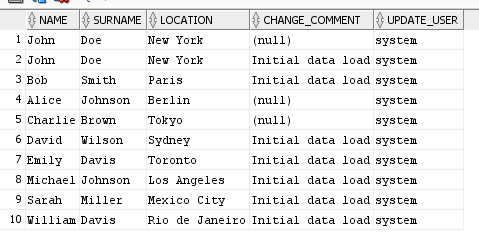
Hey Chris, it's something else. I have a simplified example to illustrate. I have a source table with ten rows. I do an incremental snapshot with chunks of 2 rows. The message key columns config is set to be every column of the table (table has no primary key). You'll see in the attached image that there is a row that is almost a duplicate but where there are different change comments (one is null). I've attached the sql queries that this generates.
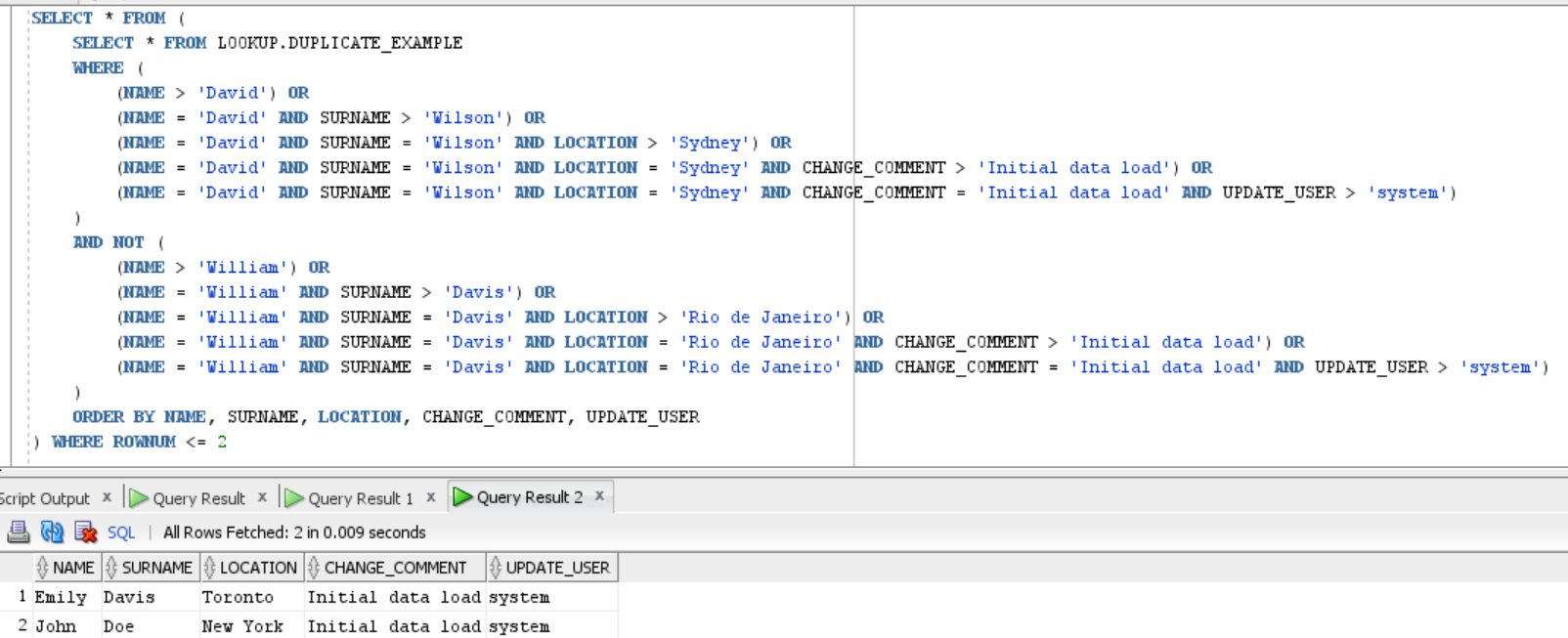
I've stitched together these queries and run them. You can see the third query returns one of my "almost-duplicate" rows, however the fourth one skips over my null entry. Basically if I change the query so that it instead does something like " (NAME = 'John' AND SURNAME = 'Doe' AND LOCATION = 'New York' AND COALESCE(CHANGE_COMMENT,'ZZZZZZ') > 'Initial data load') OR" then I get my row back i.e. it's testing on the null column and dropping the row because of that.
Interestingly, you previously pointed me to https://issues.redhat.com/browse/DBZ-4107 which seems to exist to solve this very problem (and I'm running 1.9.0 final, so shouldn't be an issue) but based on the generated queries it seems like I would always miss the columns that contain nulls as the query would need to do something like the below for my case but I don't see any logic for this in that pull request (I've only checked the oracle stuff).
{kind=link}
{kind=link}
{kind=link}
Reply all
Reply to author
Forward
0 new messages