Example(s) of "Large" dataset file in Harvard's DV?

Sherry Lake

Philip Durbin
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-commu...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/a80c3575-0fd8-4db3-a24a-a86214d4cfefn%40googlegroups.com.
--
Software Developer for http://dataverse.org
http://www.iq.harvard.edu/people/philip-durbin
Sherry Lake
Philip Durbin
- Upload a small placeholder file
- Look up the placeholder file info in db
- Directly upload the large file to a front end machine
- Use amazon command line utility to copy large file to location where placeholder file is
- Update db info (md5, contenttype, filesize) to match large file
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/80e5a566-6b0e-4c03-82ae-b387951dbb91n%40googlegroups.com.
Sherry Lake

Don Sizemore
then calling http://guides.dataverse.org/en/latest/api/native-api.html#add-a-file-to-a-dataset from there.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/04b6251b-9c32-4a3f-9f63-b035dc78f0ddn%40googlegroups.com.
Sherry Lake
You received this message because you are subscribed to a topic in the Google Groups "Dataverse Users Community" group.
To unsubscribe from this topic, visit https://groups.google.com/d/topic/dataverse-community/yXDpdg-thqw/unsubscribe.
To unsubscribe from this group and all its topics, send an email to dataverse-commu...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/CAPfMOaxmzC%3D839S_i51OGPB5B-rOCwAFmXL-_avHmj%2Be6%3Ddb7g%40mail.gmail.com.
Don Sizemore
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/CADL9p-XU67Cxv%3D1%2Bb_2avES8dFLHA_hwiA5BMsivFfEqE_2wVQ%40mail.gmail.com.
Philip Durbin
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/CAPfMOax3XX_heoeJ69CSF_cjB8R6ees81GwpWy%2BSm7XT4rtfrA%40mail.gmail.com.

Philipp at UiT
Sherry Lake
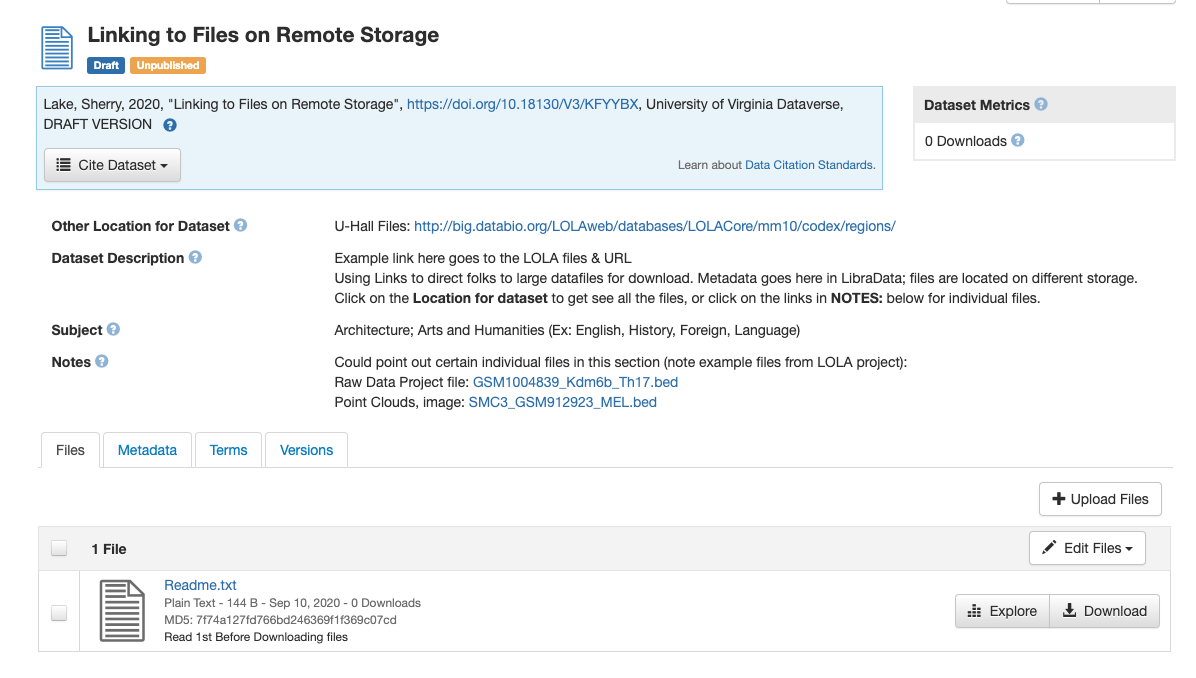

{kind=link}
James Myers
Philipp,
(All – please add/edit/comment – as I mentioned I’d like to get this type of guidance organized in a wiki or the guides, so any additional info you have is helpful)
I think the current options for something of that size are:
1) Deal with timeouts, and the needs for temporary storage space
2) Upload a small placeholder file and then manually swap the file and update the database entries
3) Use S3 on minio and use direct upload – this is still a single part upload but the only timeouts would be those for the S3 connection (you can’t use AWS S3– it has a limit of 5 GB for single part uploads which is what is currently implemented for direct uploads in Dataverse)
4) Use a link (per Sherry’s email)
5) Setup rsync/Data Capture Module (as discussed in http://guides.dataverse.org/en/latest/developers/big-data-support.html)
Things that are in the works:
· ~v5.1 – multipart direct S3 uploads: The UI and DVUploader are both capable of sending a large file to the S3 server in multiple parts which allows files up to a theoretical limit of 5TB. The part size can be adjusted so the site admin can shift that to limit the time required for each part. DVUploader has some limited retry capabilities if some of the parts fail.
· Scholar’s Portal is working on a Globus integration that provides dual access by S3 and Globus to an underlying store.
· Gerrick Teague, working for Kansas State University is developing Synapse, a different take on Globus integration that would use Globus for transfer and then push the file to Dataverse locally (perhaps automating the idea in option 2) above)
· UNC/Odum’s trusted remote data storage may also be able to address large data since it never transfers the file to Dataverse at all
For downloads, options 1-3 above only support a normal, single part download, with any S3 store also supporting direct download from S3 if configured (potentially faster if the connection to AWS/the S3 store is faster than to Dataverse itself). Using a link could potentially refer to a site that has alternate download methods. I think the rsync mechanism can be used in both directions.
For things in the works –
· With S3, it should be possible to do multipart downloads as well as multipart uploads. I haven’t looked into that yet. Nominally breaking into parts does three things – limits the time for a given part, enables restarts – a failure part way through only affects some parts of the file so one doesn’t have to restart the download from the beginning, and it allows for parts to be downloaded in parallel which can help use more of the available bandwidth. (This is one of the ways Globus gets more performance – parallel download of multiple file parts.)
· Of the Globus options, I think Scholar’s Portal’s design maintains Globus access for downloads. I’m not sure if Synapse addresses that.
· The trusted remote data store may also be able to support non-HTTP download methods.
-- Jim
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/d90469fa-6a3d-4e3d-a08a-2edb79af03f0n%40googlegroups.com.
Philipp at UiT
Looking forward to solutions like Globus and TRSA!