Support for NetCDF and HDF5 in Dataverse (geospatial contexts and more)

Philip Durbin
We are kicking off a project to support the file formats NetCDF and HDF5 in Dataverse (probably in geospatial contexts, at first) and would love to get ideas from YOU!
NetCDF seems to be used in climate research, meteorology, and GIS, to name a few.
HDF5 is used in astronomy, computational fluid dynamics, earth sciences, engineering, finance, genomics, medicine, and physics (according to the HDF5 website).
On Friday we conducted our first interview with a researcher who uses NetCDF, and we have a lead on a researcher who uses HDF5. Interviews are important because we'd like to make sure we're building the right thing! One way you can help is finding more researchers for us to interview.
We're pretty sure there will be some sort of geospatial angle to this project. For a NetCDF file containing climate data, for example, we're hoping there's a way to extract an image of a map with data on temperature, precipitation, etc. that we could use as a thumbnail for the file in Dataverse.
Perhap for either format we can extract metadata to populate part of the geospatial metadata block (at the dataset level) or create a GeoJSON file that can placed next to the original file and loaded into the new GeoJSON viewer for Dataverse.
These are just some ideas we've been kicking around. The project is just getting started and we'd like to invite you to join us and participate.
Ana and I plan to meet weekly on Zoom and have decided that these will be open meetings that others are welcome to join. It's likely we'll record them in case people want to catch up. Speaking of which, if you're interested in notes from meetings so far:
- 2022-10-03 meeting: https://docs.google.com/document/d/1RB_3YlY-6nNw_6QZ5pPe8R-6pIWJmXCpD1fsDbXPMt0/edit?usp=sharing
- 2022-10-25 meeting: https://docs.google.com/document/d/1zSf6SkMLOJ0h7clc6jM8m0CtvHN4w22Pm_qg0KX356o/edit?usp=sharing
- 2022-10-26 meeting: https://docs.google.com/document/d/1azN_uIc3f5MNP7eHm_gvvSfJ-4wrGjLknm5kOZ2fffE/edit?usp=sharing
Our next meeting is about 12 hours from now, 10am Monday, Boston time. I put a repeating entry with the Zoom link and password in the community calendar: https://calendar.google.com/calendar/embed?src=c_udn4tonm401kgjjre4jl4ja0cs%40group.calendar.google.com&ctz=America%2FNew_York
Some questions to ponder:
Do you know of any work already done in this area?
What is the state of the art in FAIR geospatial data? What tools do you use? Are there any community meetings?
We appreciate any information and feedback from you!
Thanks!
Phil Durbin and Ana Trisovic
p.s. Thank you to the NIH for the funding! You can see grant numbers and descriptions of aims (as well as various notes and screenshots) at https://github.com/IQSS/dataverse/issues/9053
--
Software Developer for http://dataverse.org
http://www.iq.harvard.edu/people/philip-durbin
Philip Durbin
Philip Durbin
Hello Dataverse enthusiasts!
Hierarchical data (NetCDF and HDF5)
Hierarchical data (NetCDF and HDF5)
Current State:
Harvard Dataverse, among other Dataverse installations, aims to be a general-purpose data repository, which means that it hosts a variety of research data from a range of scientific disciplines. Given that different data file formats are used in different disciplines, Dataverse needs to provide support for these data through adequate file detection and domain-specific metadata capture (see already supported schemas on GitHub or Google Sheet).
A good example of domain-specific data support in Dataverse is enabled for astronomy and astrophysics. FITS is a data format designed for astronomical data, which also stores metadata information about the origin of the data. It is the most commonly used file format in astronomy and is supported in Dataverse with automatic file detection, domain-specific metadata block and automatically populating metadata. In particular, when the “Astronomy and Astrophysics” metadata block is enabled, Dataverse automatically extracts information from the FITS file and populates the block as shown in Fig. 1.
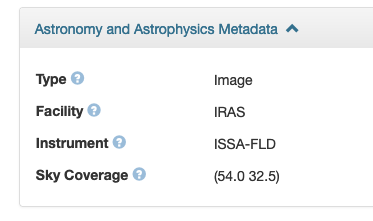
Fig. 1: Astronomy and Astrophysics Metadata block.
The Network Common Data Form (NetCDF) and Hierarchical Data Format version 5 (HDF5) are specialized file formats commonly used to store data in earth and environment sciences, including climate, weather, exposure and oceanography data. Similar to the FITS file format, NetCDF and HDF5 often store metadata about the measurement, including (but not limited to) variable names, units, geographic coordinates, creators’ names, emails and affiliations. However, as this metadata is embedded in the file, it is only visible when the file is downloaded and opened.
Dataverse already offers some support for data from earth and environmental sciences. In particular, it offers a geospatial metadata block (Fig. 2), which a user can enable before depositing data. However, the metadata block needs to be manually filled out by the user.
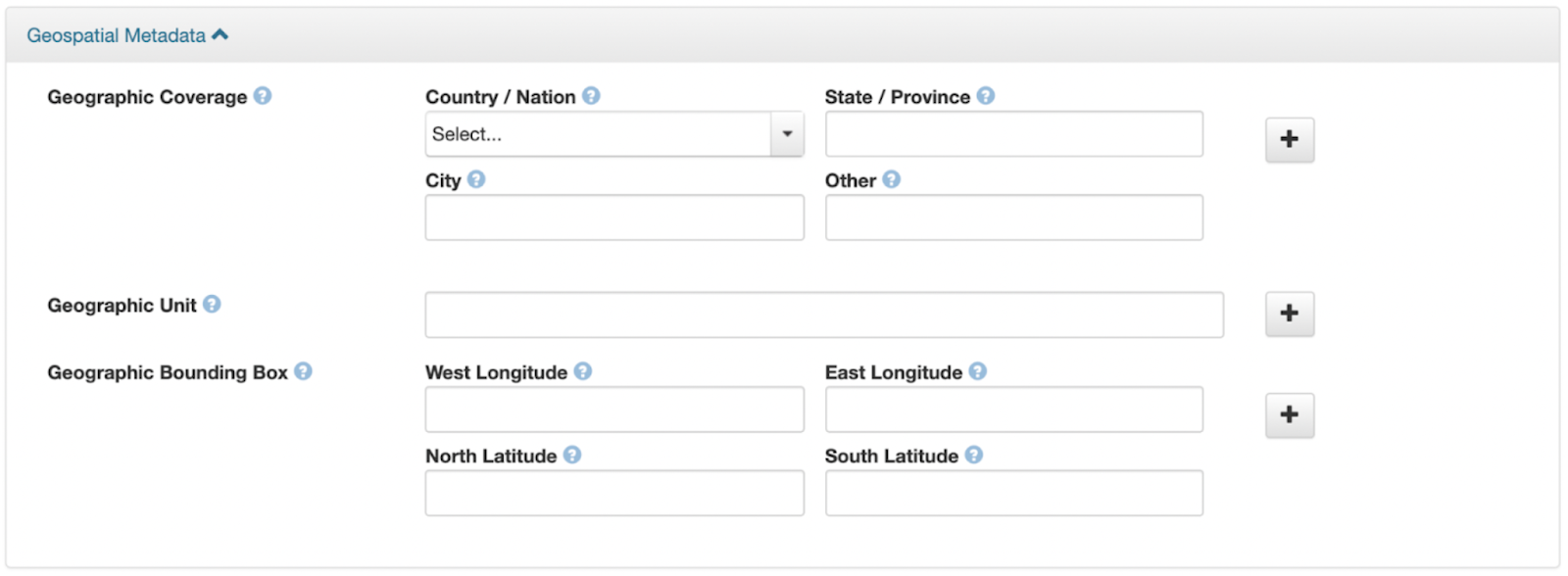
Fig. 2: Geospatial metadata block in Dataverse
Currently, the Dataverse software does not have specific support for NetCDF and HDF5 files. Inspired by the existing support for the FITS file format, this technical design document outlines new developments to better support these file formats.
The proposed work is funded by an NIH grant (see short description) and is primarily carried out by Ana Trisovic and Phil Durbin.
Proposal:
Summary:
We propose the following developments to the Dataverse software to better support NetCDF/HDF5 data and geospatial data in general:
File detection and automatic extraction of the embedded metadata at file upload.
Facilitating visibility and display of extracted metadata in Dataverse.
Better dataset documentation through domain-specific metadata.
Changes:
1. File detection for NetCDF and HDF5 files and automatic extraction of the embedded metadata at file upload. When the files are detected in Dataverse, an appropriate MIME type is assigned to them. Next, we use the Unidata netCDF-Java library to extract embedded metadata from the file.
The embedded metadata can be presented as free-form key-value pairs (known as attributes) with optional conventions that are followed within disciplines that do not necessarily match the standard and adopted metadata schemas used by Dataverse. For this reason, is it not possible to blindly “map” the extracted metadata into the geospatial metadata block (or any other metadata block). As a result, the extracted metadata is stored in the dataset as an auxiliary file of the original file.
The extracted metadata is formatted in XML format (other formats like JSON, GeoJSON, or text can also be supported) as an auxiliary file and automatically added to the dataset at upload.
The change is documented in the following GitHub issues:
2. Facilitating visibility and display of extracted metadata in Dataverse. The extracted metadata is saved as an XML auxiliary file, which can be viewed directly from the Dataverse interface, as shown in Fig. 3.
In cases where metadata extraction fails, the auxiliary file won’t be saved and the “eyeball” preview button won’t be available, but the file can still be downloaded as normal.


Fig. 3: Previewing the extracted metadata in XML by clicking on the preview “eyeball”.
The change is documented in the following GitHub issues:
3. Better dataset documentation through domain-specific metadata. Dataverse already supports a number of geospatial metadata fields as an independent block (see Fig. 2). As part of meeting this goal, we consider two changes: first, automatically populating the geospatial metadata block (inspired by the similar support for the FITS data format), and second, adding new standard metadata fields to improve the documentation of the dataset.
The metadata fields such as geographicUnit or geographicBoundingBox could be automatically populated from the extracted metadata below. To enable this, we consider using GDAL software or the netCDF-Java library mentioned above.
NC_GLOBAL#geospatial_lat_max=90
NC_GLOBAL#geospatial_lat_min=-90
NC_GLOBAL#geospatial_lat_resolution=1.25
NC_GLOBAL#geospatial_lat_units=degrees
NC_GLOBAL#geospatial_lon_max=360
NC_GLOBAL#geospatial_lon_min=0
NC_GLOBAL#geospatial_lon_resolution=1.875
NC_GLOBAL#geospatial_lon_units=degrees
NC_GLOBAL#Metadata_Conventions=Unidata Dataset Discovery v1.0,CF Discrete Sampling Geometries Conventions
Additionally, we consider adding the following geospatial metadata fields:
The change is documented in the following GitHub issues:
Optional developments include:
4. Automatically enabling a metadata block when FITS/NetCDF/HDF5 files are detected. While domain-specific metadata is valuable for better documentation of research data and adherence to the FAIR principles, from the examples below, we see that it is rarely used in practice.
https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/9ZSHYB
https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/L5WNU4
https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/E0HLON
https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/WH9OQR
https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/BKWJAI
This is because the domain-specific metadata blocks need to be manually enabled (as described here). As part of this change, we are considering automatically enabling the domain-specific metadata block (if permissions allow) when FITS/NetCDF/HDF5 files are detected, which would be automatically populated with the embedded metadata, if it can be extracted. In the case of not enough permission, the user could be prompted to reach out to an admin who can help.
The change is documented in the following GitHub issues:
GITHUB ISSUE TBD
Benefits:
General benefits include:
Meeting the research community's needs by supporting free and open source file formats (NetCDF and HDF5), which are popular in many scientific fields.
Improved transparency, findability and reuse of the data by displaying extracted metadata, thus avoiding the need for a user to retrieve and open the file locally (with specialized software) just to understand what it stores.
The new feature of automatically creating auxiliary files can be used for future developments and integrations in Dataverse (i.e., provenance, runtime environment).
Automatically populating metadata and new metadata fields would benefit:
Automatically extracting and populating metadata would alleviate the burden of the data depositor and minimize human error in file documentation.
The geographicBoundingBox metadata field, which can be automatically populated, will be used by Dataverse geospatial search, which looks for datasets based on a geographic point and radius (see documentation, technical design doc, and the GitHub thread).
Limitations
Based on our ongoing discussions, we recognize the following limitations:
Automatically extracting metadata will not be possible in all cases, as not all files will have metadata.
We experimented with extracting or generating a figure from NetCDF/HDF5 files and setting it as a thumbnail, however, it might be inverted (flipped), misleading or in other ways, unusable.
We considered generating new metadata from the variables available in the file, but it is common practice to use numerical “flags” in the geospatial data to capture information such as “recording device malfunction”, which would make generated information such as mean and standard deviation inaccurate. We plan instead to promote the use of specific tools more tailored to analyzing the files in a containerized environment, such as Binder, launched from Dataverse. We may provide some documentation and guidance in this area.
Integration with a THREDDS or OPeNDAP server is currently out of scope.
Earlier Discussion:
As part of this effort, we organized additional weekly open-to-all Dataverse community meetings on Mondays at 10 AM ET. All meeting notes are publicly available. Particularly interesting ideas are recorded in the Ideas Google Document.
The project was introduced in the Dataverse Community News post.
Use cases:
This work could be useful in the following use cases:
Geospatial data in Dataverse and the integration with GeoBlackLight (see presentations by Marc McGee, Maura Carbone, Kristial Allen, Jamie Jamison and Paul Dante)
Use cases evident by using a variety of NetCDF/HDF5 data from these examples:
Surface PM2.5: https://sites.wustl.edu/acag/datasets/surface-pm2-5/#V5.GL.03
GridMET data: https://www.northwestknowledge.net/metdata/data/