Cucumber - Enterprise Level
214 views
Skip to first unread message

Peter Wilson
Nov 19, 2014, 6:50:37 PM11/19/14
to cu...@googlegroups.com
Hi,
We've been using cucumber for about 6 months now and have found it very beneficial.
We're now looking to take it to a larger scale, with tens of thousands of tests and need a better test, infrastructure and data management system.
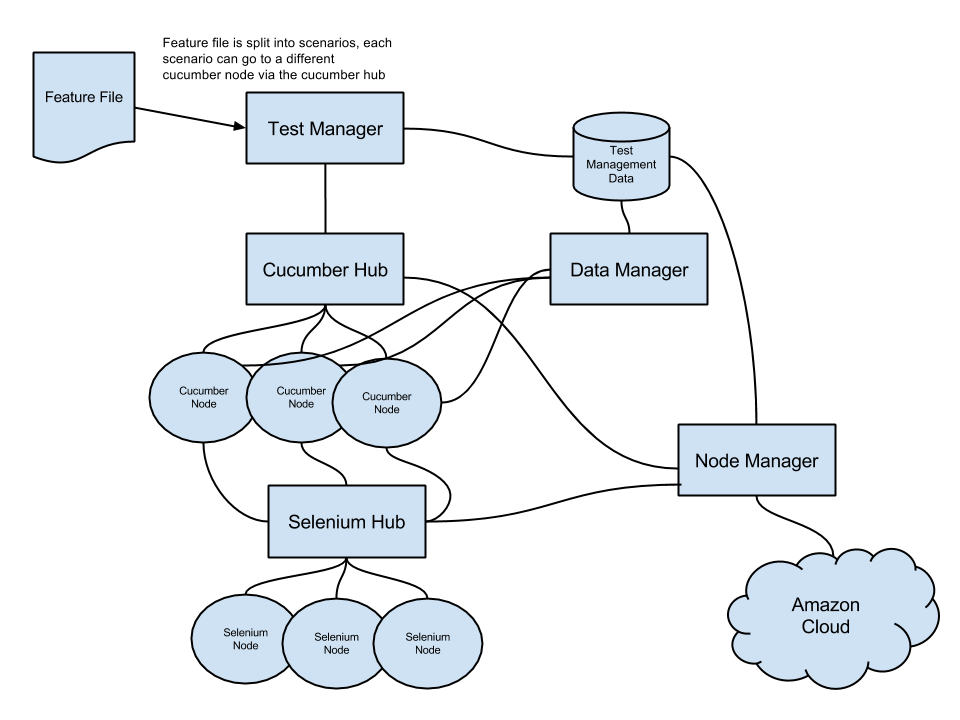
I've put together a high level mud map of what I am thinking and would really value feedback from the group. For example, has this already been done, or thought about and discarded for some reason.
To summarize:
1. Feature file goes into the test manager (a server of some sort) which chops up the scenarios (being aware of the background) and farms it out to different cucumber nodes. It stores results of each execution of each step in the test management DB, along with how long each step takes and what test data it required
2. The Cucumber Hub is like the Selenium Hub. Cucumber Nodes register with it and advertise test functions that it supports
3. The Cucumber Node is a cucumber file (step definition and on, not the Gherkin) turned into a service. A scenarios is passed to the node, the node executes and returns the result
4. The Data Manager looks after test data for different environments. It tracks daily usage and individual test usage and tries to create the necessary test data predictively ahead of time. The cucumber node will call the data manager as part of any data "given"
5. The Selenium hub we already know about
6. The Node Manager monitors the hubs looking at utilization levels and starts new cucumber and selenium nodes in a cloud service (such as Amazon) as required.
Another important piece that I am heading towards here is using this model for performance testing. This would reduce the cost of performance testing because no expensive tools or specialized scripts are required. It would also mean performance testing can be done as soon as the functional scripts are complete, which means it can be done earlier. One set of scripts reduces maintenance costs as well.
Having detailed information about scenario and step run times and data requirements would make performance testing pretty easy to setup too.
That's it.
Cheers
Peter

Paolo Ambrosio
Nov 20, 2014, 2:42:49 AM11/20/14
to cu...@googlegroups.com
On Wed, Nov 19, 2014 at 11:50 PM, Peter Wilson <peter....@gmail.com> wrote:
Hi,We've been using cucumber for about 6 months now and have found it very beneficial.We're now looking to take it to a larger scale, with tens of thousands of tests and need a better test, infrastructure and data management system.
I would be really scared working on such a monolithic software that requires tens of thousands of functional test. Or have you got too many tests? Sometimes there is little value in having such a massive number of scenarios, and maintaining them is going to be hell.
I've put together a high level mud map of what I am thinking and would really value feedback from the group. For example, has this already been done, or thought about and discarded for some reason.To summarize:1. Feature file goes into the test manager (a server of some sort) which chops up the scenarios (being aware of the background) and farms it out to different cucumber nodes. It stores results of each execution of each step in the test management DB, along with how long each step takes and what test data it required2. The Cucumber Hub is like the Selenium Hub. Cucumber Nodes register with it and advertise test functions that it supports3. The Cucumber Node is a cucumber file (step definition and on, not the Gherkin) turned into a service. A scenarios is passed to the node, the node executes and returns the result4. The Data Manager looks after test data for different environments. It tracks daily usage and individual test usage and tries to create the necessary test data predictively ahead of time. The cucumber node will call the data manager as part of any data "given"5. The Selenium hub we already know about6. The Node Manager monitors the hubs looking at utilization levels and starts new cucumber and selenium nodes in a cloud service (such as Amazon) as required.
Definitely a lot of work! For which flavour of Cucumber (Ruby, JVM, ...) are you planning to develop it?
Another important piece that I am heading towards here is using this model for performance testing. This would reduce the cost of performance testing because no expensive tools or specialized scripts are required. It would also mean performance testing can be done as soon as the functional scripts are complete, which means it can be done earlier. One set of scripts reduces maintenance costs as well.Having detailed information about scenario and step run times and data requirements would make performance testing pretty easy to setup too.
On this point I totally disagree. The "expensive tools" for performance testing should put the application under load, and functional tests running definitely do not. In my experience there are a few scenarios that would never be addressed by running functional tests, to name a few...
- baseline - with reference production-like load, e.g. to test that the new release is performing as the old one
- soak - running at medium load for several hours on the same running instance, to detect problems like memory leaks
- special scenarios - from production load on specific events (promotional campaigns, etc.), to see if the next time it will break predict the breaking point, find bottlenecks, ...
Paolo
That's it.CheersPeter
--
Posting rules: http://cukes.info/posting-rules.html
---
You received this message because you are subscribed to the Google Groups "Cukes" group.
To unsubscribe from this group and stop receiving emails from it, send an email to cukes+un...@googlegroups.com.
For more options, visit https://groups.google.com/d/optout.

Rob Park
Nov 20, 2014, 7:16:21 AM11/20/14
to cu...@googlegroups.com
On Thu, Nov 20, 2014 at 2:42 AM, Paolo Ambrosio <pa...@ambrosio.name> wrote:
On Wed, Nov 19, 2014 at 11:50 PM, Peter Wilson <peter....@gmail.com> wrote:Hi,We've been using cucumber for about 6 months now and have found it very beneficial.We're now looking to take it to a larger scale, with tens of thousands of tests and need a better test, infrastructure and data management system.I would be really scared working on such a monolithic software that requires tens of thousands of functional test. Or have you got too many tests? Sometimes there is little value in having such a massive number of scenarios, and maintaining them is going to be hell.
+1
I have seen this done to a limited extent multiple times and it is a very brittle path that unnecessarily extends feedback loops much longer than is worth while IMO. (i.e. low ROI)
I would recommend making your systems much more component oriented and focus all of your testing at the lower levels.
I'm assuming at this scale, you're referring to several teams. The teams should be independently able to execute all tests necessary to validate their components are functional. Don't try to fight Conway's law.
I've put together a high level mud map of what I am thinking and would really value feedback from the group. For example, has this already been done, or thought about and discarded for some reason.To summarize:1. Feature file goes into the test manager (a server of some sort) which chops up the scenarios (being aware of the background) and farms it out to different cucumber nodes. It stores results of each execution of each step in the test management DB, along with how long each step takes and what test data it required2. The Cucumber Hub is like the Selenium Hub. Cucumber Nodes register with it and advertise test functions that it supports3. The Cucumber Node is a cucumber file (step definition and on, not the Gherkin) turned into a service. A scenarios is passed to the node, the node executes and returns the result4. The Data Manager looks after test data for different environments. It tracks daily usage and individual test usage and tries to create the necessary test data predictively ahead of time. The cucumber node will call the data manager as part of any data "given"5. The Selenium hub we already know about6. The Node Manager monitors the hubs looking at utilization levels and starts new cucumber and selenium nodes in a cloud service (such as Amazon) as required.Definitely a lot of work! For which flavour of Cucumber (Ruby, JVM, ...) are you planning to develop it?Another important piece that I am heading towards here is using this model for performance testing. This would reduce the cost of performance testing because no expensive tools or specialized scripts are required. It would also mean performance testing can be done as soon as the functional scripts are complete, which means it can be done earlier. One set of scripts reduces maintenance costs as well.Having detailed information about scenario and step run times and data requirements would make performance testing pretty easy to setup too.On this point I totally disagree. The "expensive tools" for performance testing should put the application under load, and functional tests running definitely do not. In my experience there are a few scenarios that would never be addressed by running functional tests, to name a few...
+1
I'm not necessarily advocating "expensive tools", just that one set of tests is a problematic idea. You'll likely want to have a focus at the component level if you have any sort of SOA. Even then, to load the system, to generate 1000s of users, items, etc is something you don't want to be part of your functional tests. You also shouldn't be focusing performance testing on edge case paths (it's debatable that you should even have functional cucumber tests for edge cases). And functional tests shouldn't be about code coverage or executing particular code paths like performance tests often are looking to profile specific conditions. Functional tests are more about behaviors... and should really be written before the functionality. Performance metrics should be thought about / discussed up front, but they often are not as binary (pass/fail) as functional tests. In other words, they are different scenarios for solving different problems.
- baseline - with reference production-like load, e.g. to test that the new release is performing as the old one- soak - running at medium load for several hours on the same running instance, to detect problems like memory leaks- special scenarios - from production load on specific events (promotional campaigns, etc.), to see if the next time it will break predict the breaking point, find bottlenecks, ...
@rob
Peter Wilson
Nov 20, 2014, 5:47:30 PM11/20/14
to cu...@googlegroups.com
Thanks for your feedback. I've put some comments below.
On Thursday, November 20, 2014 6:42:49 PM UTC+11, Paolo Ambrosio wrote:
On Wed, Nov 19, 2014 at 11:50 PM, Peter Wilson <peter....@gmail.com> wrote:Hi,We've been using cucumber for about 6 months now and have found it very beneficial.We're now looking to take it to a larger scale, with tens of thousands of tests and need a better test, infrastructure and data management system.I would be really scared working on such a monolithic software that requires tens of thousands of functional test. Or have you got too many tests? Sometimes there is little value in having such a massive number of scenarios, and maintaining them is going to be hell.
Our organisation is broken into a few systems, and components within those systems, so the structural breakdown you suggest is where I would be heading. Still a large number of aggregate tests though. I was thinking that it would be better to have one test execution infrastructure than to have each team replicating a smaller set of infrastructure and processes. Centralized would mean better big picture management and overview of the organisation's testing, plus hopefully some economies of scale. Tests could be run locally using enterprise services, or that add data to enterprise test management systems. That's kind of what I was thinking. Sorry if I painted a picture of one monolithic piece of spaghetti code, that's not what I meant.
I've put together a high level mud map of what I am thinking and would really value feedback from the group. For example, has this already been done, or thought about and discarded for some reason.To summarize:1. Feature file goes into the test manager (a server of some sort) which chops up the scenarios (being aware of the background) and farms it out to different cucumber nodes. It stores results of each execution of each step in the test management DB, along with how long each step takes and what test data it required2. The Cucumber Hub is like the Selenium Hub. Cucumber Nodes register with it and advertise test functions that it supports3. The Cucumber Node is a cucumber file (step definition and on, not the Gherkin) turned into a service. A scenarios is passed to the node, the node executes and returns the result4. The Data Manager looks after test data for different environments. It tracks daily usage and individual test usage and tries to create the necessary test data predictively ahead of time. The cucumber node will call the data manager as part of any data "given"5. The Selenium hub we already know about6. The Node Manager monitors the hubs looking at utilization levels and starts new cucumber and selenium nodes in a cloud service (such as Amazon) as required.Definitely a lot of work! For which flavour of Cucumber (Ruby, JVM, ...) are you planning to develop it?
Yeah, and I'm not convinced I've got the brains or consistency to pull it off, but I'd like to try. We use the JVM flavor. Our devs are more comfortable with Java so it was a strategic decision to use Java to make the pathway to BDD easier. Also, my spider senses sensed that Java would give more options to solve problems down the track, which actually worked out as we started using Jagacy to drive the mainframe from Cucumber for test data creation and checking that our web systems actually sent the right data to the back end.
Another important piece that I am heading towards here is using this model for performance testing. This would reduce the cost of performance testing because no expensive tools or specialized scripts are required. It would also mean performance testing can be done as soon as the functional scripts are complete, which means it can be done earlier. One set of scripts reduces maintenance costs as well.Having detailed information about scenario and step run times and data requirements would make performance testing pretty easy to setup too.On this point I totally disagree. The "expensive tools" for performance testing should put the application under load, and functional tests running definitely do not. In my experience there are a few scenarios that would never be addressed by running functional tests, to name a few...- baseline - with reference production-like load, e.g. to test that the new release is performing as the old one- soak - running at medium load for several hours on the same running instance, to detect problems like memory leaks- special scenarios - from production load on specific events (promotional campaigns, etc.), to see if the next time it will break predict the breaking point, find bottlenecks, ...
Hmm, let me explain myself here a bit better. I was not proposing that we run all of our functional tests and then call that a performance test. My thinking was more along the lines of choosing some very specific functional tests that mimic standard high utilization user scenarios and then run these at production like volumes. BTW I have actually been involved in performance testing very high volume share trading and credit card systems so while there are better performance testers out there, I do have some understanding of this area.
Perhaps using something like Splunk for the server side analysis.
Peter Wilson
Nov 20, 2014, 6:00:52 PM11/20/14
to cu...@googlegroups.com
Hi Rob, thanks for the response. Comments in line.
On Thursday, November 20, 2014 11:16:21 PM UTC+11, Rob Park wrote:
On Thu, Nov 20, 2014 at 2:42 AM, Paolo Ambrosio <pa...@ambrosio.name> wrote:On Wed, Nov 19, 2014 at 11:50 PM, Peter Wilson <peter....@gmail.com> wrote:Hi,We've been using cucumber for about 6 months now and have found it very beneficial.We're now looking to take it to a larger scale, with tens of thousands of tests and need a better test, infrastructure and data management system.I would be really scared working on such a monolithic software that requires tens of thousands of functional test. Or have you got too many tests? Sometimes there is little value in having such a massive number of scenarios, and maintaining them is going to be hell.+1I have seen this done to a limited extent multiple times and it is a very brittle path that unnecessarily extends feedback loops much longer than is worth while IMO. (i.e. low ROI)
Yeah. This is something I don't have a good handle on I suppose. We're in essence specifying by example and then executing our documentation. Some areas require a number of detailed examples to provide enough information to describe how it works. It's possible we're not pushing enough down to the unit level and leaving too much at the BDD level.
Can you give me any examples of how you have seen this done and fail before? This is exactly the kind of feedback I was hoping for. Is it a bad idea or was it just done badly before? Was it brittle because the automation was poorly done, the environment was unstable, the tests were not atomic enough? We have painstakingly gone down the path of making our test small and focused even though has meant we have had to overcome a large test data issue, so would our tests still be brittle?
Each team that makes a change would still be responsible for running relevant tests and fixing any tests that break. I guess if we have a lot of duplication in the tests or badly modularised automation code this would be a nightmare.
I would recommend making your systems much more component oriented and focus all of your testing at the lower levels.
Thanks. We are actually doing that and also have tests at the integrated module levels too.
I'm assuming at this scale, you're referring to several teams. The teams should be independently able to execute all tests necessary to validate their components are functional. Don't try to fight Conway's law.
Yes. We are using scaled agile and have 7 to 8 agile teams in our program but at the organisation level we probably have more like somewhere between 15 to 30 teams... kind of a guess.
I'm putting together solutions for the program that can also be used by the organisation.
I've put together a high level mud map of what I am thinking and would really value feedback from the group. For example, has this already been done, or thought about and discarded for some reason.To summarize:1. Feature file goes into the test manager (a server of some sort) which chops up the scenarios (being aware of the background) and farms it out to different cucumber nodes. It stores results of each execution of each step in the test management DB, along with how long each step takes and what test data it required2. The Cucumber Hub is like the Selenium Hub. Cucumber Nodes register with it and advertise test functions that it supports3. The Cucumber Node is a cucumber file (step definition and on, not the Gherkin) turned into a service. A scenarios is passed to the node, the node executes and returns the result4. The Data Manager looks after test data for different environments. It tracks daily usage and individual test usage and tries to create the necessary test data predictively ahead of time. The cucumber node will call the data manager as part of any data "given"5. The Selenium hub we already know about6. The Node Manager monitors the hubs looking at utilization levels and starts new cucumber and selenium nodes in a cloud service (such as Amazon) as required.Definitely a lot of work! For which flavour of Cucumber (Ruby, JVM, ...) are you planning to develop it?Another important piece that I am heading towards here is using this model for performance testing. This would reduce the cost of performance testing because no expensive tools or specialized scripts are required. It would also mean performance testing can be done as soon as the functional scripts are complete, which means it can be done earlier. One set of scripts reduces maintenance costs as well.Having detailed information about scenario and step run times and data requirements would make performance testing pretty easy to setup too.On this point I totally disagree. The "expensive tools" for performance testing should put the application under load, and functional tests running definitely do not. In my experience there are a few scenarios that would never be addressed by running functional tests, to name a few...+1I'm not necessarily advocating "expensive tools", just that one set of tests is a problematic idea. You'll likely want to have a focus at the component level if you have any sort of SOA. Even then, to load the system, to generate 1000s of users, items, etc is something you don't want to be part of your functional tests. You also shouldn't be focusing performance testing on edge case paths (it's debatable that you should even have functional cucumber tests for edge cases). And functional tests shouldn't be about code coverage or executing particular code paths like performance tests often are looking to profile specific conditions. Functional tests are more about behaviors... and should really be written before the functionality. Performance metrics should be thought about / discussed up front, but they often are not as binary (pass/fail) as functional tests. In other words, they are different scenarios for solving different problems.
Yep. This is similar to what I said to Paolo. Definitely not looking at running wierdo edge cases for performance testing. Just picking representative user scenarios and then running them at prod like volumes.
Rob Park
Nov 20, 2014, 11:13:52 PM11/20/14
to cu...@googlegroups.com
On Thu, Nov 20, 2014 at 6:00 PM, Peter Wilson <peter....@gmail.com> wrote:
Hi Rob, thanks for the response. Comments in line.
On Thursday, November 20, 2014 11:16:21 PM UTC+11, Rob Park wrote:On Thu, Nov 20, 2014 at 2:42 AM, Paolo Ambrosio <pa...@ambrosio.name> wrote:On Wed, Nov 19, 2014 at 11:50 PM, Peter Wilson <peter....@gmail.com> wrote:Hi,We've been using cucumber for about 6 months now and have found it very beneficial.We're now looking to take it to a larger scale, with tens of thousands of tests and need a better test, infrastructure and data management system.I would be really scared working on such a monolithic software that requires tens of thousands of functional test. Or have you got too many tests? Sometimes there is little value in having such a massive number of scenarios, and maintaining them is going to be hell.+1I have seen this done to a limited extent multiple times and it is a very brittle path that unnecessarily extends feedback loops much longer than is worth while IMO. (i.e. low ROI)Yeah. This is something I don't have a good handle on I suppose. We're in essence specifying by example and then executing our documentation. Some areas require a number of detailed examples to provide enough information to describe how it works. It's possible we're not pushing enough down to the unit level and leaving too much at the BDD level.
I'm not just referring to unit level testing, but also component level. You can execute tests much more discretely (more easily) around a single component (with a single API) than trying to setup and integrate many pieces. (Often the middle layer of the test pyramid.)
Can you give me any examples of how you have seen this done and fail before? This is exactly the kind of feedback I was hoping for. Is it a bad idea or was it just done badly before? Was it brittle because the automation was poorly done, the environment was unstable, the tests were not atomic enough? We have painstakingly gone down the path of making our test small and focused even though has meant we have had to overcome a large test data issue, so would our tests still be brittle?
I wouldn't say the teams I was referring to were an actual fail, just that there was a lot of pain and in fact the recovery is still in progress and continuing.
Sure we always realize we could have code things better, but that wasn't the problem I was siting. The brittleness is inherent in: deploying all "new" instances of the individual components/services, setting up test data across those, execution time across components, and coordination across multiple teams.
Each team that makes a change would still be responsible for running relevant tests and fixing any tests that break. I guess if we have a lot of duplication in the tests or badly modularised automation code this would be a nightmare.
Actually, duplication isn't necessarily as worrisome to me as having code I'm dependent on controlled by a separate team.
I would recommend making your systems much more component oriented and focus all of your testing at the lower levels.Thanks. We are actually doing that and also have tests at the integrated module levels too.I'm assuming at this scale, you're referring to several teams. The teams should be independently able to execute all tests necessary to validate their components are functional. Don't try to fight Conway's law.Yes. We are using scaled agile and have 7 to 8 agile teams in our program but at the organisation level we probably have more like somewhere between 15 to 30 teams... kind of a guess.I'm putting together solutions for the program that can also be used by the organisation.
One point of clarification: I think it's fine and reasonable to have centralized reporting of what tests were run, how long they took and if they were pass/fail. But teams should be able to run all tests relevant to them IMO.

Jordi de Vos
Jan 2, 2015, 8:09:41 AM1/2/15
to cu...@googlegroups.com
Another important piece that I am heading towards here is using this model for performance testing. This would reduce the cost of performance testing because no expensive tools or specialized scripts are required. It would also mean performance testing can be done as soon as the functional scripts are complete, which means it can be done earlier. One set of scripts reduces maintenance costs as well.Having detailed information about scenario and step run times and data requirements would make performance testing pretty easy to setup too.On this point I totally disagree. The "expensive tools" for performance testing should put the application under load, and functional tests running definitely do not. In my experience there are a few scenarios that would never be addressed by running functional tests, to name a few...+1I'm not necessarily advocating "expensive tools", just that one set of tests is a problematic idea. You'll likely want to have a focus at the component level if you have any sort of SOA. Even then, to load the system, to generate 1000s of users, items, etc is something you don't want to be part of your functional tests. You also shouldn't be focusing performance testing on edge case paths (it's debatable that you should even have functional cucumber tests for edge cases). And functional tests shouldn't be about code coverage or executing particular code paths like performance tests often are looking to profile specific conditions. Functional tests are more about behaviors... and should really be written before the functionality. Performance metrics should be thought about / discussed up front, but they often are not as binary (pass/fail) as functional tests. In other words, they are different scenarios for solving different problems.Yep. This is similar to what I said to Paolo. Definitely not looking at running wierdo edge cases for performance testing. Just picking representative user scenarios and then running them at prod like volumes.
Hi everyone,
In my company we use cucumber for REST APIs and this particular topic is very interesting for that. In our continuous delivery pipeline we would like to put each component under stress in isolation, just to make sure it still performs properly and the VM configuration is still up for the job. This is a step that happens separate from functional testing and separate from other performance testing (failover, chain, endurance, etc) so I think I have similar ideas as Peter. It's just meant as a fully automated regression test on performance, before the component goes to the next step in the pipeline. Developers/testers already spend time and effort in writing scenario's for functional testing and with most performance test tools, they would have to write very similar logic to do performance testing, meaning they'd be duplicating their work. This is quite inefficient and if that logic is already specified somewhere, it would be nice to just reuse it.
It would be a great time-saver if we could for instance just add an annotation to specific scenarios to specify the amount of load it should be able to handle. I'm thinking about adding something like @performance(tps=10, p99=500ms) for a scenario that is called about 10 times each second in production and should respond in 500ms in 99% of the cases. In our 'functional testing environment' we would just ignore this annotation, but in the 'performance testing environment' we could use a different way of running the cucumber tests, selecting only those tests that have the @performance annotation and settings the load and verifying the performance as configured and the the API responses as specified in the feature files.
I am interested in hearing why this would or would not be a good idea. Also, if this can be built as a separate plug-in or something like that I would be very interested in a few pointers on how to do that. I am quite clueless on how to get hold of features and their annotations (including any information inside these annotations) in a location from which I can then invoke a stress test tool, so any help on that is appreciated.
Cheers,
Jordi
Rob Park
Jan 2, 2015, 9:58:03 AM1/2/15
to cu...@googlegroups.com
On Fri, Jan 2, 2015 at 8:09 AM, Jordi de Vos <devos...@gmail.com> wrote:
Another important piece that I am heading towards here is using this model for performance testing. This would reduce the cost of performance testing because no expensive tools or specialized scripts are required. It would also mean performance testing can be done as soon as the functional scripts are complete, which means it can be done earlier. One set of scripts reduces maintenance costs as well.Having detailed information about scenario and step run times and data requirements would make performance testing pretty easy to setup too.On this point I totally disagree. The "expensive tools" for performance testing should put the application under load, and functional tests running definitely do not. In my experience there are a few scenarios that would never be addressed by running functional tests, to name a few...+1I'm not necessarily advocating "expensive tools", just that one set of tests is a problematic idea. You'll likely want to have a focus at the component level if you have any sort of SOA. Even then, to load the system, to generate 1000s of users, items, etc is something you don't want to be part of your functional tests. You also shouldn't be focusing performance testing on edge case paths (it's debatable that you should even have functional cucumber tests for edge cases). And functional tests shouldn't be about code coverage or executing particular code paths like performance tests often are looking to profile specific conditions. Functional tests are more about behaviors... and should really be written before the functionality. Performance metrics should be thought about / discussed up front, but they often are not as binary (pass/fail) as functional tests. In other words, they are different scenarios for solving different problems.Yep. This is similar to what I said to Paolo. Definitely not looking at running wierdo edge cases for performance testing. Just picking representative user scenarios and then running them at prod like volumes.
Hi everyone,
In my company we use cucumber for REST APIs and this particular topic is very interesting for that. In our continuous delivery pipeline we would like to put each component under stress in isolation, just to make sure it still performs properly and the VM configuration is still up for the job. This is a step that happens separate from functional testing and separate from other performance testing (failover, chain, endurance, etc) so I think I have similar ideas as Peter. It's just meant as a fully automated regression test on performance, before the component goes to the next step in the pipeline. Developers/testers already spend time and effort in writing scenario's for functional testing and with most performance test tools, they would have to write very similar logic to do performance testing, meaning they'd be duplicating their work.
This is quite inefficient and if that logic is already specified somewhere, it would be nice to just reuse it.
Is it? By doubling the purpose of the tests and introducing complexity to the framework and on 2 different feedback loops may in fact be more inefficient, especially when problems creep in.
It would be a great time-saver if we could for instance just add an annotation to specific scenarios to specify the amount of load it should be able to handle. I'm thinking about adding something like @performance(tps=10, p99=500ms) for a scenario that is called about 10 times each second in production and should respond in 500ms in 99% of the cases. In our 'functional testing environment' we would just ignore this annotation, but in the 'performance testing environment' we could use a different way of running the cucumber tests, selecting only those tests that have the @performance annotation and settings the load and verifying the performance as configured and the the API responses as specified in the feature files.
It would IMO be much better to do exactly what the performance test needs without any of the "noise" about what the scenarios are trying to achieve from a functional perspective.
I am interested in hearing why this would or would not be a good idea. Also, if this can be built as a separate plug-in or something like that I would be very interested in a few pointers on how to do that. I am quite clueless on how to get hold of features and their annotations (including any information inside these annotations) in a location from which I can then invoke a stress test tool, so any help on that is appreciated.
Cheers,
Jordi
@robpark

Selenium Framework
Jan 2, 2015, 11:33:22 AM1/2/15
to cu...@googlegroups.com
Do I get a feeling that we are assuming Cucumber to be an automation tool/ framework ? Frankly it is not and it is more of a collaboration tool to encourage ATDD/BDD/TDD.
Here is a blog from the creator of Cucumber - https://cucumber.pro/blog/2014/03/03/the-worlds-most-misunderstood-collaboration-tool.html
So where am I going with this. In the above diagram, Cucumber hub nodes grid looks like we are turning cucumber into this super awesome automation framework/tool. The rest of the touch points in the diagram are completely scalable and I have implemented it both on-premise solution with a 50 node grid and/or on cloud solutions like Amazon/Sauce labs.
W.r.t centralization/decentralization, it is a very debatable topic. Large financial organizations have been very centralized w.r.t. test data, testing etc. and that is actually slowing them down and that affects their agility to keep up with the technology change/space. If we intend to go in the direction of CI/CD/CT, then the inclination should start with building it bottoms up. And when things settle at some point, we can think about centralization. If we are concerned about how to have a high level management view, aggregate view et al., those dashboards are handled as part of CI servers. There are enough # of plugins for Test Automation on Jenkins, Hudson, Team City, that can give a trend analysis across time, across builds, across tests, across <whatever parameter>.
My two cents!
Cheers

Stephen Kurlow
Mar 18, 2015, 9:46:17 AM3/18/15
to cu...@googlegroups.com
Hi Peter,
I worked in an organisation that had 30000 scenarios last time I checked in so will be more than that today. At the time of there being 30000 scenarios they could all be executed in parallel around 15 at a time so that the total duration was about 1.5hrs. They were ALL being run after EVERY code check-in but they were starting to think about only running a sub-set after each code checkin as 1.5hrs was getting too long. Obviously could add more servers so they could run more than 15 in parallel or get faster servers, etc.
The approach that was taken wasn't to parallelise by scenario but rather parallelise by feature file. They had an inhouse tool which would split up the around 10000 feature files and allocate 1/15th of each to a separate job, I cannot remember but I guess a separate bamboo job. I think each job was allocated a separate target environment to run the tests against. I don't recall we solved the problem of producing a single report.
I think Scaling BDD is an important topic. Are you interested in pursuing this topic further privately?
PS: Anyone who says to you that more than 10000 scenarios is wrong...well that person is wrong. ;-)
Regards,
Stephen Kurlow

Oscar Rieken
Mar 18, 2015, 10:10:18 AM3/18/15
to cu...@googlegroups.com
On Tue, Mar 17, 2015 at 12:15 AM, Stephen Kurlow <sku...@gmail.com> wrote:
Hi Peter,I worked in an organisation that had 30000 scenarios last time I checked in so will be more than that today. At the time of there being 30000 scenarios they could all be executed in parallel around 15 at a time so that the total duration was about 1.5hrs. They were ALL being run after EVERY code check-in but they were starting to think about only running a sub-set after each code checkin as 1.5hrs was getting too long. Obviously could add more servers so they could run more than 15 in parallel or get faster servers, etc.The approach that was taken wasn't to parallelise by scenario but rather parallelise by feature file. They had an inhouse tool which would split up the around 10000 feature files and allocate 1/15th of each to a separate job, I cannot remember but I guess a separate bamboo job. I think each job was allocated a separate target environment to run the tests against. I don't recall we solved the problem of producing a single report.I think Scaling BDD is an important topic. Are you interested in pursuing this topic further privately?PS: Anyone who says to you that more than 10000 scenarios is wrong...well that person is wrong. ;-)
Personally I think its up to the team, and product owner to decide on what scenarios should stay and which should go. The last place i was at the average number of scenarios per team was around 2500, and we managed to get the running at about 12 min on average.
Regards,Stephen Kurlow
On Thursday, 20 November 2014 10:50:37 UTC+11, Peter Wilson wrote:Hi,We've been using cucumber for about 6 months now and have found it very beneficial.We're now looking to take it to a larger scale, with tens of thousands of tests and need a better test, infrastructure and data management system.I've put together a high level mud map of what I am thinking and would really value feedback from the group. For example, has this already been done, or thought about and discarded for some reason.To summarize:1. Feature file goes into the test manager (a server of some sort) which chops up the scenarios (being aware of the background) and farms it out to different cucumber nodes. It stores results of each execution of each step in the test management DB, along with how long each step takes and what test data it required2. The Cucumber Hub is like the Selenium Hub. Cucumber Nodes register with it and advertise test functions that it supports3. The Cucumber Node is a cucumber file (step definition and on, not the Gherkin) turned into a service. A scenarios is passed to the node, the node executes and returns the result4. The Data Manager looks after test data for different environments. It tracks daily usage and individual test usage and tries to create the necessary test data predictively ahead of time. The cucumber node will call the data manager as part of any data "given"5. The Selenium hub we already know about6. The Node Manager monitors the hubs looking at utilization levels and starts new cucumber and selenium nodes in a cloud service (such as Amazon) as required.Another important piece that I am heading towards here is using this model for performance testing. This would reduce the cost of performance testing because no expensive tools or specialized scripts are required. It would also mean performance testing can be done as soon as the functional scripts are complete, which means it can be done earlier. One set of scripts reduces maintenance costs as well.Having detailed information about scenario and step run times and data requirements would make performance testing pretty easy to setup too.That's it.CheersPeter

aslak hellesoy
Mar 18, 2015, 11:11:42 AM3/18/15
to Cucumber Users
On Tue, Mar 17, 2015 at 4:15 AM, Stephen Kurlow <sku...@gmail.com> wrote:
Hi Peter,I worked in an organisation that had 30000 scenarios last time I checked in so will be more than that today.
Out of curiosity, roughly how many unit tests did this system have?
At the time of there being 30000 scenarios they could all be executed in parallel around 15 at a time so that the total duration was about 1.5hrs. They were ALL being run after EVERY code check-in but they were starting to think about only running a sub-set after each code checkin as 1.5hrs was getting too long. Obviously could add more servers so they could run more than 15 in parallel or get faster servers, etc.The approach that was taken wasn't to parallelise by scenario but rather parallelise by feature file. They had an inhouse tool which would split up the around 10000 feature files and allocate 1/15th of each to a separate job, I cannot remember but I guess a separate bamboo job. I think each job was allocated a separate target environment to run the tests against. I don't recall we solved the problem of producing a single report.I think Scaling BDD is an important topic. Are you interested in pursuing this topic further privately?PS: Anyone who says to you that more than 10000 scenarios is wrong...well that person is wrong. ;-)
That's contextual. You can say that 10000 scenarios is wrong and be right.
Aslak
Regards,Stephen Kurlow
On Thursday, 20 November 2014 10:50:37 UTC+11, Peter Wilson wrote:Hi,We've been using cucumber for about 6 months now and have found it very beneficial.We're now looking to take it to a larger scale, with tens of thousands of tests and need a better test, infrastructure and data management system.I've put together a high level mud map of what I am thinking and would really value feedback from the group. For example, has this already been done, or thought about and discarded for some reason.To summarize:1. Feature file goes into the test manager (a server of some sort) which chops up the scenarios (being aware of the background) and farms it out to different cucumber nodes. It stores results of each execution of each step in the test management DB, along with how long each step takes and what test data it required2. The Cucumber Hub is like the Selenium Hub. Cucumber Nodes register with it and advertise test functions that it supports3. The Cucumber Node is a cucumber file (step definition and on, not the Gherkin) turned into a service. A scenarios is passed to the node, the node executes and returns the result4. The Data Manager looks after test data for different environments. It tracks daily usage and individual test usage and tries to create the necessary test data predictively ahead of time. The cucumber node will call the data manager as part of any data "given"5. The Selenium hub we already know about6. The Node Manager monitors the hubs looking at utilization levels and starts new cucumber and selenium nodes in a cloud service (such as Amazon) as required.Another important piece that I am heading towards here is using this model for performance testing. This would reduce the cost of performance testing because no expensive tools or specialized scripts are required. It would also mean performance testing can be done as soon as the functional scripts are complete, which means it can be done earlier. One set of scripts reduces maintenance costs as well.Having detailed information about scenario and step run times and data requirements would make performance testing pretty easy to setup too.That's it.CheersPeter
Stephen Kurlow
Mar 18, 2015, 3:37:34 PM3/18/15
to cu...@googlegroups.com
Sure. I wonder are most teams out there focusing on automating the most valuable scenarios and leaving out the low value scenarios for manual testing? As I learn more and more about BDD I'm seeing it makes increasingly more sense to focus on automating the scenarios that link to the acceptance criterions with most business value. Whatever that number is whether it is 100, 2000, 10000 etc then it should be an almost no-brainer for the Product Owner to want to see a team is continuously showcasing in CI they work...playing in to the Agile Manifesto's importance on working software.

You received this message because you are subscribed to a topic in the Google Groups "Cukes" group.
To unsubscribe from this topic, visit https://groups.google.com/d/topic/cukes/bh0EUhKHqCI/unsubscribe.
To unsubscribe from this group and all its topics, send an email to cukes+un...@googlegroups.com.
Stephen Kurlow
Mar 18, 2015, 7:28:00 PM3/18/15
to cu...@googlegroups.com
Sorry forgot to answer one of your questions.
On Thursday, 19 March 2015 02:11:42 UTC+11, Aslak Hellesøy wrote:
On Tue, Mar 17, 2015 at 4:15 AM, Stephen Kurlow <sku...@gmail.com> wrote:Hi Peter,I worked in an organisation that had 30000 scenarios last time I checked in so will be more than that today.
Out of curiosity, roughly how many unit tests did this system have?
Nice question. I will ask the Program Mgr what the current stats are as I don't know and I no longer work there. I will answer now based on my perception of my narrow view of what I saw in terms of unit testing. Yes we practised TDD too and I'd say the rough ratio of scenarios:unittests was 1:10
We were developing 3 software systems. Minor changes to a long term legacy system that adopted BDD for small changes whilst two new software systems were introduced and BDD/TDD were thoroughly practised on the 2 new software systems.
Momentum/pace I thought was effective, features were small enough that we could estimate in story points that translated more or less in getting a feature to done somewhere between 1 and 5 days. Features were system centric.
Stephen Kurlow
Mar 18, 2015, 7:38:03 PM3/18/15
to cu...@googlegroups.com
On Thursday, 19 March 2015 01:10:18 UTC+11, Oscar.Rieken wrote:
On Tue, Mar 17, 2015 at 12:15 AM, Stephen Kurlow <sku...@gmail.com> wrote:Hi Peter,I worked in an organisation that had 30000 scenarios last time I checked in so will be more than that today. At the time of there being 30000 scenarios they could all be executed in parallel around 15 at a time so that the total duration was about 1.5hrs. They were ALL being run after EVERY code check-in but they were starting to think about only running a sub-set after each code checkin as 1.5hrs was getting too long. Obviously could add more servers so they could run more than 15 in parallel or get faster servers, etc.The approach that was taken wasn't to parallelise by scenario but rather parallelise by feature file. They had an inhouse tool which would split up the around 10000 feature files and allocate 1/15th of each to a separate job, I cannot remember but I guess a separate bamboo job. I think each job was allocated a separate target environment to run the tests against. I don't recall we solved the problem of producing a single report.I think Scaling BDD is an important topic. Are you interested in pursuing this topic further privately?PS: Anyone who says to you that more than 10000 scenarios is wrong...well that person is wrong. ;-)Personally I think its up to the team, and product owner to decide on what scenarios should stay and which should go. The last place i was at the average number of scenarios per team was around 2500, and we managed to get the running at about 12 min on average.
Yep. I would be interested to know how that was achieved. How did your team enable the execution of 2500 scenarios with around 200/min? I have been asked by solution architects how can we scale up cucumber without compromising on how much value we deliver in terms of continuous working software when BDD practitioners use it?

Donavan Stanley
Apr 3, 2015, 5:44:35 PM4/3/15
to cu...@googlegroups.com
My company is steadily working towards releasing our execution framework as open source. This month we're going to put the fourth iteration through it's paces, once that's complete a release will soon follow. The system was designed to do two things: shorten the feedback loop and improve the signal to noise ratio.
Implemented as several services:
- Manager - The core dispatcher of the system. Sends tasks out, in priority order, to workers.
- Queuebert - Generates and sends tasks off the the manager. There's one of these per task type. For example the cucumber queuebert parses feature files to divide them up into the smallest unit of work Cucumber will run and creates tasks.
- Keeper - Stores the results of a task in the database, or requeues it back to run again (If someone trips over a network cable that's not the fault of the system under test so run the test again).
- Hunny Pot - Provides a fancy UI for displaying results, with all the charts and graphs product owners love. (Named scheduled to change as it's based on generate 3 "the hive")
The current generation of this framework allows our company to test at levels deemed insane at other companies. The main test suite for one of our products is over 6k tests and is run in multiple branches every day. Command line tools allow developers to push their code and execute a batch of tests against it independent of the CI server or scheduled tests.
All of the components work in windows as well as *nix.
If you're anywhere near Columbus Ohio I'd love to sit down for coffee with you.
Stephen Kurlow
Apr 3, 2015, 6:37:38 PM4/3/15
to cu...@googlegroups.com
Hi Donovan,
I'm looking forward to seeing more such as screenshots, workflow diagram, short video. :)
What happens to the cucumber reports? Are they collated after all parallelised test runs complete? Can a CI system such as Jenkins then report on how many passed and failed with link to cucumber report?
What about test envs where the system under test is deployed? Are there one per parallel test run?
PS: Interested in a CukeUp Conf in Australia 2015/16? Let us know at https://skurlow.typeform.com/to/gzVqI2
Regards,
--
Posting rules: http://cukes.info/posting-rules.html
---
You received this message because you are subscribed to a topic in the Google Groups "Cukes" group.
To unsubscribe from this topic, visit https://groups.google.com/d/topic/cukes/bh0EUhKHqCI/unsubscribe.
To unsubscribe from this group and all its topics, send an email to cukes+un...@googlegroups.com.
Reply all
Reply to author
Forward
0 new messages