After debezium ran for a while, SCN was close to a billion behind Oracle database

roarjpx
This is the configuration currently in use
log.mining.strategy:online_catalog
log.mining.continuous.mine:true
scan.startup.mode:latest-offset
log.mining.batch.size.min:150000

Chris Cranford
Could you please share your entire connector configuration, including the version of the connector you are running as well as the version of Oracle & whether this is a RAC installation.
Thanks
Chris
--
You received this message because you are subscribed to the Google Groups "debezium" group.
To unsubscribe from this group and stop receiving emails from it, send an email to debezium+u...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/debezium/90c15155-504a-4c6f-a85f-d5b0a99a9ae3n%40googlegroups.com.
roarjpx
Chris Cranford
You didn't define a "table.include.list" or a "schema.include.list" configuration option for the connector? Oracle has a ton of built-in tables and you really should be explicitly setting these include lists accordingly in the configuration or you're effectively capturing changes for the entire database which is wasteful and unnecessary. Do you notice an improvement if you correctly configure the connector with the explicit tables you want to capture?
Chris
To view this discussion on the web visit https://groups.google.com/d/msgid/debezium/182bb315-930f-4210-951d-009a181f3a00n%40googlegroups.com.
roarjpx
Oh, sorry, I thought you meant extra configuration, table.include.list and schema.include.list are both available. SchemaList is the user and tableList is the table. Currently there are only two tables in the tableList.
Complete configuration information is as follows
properties.setProperty("database.tablename.case.insensitive", "false");
properties.setProperty("log.mining.strategy", "online_catalog");
properties.setProperty("log.mining.continuous.mine", "true");
properties.setProperty("scan.startup.mode", "latest-offset");
properties.setProperty("log.mining.batch.size.max","200000");
properties.setProperty("log.mining.batch.size.min","150000");
DebeziumSourceFunction<String> sourceFunction = OracleSource.<String>builder().
hostname("")
.port()
.database("")
.username("")
.password("")
.schemaList("user")
.tableList("user.table,user.table")
.debeziumProperties(properties)
.deserializer(new orDeserializationSchema())
.startupOptions(StartupOptions.initial())
.build();
Chris Cranford
Do you get better performance if you remove "log.mining.continuous.mine" and let the connector manage the LogMIner session itself?
Chris
To view this discussion on the web visit https://groups.google.com/d/msgid/debezium/51280f6d-8840-4b0c-b85c-06db729028b1n%40googlegroups.com.
roarjpx
You can use the online mining mode without writing the data dictionary to the redo log, but this does not process DDL statements. In the production environment, the default policy reads logs slowly. Moreover, the default policy writes data dictionary information to the Redo log, which increases the log volume. In this case, you can add the following configuration items of Debezium. 'log. Mining,. The strategy' = 'online_catalog', 'log. Mining,. Continuous. Mime' = 'true'.
Chris Cranford
Their description is a bit misleading. What causes the connector not to track DDL changes and to avoid the log volume is the "log.mining.strategy=online_catalog" setting. The continuous mining option has no effect on this at all. And yes, setting this does toggle Oracle's continuous mining option, which we do not recommend and will be looking to remove in the future as it was only added for support on Oracle 12 since Oracle 19+ doesn't support it any longer.
As for reading real-time data, that shouldn't be an issue with a properly tuned environment. We have users using the connector in environments that generate hundreds of thousands SCNs per minute. As we don't test with the continuous mining option, I'm not sure if that is the reason for your issues, so if you could please remove it in your configuration that would be great.
Finally, can you explain precisely in detail what is your criteria for purging archive logs? Is this purge done using just the filesystem, RMAN, or a combination of both?
Chris
To view this discussion on the web visit https://groups.google.com/d/msgid/debezium/7b804ec7-abe6-4c3c-a7c0-16dc12258578n%40googlegroups.com.
roarjpx
- We have users using the connector in environments that generate hundreds of thousands SCNs per minute.
Chris Cranford
So technically, Oracle LogMiner can support that load but only if your redo logs are being sized efficiently. Can you please provide the output from the following SQL:
SELECT GROUP#, THREAD#, BYTES, MEMBERS, STATUS FROM V$LOG
I'd like to understand how many log groups, archiver threads, and log sizes and multi-plex set up your database is using with such a volume.
Thanks,
Chris
To view this discussion on the web visit https://groups.google.com/d/msgid/debezium/4dad625f-a815-449f-a47d-066a872bd11an%40googlegroups.com.
roarjpx
This is the data from the SQL query you provided
58 1 5368709120 1 INACTIVE
59 1 5368709120 1 INACTIVE
60 1 5368709120 1 CURRENT
61 1 5368709120 1 INACTIVE
62 2 5368709120 1 INACTIVE
63 2 5368709120 1 INACTIVE
64 2 5368709120 1 INACTIVE
65 2 5368709120 1 INACTIVE
66 2 5368709120 1 CURRENT
67 3 5368709120 1 INACTIVE
68 3 5368709120 1 INACTIVE
69 3 5368709120 1 INACTIVE
70 3 5368709120 1 INACTIVE
71 3 5368709120 1 CURRENT
72 4 5368709120 1 INACTIVE
73 4 5368709120 1 CURRENT
74 4 5368709120 1 INACTIVE
75 4 5368709120 1 INACTIVE
76 4 5368709120 1 INACTIVE
This is the data from another query
58 1 5368709120 1 INACTIVE
59 1 5368709120 1 INACTIVE
60 1 5368709120 1 ACTIVE
61 1 5368709120 1 CURRENT
62 2 5368709120 1 INACTIVE
63 2 5368709120 1 INACTIVE
64 2 5368709120 1 INACTIVE
65 2 5368709120 1 INACTIVE
66 2 5368709120 1 CURRENT
67 3 5368709120 1 INACTIVE
68 3 5368709120 1 INACTIVE
69 3 5368709120 1 INACTIVE
70 3 5368709120 1 INACTIVE
71 3 5368709120 1 CURRENT
72 4 5368709120 1 INACTIVE
73 4 5368709120 1 ACTIVE
74 4 5368709120 1 CURRENT
75 4 5368709120 1 INACTIVE
76 4 5368709120 1 INACTIVE
Chris Cranford
So using 4 log groups across 4 RAC nodes each at 5GB should be fine.
I would enable JMX metrics, if you don't have it enabled, and check whether the RemainingQueueCapacity is reaching 0 frequently. If it is, this means that the internal queue managed between Debezium and the Kafka Connect/Flink framework is the bottleneck. If that's the case you may need to adjust "max.batch.size" and "max.queue.size" accordingly. In short, if this queue's capacity reaches 0, this causes the reading of the LogMiner results to be blocked until space becomes available in the queue. Note, that the larger the queue, the more memory the queue will require on the JVM process.
I would also take a look at the NumberOfActiveTransactions metric. If this metric remains above 0 and the OffsetScn value does not change frequently, this is generally an indication of a long-running transaction. A long-running transaction can be severely bad for the connector because the oldest SCN for that transaction is where the connector must restart from in the event of a restart or failure. Until a transaction commits or rolls back, we can't advance that watermark. You can avoid this problem by configuring the "log.mining.transaction.retention.hours" option to a value greater than 0 so that long running transactions get discarded after a given time.
Regarding the removal of the logs, so far I haven't been able to determine from your description whether older logs are being prematurely removed. Can you please confirm that if you remove old archive logs at midnight daily and a redo log rolls to archive immediately prior to, lets say 11:55pm, will that log remain on the server at least until the next night's removal or will it be removed that same night? If it is removed that same night, then that can be problematic and should never be done. It can take several seconds for logs of your size to be mined and processed and a new mining session to advance on log switches. I just want to be sure we can't prematurely removing logs before the connector has a chance to read them.
Finally, I would urge you to upgrade to 1.9.5 so you get the latest enhancements & performance improvements.
Hope that helps.
Chris
To view this discussion on the web visit https://groups.google.com/d/msgid/debezium/fc2f02bf-6a92-4440-acac-72b797acfdean%40googlegroups.com.
roarjpx
Hi,
Ok, we follow-up to enable the JMX RemainingQueueCapacity and NumberOfActiveTransactions index observation you said. When I asked the DBA about the log deletion, I was told that it would be reserved for 24 hours and would not be deleted immediately. The deletion mechanism is such as the current 3pm will be retained until 3pm yesterday, arrived at 4pm today before 4pm yesterday will be deleted, that is to delete the archived logs between 3pm and 4pm yesterday.
Upgrade DeBezium version to 1.9.5, we need to check if Flink has the corresponding version, after all, we rely on Flink framework.
In addition the following the TXT is to remove the log.mining.continuous.mine running log information, after this configuration, a day after operation with database SCN gap is three hundred million, two days is six hundred million, the third day is stopped. The viewing information is due to the deletion of the archive log
Moreover, the 18th is still reading the archived log information of the 17th, which is a growing gap. See the log file below for more information
Chris Cranford
Thanks,
Chris
To view this discussion on the web visit https://groups.google.com/d/msgid/debezium/2102eccd-c38b-4ecb-8f18-6ee086047123n%40googlegroups.com.
roarjpx
Hi
The log information has been sent to you separately. This is part of the log I captured from the log. Do you want to run all the logs for several hours? Because the whole log is too large. If you want the whole thing, I'll be more prepared for you next time
Chris Cranford
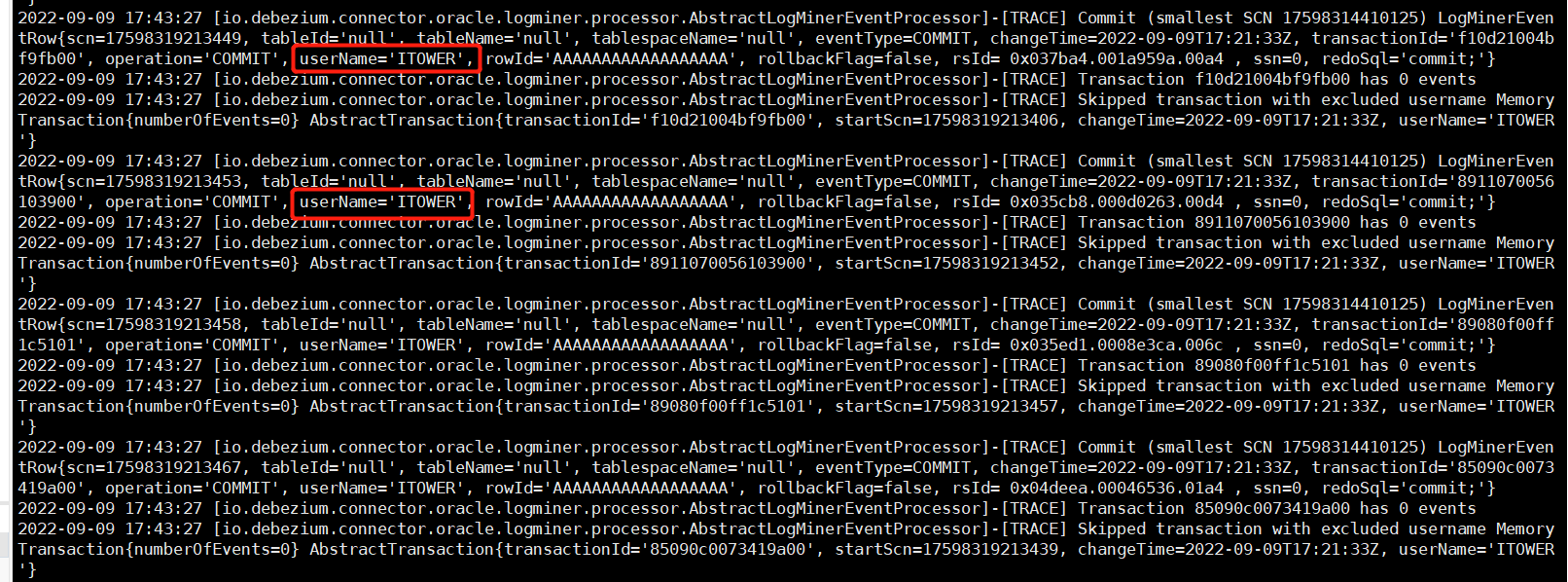
So I took a look at the logs and from what I could gather, specifically from the JMX metrics dumped when the connector was stopped at 2022-08-24 17:28:41, the connector had processed 11.8 million rows of data during its runtime, of which had been gathered from a total of 1,305 mining queries. What is interesting is that of that 11.8 million rows, only 25,317 of them were related to DML events that the connector was interested in. Where most of the time spent is fetching the results, the total time spent getting the results from Oracle amounted to 6 hours and 23 minutes.
I also looked specifically at the COMMIT records captured and in the logs I found that you had 1,354,743 transaction commits done by ITOWER and another 81,886 by other users. Is it possible specific transactions could be excluded based on users to reduce the data set? My concern is that the connector is mining millions of rows but of those millions of rows, you only have 25k of them found to be of interest. I'm wondering whether we can reduce that data set because where the majority of your time being spent is reading and fetching rows that aren't of interest to the connector in the first place.
Does that make sense?
Chris
To view this discussion on the web visit https://groups.google.com/d/msgid/debezium/8bfc8ea2-7a98-4043-bea6-906aea480777n%40googlegroups.com.
roarjpx
Hi,
I have understood the problem you mentioned. We just started to speculate that the reason for the problem is the same. We have a lot of users in our database, and we need a small amount of data. The amount of data collected is too large because other users are constantly operating and we don't need a lot of that data.
Would adding DeBezium configuration information solve your problem of reducing data collection based on user exclusion of specific transactions? I don't see that DeBezium has any configuration information about it. Do you want us to start from the database? Split this user out of the current database?
If we can solve the problem of mining only specific users' information, then we won't be mining millions of rows and only a few of them are relevant to us.
Chris Cranford
There are a few ways to exclude bits from the mining session.
schema.exclude.list
This allows you to set a list of schemas / tablespaces that are to be excluded. It cannot be used in conjunction with schema.include.list. This is great for restricting the DML data set; however, this setting will not exclude non-DML events such as BEGIN, COMMIT, and ROLLBACK events, which seems to be a higher percentage of what we're gathering based on the metrics dump. But, if you aren't specifying an include list and you have schemas that you know you aren't interested in, this could still help reduce the data set if other schemas / tablespaces are manipulated that you aren't interested in.
log.mining.username.exclude.list
This option allows you to specify a comma-separated list of database usernames that you would like to exclude from being mined. This is extremely helpful because BEGIN, COMMIT, and ROLLBACK are tagged by the user who performed those operations. So if you know explicitly that you don't care about transactions created by the ITOWER for example, adding that name in upper-case to this comma-separated list will exclude a vast majority of the rows I mentioned earlier. Unfortunately, this option isn't available on the version I believe you're using, so you will need to upgrade to the latest release to get access to this feature.
I'd also like to point out that by upgrading, you will gain some better performance and we've have improved how we interact with LogMiner and how we utilize memory. If you can upgrade, I suggest you do so.
Thanks,
Chris
To view this discussion on the web visit https://groups.google.com/d/msgid/debezium/9cf91292-f27e-4301-baec-b4ed3b51c550n%40googlegroups.com.
roarjpx
Hi
The first of the two configurations you mentioned exists in 1.5, and the second is only available in 1.9, so we are trying to upgrade to 1.9.5.
Upgrade process see flink-connector-debezium/version 2.2.1 and debezium1.9.5 version are not compatible, the debezium1.9.5 DatabaseHistory.StoreOnlyMonitoredTables the method has been removed However, Flink is still using this method, which prevents further attempts. We are communicating with Flink. I think the next test can be carried out soon
Chris Cranford
Yes starting in Debezium 1.6, "storeOnlyMonitoredTables" was replaced with "storeOnlyCapturedTables". Can you point me to the location in Flink where this is being used? From what I can tell in their repository, they have no reference to this method, so perhaps the issue is actually one of where you have mixed versions of Debezium on the classpath instead?
Chris
To view this discussion on the web visit https://groups.google.com/d/msgid/debezium/7c8e7457-5d06-4f92-b3fb-5d9f36eff10fn%40googlegroups.com.
roarjpx
This method has been modified in the Github Master branch, but remains in the release-2.2 branch, and in the Maven repository in version 2.2.1.
We noticed that they modified the master branch last month and the release-2.2 branch ten months ago.
The last date of version 2.2.1 in Maven repository is also in April, and Flink should not be caused by the new release version.
Github flink Site
https://github.com/ververica/flink-cdc-connectors/tree/master
Maven Repository Address
https://mvnrepository.com/artifact/com.ververica/flink-connector-debezium
Chris Cranford
In any event, it does look like there is already an upgrade PR filed, https://github.com/ververica/flink-cdc-connectors/pull/1236. Hopefully they along with the contributor can work through the kinks in short order.
Chris
To view this discussion on the web visit https://groups.google.com/d/msgid/debezium/6e2f17f3-5bce-4fb2-980e-311880e80862n%40googlegroups.com.
roarjpx
Chris Cranford
So I had thought we actually implemented the user-exclusion at the database-level, but it appears this was added, the exclusion only takes place in the runtime code, which means those redo entries will be read regardless. I really don't have an answer as to why we elected to do this filtering in code rather than in the database LogMiner query, so unfortunately at the moment, these records will always at least be read. Could you raise a Jira issue to move this logic to the database query?
Lastly the differences between Debezium for Oracle 1.3 and 1.9.5 is pretty massive. The reason that 1.3 doesn't work this way is that it wasn't aligned with the behavior of the other connectors. All of our relational connectors except PostgreSQL that use a database history topic always capture the table structure for all tables in the database by default, unless that table is part of the built-in schema exclude lists, discussed here [1]. So the difference in behavior you see between these two versions is intentional and the behavior observed in the older version is incorrect.
Hope that answers your questions,
Chris
[1]: https://debezium.io/documentation/reference/stable/connectors/oracle.html#schemas-that-the-debezium-oracle-connector-excludes-when-capturing-change-events
To view this discussion on the web visit https://groups.google.com/d/msgid/debezium/bccf6aac-38ff-4b1e-9522-a16deb0ebdfcn%40googlegroups.com.
roarjpx
Is that what you said about Jira https://issues.redhat.com/projects/DBZ/issues/DBZ-5491?filter=allopenissues.
We had a problem when we registered the account, and we will talk about Jira after we register it.
During this period, we performed two mining operations, but each time the error message "No more data to read from socket" appeared, and our DBA had No database operation
And Flnik restarts with the message "Failed to retrieve mode history", which I can see appears in the DeBezium package.
Chris Cranford
So "No more data to read from socket" is a generic TNS error and it generally indicates that Oracle aborted the process. The best way to determine why Oracle aborted the process is to look inside the database alert log and at the trace files that are written to the admin dump directories on the database server at the timestamp when the connector failed. These two files should provide you with details as to why the database server elected to abort the process.
I'm not a Flink expert here, but from what I can tell from the FlinkDatabaseSchemaHistory and FlinkOffsetBackingStore implementations, these rely on using purely in-memory collections to store these values. This would mean that if the connector is stopped due to any reason, manual or a failure, this in-memory data would be lost. Is this intended?
In any event, the Flink error isn't Debezium related, but it's specific to the Flink implementation and how their framework handles restarting a connector after a failure and the fact the database history entry was apparently removed from the in-memory history storage when the failure occurred and the connector restarted.
Chris
To view this discussion on the web visit https://groups.google.com/d/msgid/debezium/3f162ef0-fcb0-4d22-bd2a-1deba3521df5n%40googlegroups.com.