montecarlo_cluster_stat; weird z values and problems in implementing the permutation null_data set
250 views
Skip to first unread message

Alexis Pérez
Jul 21, 2015, 1:28:54 PM7/21/15
to cosm...@googlegroups.com
Using montecarlo cluster stat.

I have an experiment where I am decoding 5 stimuli classes (different auditory frequencies) in surface space (10 subjects; ld = 16). I obtained null distribution for each subject after decoding shuffled labels in 100 permutations, and bootstrapping 1000 values per subject to generate the null distribution for group statistical comparison at p = 0.01 (99 % upper bound in my null distribution). This way I can filter out those accuracies below the 99% threshold. The limitation is that I am not correcting for multiple comparisons and I am not taking into account cluster size in my analyses (I found some small clusters of 1 or 2 nodes that I do not know if these are noise or signal, possily a cluster level threshold might help to resolve this).
Thus, I am applying the cosmomvpa function comos_montecarlo_cluster_stat to perform the bootstrapping and cluster analyses together, however I am obtaining Z values maps that do not correspond at all with the maps I generated using only the permutation and bootstrapping procedure mentioned above.
I am going to explain what I am doing, I hope someone has patient enough to check if I am doing something wrong.
First of all, I created a ds variable with 10 chunks (10 subjects), and the samples are [number of subjects features] -> [10 5124] (see at the end of this email the cosmo_disp(ds) output)
To calculate the surface neighborhoods I load the inflated surface of one subject as follows:
[v_inf,f_inf] = surfing_read(inflated_fn);
opt.vertices = v_inf;
opt.faces = f_inf;
nh = cosmo_cluster_neighborhood(ds,'progress',false,opt);
then,
I set the options for the comos_montecarlo_cluster_stat :
opt=struct();
opt.cluster_stat='tfce'; % Threshold-Free Cluster Enhancement;
opt.niter=1000;
opt.h0_mean=0.2; %1/5 classes
and I run the function:
z_ds=cosmo_montecarlo_cluster_stat(ds,nh,opt);
In the end, most of the z are 0. This is the z values histogram that I am obtaining
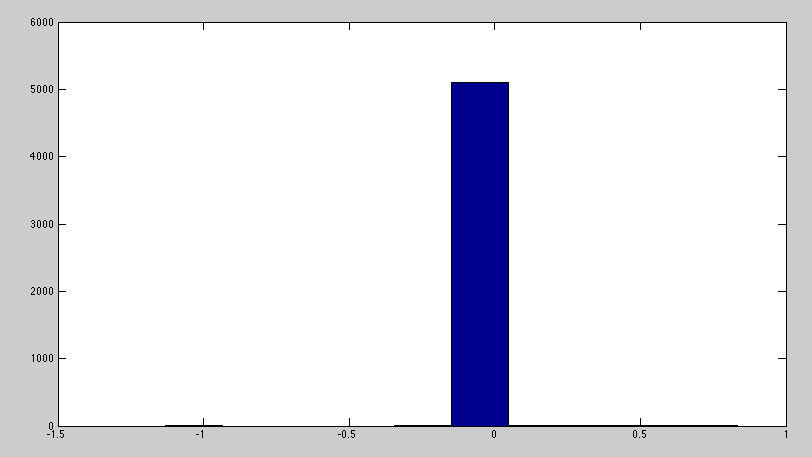
Does this makes sense to you? I think that I am doing something wrong.
Additionally, I am trying to use my 100 permutation null distributions with the cosmo_montercarlo function
To do that, I create a cell variable called
null_data{n_subjects} = [100 5124]
and I add this to the previous opt structure:
opt.null = null_data
and then I run again
z_ds=cosmo_montecarlo_cluster_stat(ds,nh,opt);
Cosmomvpa reports:
"Error using cosmo_montecarlo_cluster_stat>check_null_datasets (line 505)
1-th null dataset: not a valid dataset"
I have tried different options but I think that I am missing something in the structions..
Here I show you what is the ds format
cosmo_disp(ds)
.a
.fdim
.labels
{ 'node_indices' }
.values
{ [ 1 2 3 ... 5.12e+03 5.12e+03 5.12e+03 ]@1x5124 }
.fa
.node_indices
[ 1 2 3 ... 5.12e+03 5.12e+03 5.12e+03 ]@1x5124
.center_ids
[ 1 2 3 ... 5.12e+03 5.12e+03 5.12e+03 ]@1x5124
.samples
[ 0.1 0.0667 0.2 ... 0.167 0.333 0.2
0.267 0.1 0.3 ... 0.133 0.233 0.133
0.133 0.167 0.333 ... 0.267 0.2 0.233
: : : : : :
0.333 0.2 0.167 ... 0.233 0.133 0.2
0.2 0.367 0.267 ... 0.133 0.167 0.133
0.167 0.3 0.267 ... 0.267 0.3 0.167 ]@10x5124
.sa
.targets
[ 1
1
1
:
1
1
1 ]@10x1
.chunks
[ 1
2
3
:
8
9
10 ]@10x1
Thanks!
alex

Nick Oosterhof
Jul 22, 2015, 8:42:29 AM7/22/15
to Alexis Pérez, cosm...@googlegroups.com
> On 21 Jul 2015, at 19:28, Alexis Pérez <alexisper...@gmail.com> wrote:
>
>
> I have an experiment where I am decoding 5 stimuli classes (different auditory frequencies) in surface space (10 subjects; ld = 16). I obtained null distribution for each subject after decoding shuffled labels in 100 permutations, and bootstrapping 1000 values per subject to generate the null distribution for group statistical comparison at p = 0.01 (99 % upper bound in my null distribution). This way I can filter out those accuracies below the 99% threshold. The limitation is that I am not correcting for multiple comparisons
>
> Thus, I am applying the cosmomvpa function comos_montecarlo_cluster_stat to perform the bootstrapping and cluster analyses together, however I am obtaining Z values maps that do not correspond at all with the maps I generated using only the permutation and bootstrapping procedure mentioned above.
>
> […]
>
> I set the options for the comos_montecarlo_cluster_stat :
>
>
> opt=struct();
>
> opt.cluster_stat='tfce'; % Threshold-Free Cluster Enhancement;
>
> opt.niter=1000;
>
> opt.h0_mean=0.2; %1/5 classes
>
> and I run the function:
>
> z_ds=cosmo_montecarlo_cluster_stat(ds,nh,opt);
That all looks good to me.
>
>
> opt=struct();
>
> opt.cluster_stat='tfce'; % Threshold-Free Cluster Enhancement;
>
> opt.niter=1000;
>
> opt.h0_mean=0.2; %1/5 classes
>
> and I run the function:
>
> z_ds=cosmo_montecarlo_cluster_stat(ds,nh,opt);
>
> In the end, most of the z are 0. This is the z values histogram that I am obtaining
For a one-sided test and classification above chance, only features with z=1.65 or higher would be considered significant.
> Additionally, I am trying to use my 100 permutation null distributions with the cosmo_montercarlo function
>
> To do that, I create a cell variable called
>
> null_data{n_subjects} = [100 5124]
>
> and I add this to the previous opt structure:
>
> opt.null = null_data
>
> and then I run again
>
> z_ds=cosmo_montecarlo_cluster_stat(ds,nh,opt);
>
> Cosmomvpa reports:
>
> "Error using cosmo_montecarlo_cluster_stat>check_null_datasets (line 505)
The .null argument must be a cell, with each element a dataset of the same size as ds.
The current error message is not very clear; I’ve updated the code to provide a more informative error message. If you still keep having an error, can you provide the error message as produced by the latest code please?
In the meantime, can you provide the output of cosmo_disp(opt.null)?
Alexis Pérez
Jul 22, 2015, 11:45:43 AM7/22/15
to CoSMoMVPA
Thank you for the fast answer.
I updated the code with you modifications and now the error message is:
z_ds=cosmo_montecarlo_cluster_stat(ds,nh,opt);
Operands to the || and && operators must be convertible to logical scalar values.
Error in cosmo_check_dataset (line 126)
if ~is_ok && error_if_not_ok
Error in cosmo_montecarlo_cluster_stat>check_null_datasets (line 473)
cosmo_check_dataset(elem,[],error_prefix);
Error in cosmo_montecarlo_cluster_stat>get_null_permuter_func (line 412)
check_null_datasets(ds,null_datasets);
Error in cosmo_montecarlo_cluster_stat>get_permuter_preproc_func (line 392)
permuter_func=get_null_permuter_func(ds,preproc_func,...
Error in cosmo_montecarlo_cluster_stat (line 202)
permutation_preproc_func=get_permuter_preproc_func(ds,preproc_func,...
I have ensured that opt.null is a cell variable. This variable has 10 fields (one per subject) and within each field there are 100 rows (permutations response vector) and 5124 columns(features). Same number of features in ds.samples and in the null dataset.
here the cosmo_disp output.
cosmo_disp(opt.null)
{ [ 0.1 0.1 0.233 ... 0.167 0.1 0.1 [ 0.167 0.267 0.333 ... 0.2 0.233 0.2 [ 0.267 0.0333 0.167 ... 0.2 0.167 0.167 ... [ 0.167 0.167 0.167 ... 0.3 0.333 0.3 [ 0.333 0.4 0.133 ... 0.233 0.2 0.233 [ 0.167 0.267 0.133 ... 0.167 0.167 0.2
0.4 0.267 0.333 ... 0.333 0.133 0.333 0.133 0.0667 0.133 ... 0.0667 0.0667 0.0333 0.2 0.333 0.233 ... 0.167 0.1 0.133 0.233 0.1 0.233 ... 0.1 0.167 0.1 0.167 0.233 0.3 ... 0.333 0.233 0.233 0.2 0.2 0.267 ... 0.2 0.1 0.133
0.2 0.3 0.133 ... 0.133 0.167 0.233 0.233 0.2 0.2 ... 0.333 0.233 0.267 0.167 0.233 0.133 ... 0.4 0.4 0.467 0.367 0.167 0.4 ... 0.2 0.3 0.2 0.167 0.167 0.2 ... 0.167 0.167 0.167 0.233 0.167 0.1 ... 0.167 0.1 0.0667
: : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : :
0.267 0.167 0.233 ... 0.167 0.167 0.333 0.267 0.1 0.267 ... 0.167 0.2 0.267 0.3 0.233 0.1 ... 0.167 0.133 0.133 0.233 0.2 0.3 ... 0.3 0.167 0.267 0.2 0.267 0.267 ... 0.267 0.133 0.3 0 0.267 0.233 ... 0.133 0.167 0.2
0.133 0.0667 0.2 ... 0.267 0.267 0.2 0.2 0.167 0.2 ... 0.0667 0.133 0.0667 0.0667 0.167 0.2 ... 0.167 0.167 0.167 0.167 0.267 0.267 ... 0.133 0.233 0.2 0.2 0.1 0.267 ... 0.267 0.333 0.367 0.3 0.3 0.133 ... 0.267 0.333 0.3
0.2 0.2 0.167 ... 0.233 0.233 0.367 ]@100x5124 0.3 0.133 0.233 ... 0.233 0.367 0.433 ]@100x5124 0.3 0.167 0.4 ... 0.0667 0.3 0.133 ]@100x5124 0.2 0.233 0.167 ... 0.1 0.2 0.133 ]@100x5124 0.0667 0.1 0.2 ... 0.3 0.2 0.3 ]@100x5124 0.3 0.2 0.2 ... 0.233 0.133 0.133 ]@100x5124 }@1x10
Everything seems correct.
Btw, after applying the cosmo_montercalo function, those z values = 0 in the final statistic map signify that the actual z value for that searchlight ROI was below 1.65 and did not survive the threshold? Complementarily, does a z value = 0.12 represent an actual z value of 1.65 + 0.12? Is it possible to change the statistical threshold above 1.65?
Thank you again! :)
>>
Nick Oosterhof
Jul 22, 2015, 12:33:44 PM7/22/15
to Alexis Pérez, CoSMoMVPA
> On 22 Jul 2015, at 17:45, Alexis Pérez <alexisper...@gmail.com> wrote:
>
> Thank you for the fast answer.
>
> I updated the code with you modifications and now the error message is:
>
> z_ds=cosmo_montecarlo_cluster_stat(ds,nh,opt);
> Operands to the || and && operators must be convertible to logical scalar values.
>
> Error in cosmo_check_dataset (line 126)
> if ~is_ok && error_if_not_ok
> I have ensured that opt.null is a cell variable. This variable has 10 fields (one per subject) and within each field there are 100 rows (permutations response vector) and 5124 columns(features). Same number of features in ds.samples and in the null dataset.
>
> here the cosmo_disp output.
>
> cosmo_disp(opt.null)
>
>
> Everything seems correct.
Actually the contents in opt.null must be a cell, with each element being a *dataset struct* (with a field .samples ; in your case each dataset must have 10 rows because you have 10 participants; the .samples field must be based on randomised data within each participant). Also null{i}.sa must be identical to ds.a for all i.
> Btw, after applying the cosmo_montercalo function, those z values = 0 in the final statistic map signify that the actual z value for that searchlight ROI was below 1.65 and did not survive the threshold? Complementarily, does a z value = 0.12 represent an actual z value of 1.65 + 0.12? Is it possible to change the statistical threshold above 1.65?
p_corr=1-normcdf(z)
so that a z-score of 0.12 corresponds to p=0.45, which is not significant at all.
Alexis Pérez
Jul 22, 2015, 7:15:18 PM7/22/15
to Nick Oosterhof, CoSMoMVPA
Perfect!
Now the null permutation distributions are being taken into account. I was not clear to me that I had to reproduce the ds structure within the opt.null variable with 100 fields (one per permutation), 10 rows each field.
I updated the code in the cosmo_check_dataset file. After this change the message was more specific:
" z_ds=cosmo_montecarlo_cluster_stat(ds,nh,opt);
Error using cosmo_check_dataset (line 137)
1-th null dataset: : input must be a struct "
If I understood correctly, the values in the statistical map are the cluster-wise corrected z scores for each node. Then, if I want a one tailed threshold p = 0.05 I should filter our those z values below 1.65.
To understand how the z values are corrected I guess I should read this, Stephen M. Smith, Thomas E. Nichols (2009), right?
Thank you for your help.
alex
--
Alexis Pérez Bellido
Baylor College of Medicine
One Baylor Plaza
Houston, TX 77030
Nick Oosterhof
Jul 23, 2015, 4:37:52 AM7/23/15
to Alexis Pérez, CoSMoMVPA
> On 23 Jul 2015, at 01:15, Alexis Pérez <alexisper...@gmail.com> wrote:
>
> Now the null permutation distributions are being taken into account. I was not clear to me that I had to reproduce the ds structure within the opt.null variable with 100 fields (one per permutation), 10 rows each field.
>
> I updated the code in the cosmo_check_dataset file. After this change the message was more specific:
>
> " z_ds=cosmo_montecarlo_cluster_stat(ds,nh,opt);
> Error using cosmo_check_dataset (line 137)
Ok, very good.
>
> If I understood correctly, the values in the statistical map are the cluster-wise corrected z scores for each node. Then, if I want a one tailed threshold p = 0.05 I should filter our those z values below 1.65.
>
> To understand how the z values are corrected I guess I should read this, Stephen M. Smith, Thomas E. Nichols (2009), right?

Heath Matheson
Mar 31, 2016, 2:57:23 PM3/31/16
to CoSMoMVPA, alexisper...@gmail.com
Hi all,
I've read this thread and it has helped me understand the cluster_stat function better, and I've looked at the comments on the function itself. I just want to make sure I am clear on one thing:
There are two things happening in this function. There is permutation testing (i.e. the generation of a null distribution with which to compare our observed data against) and TFCE. So, according to the function's notes, it appears that
1) We do the permutations first. That is, we get a z-map based on the probability of the observed data given the null distribution
2) Then we apply TFCE on the zmap.
Is this correct? If it is, I am wondering if you could say a word or two about why we apply TFCE at this point and not some other point (say, on the raw classification or correlation maps). If it isn't correct, then I must have it backwards?
Thanks so much!
Heath
Nick Oosterhof
Apr 1, 2016, 4:27:51 AM4/1/16
to Heath Matheson, CoSMoMVPA, alexisper...@gmail.com
> On 31 Mar 2016, at 20:57, Heath Matheson <heatheri...@gmail.com> wrote:
>
> I've read this thread and it has helped me understand the cluster_stat function better, and I've looked at the comments on the function itself. I just want to make sure I am clear on one thing:
>
> There are two things happening in this function. There is permutation testing (i.e. the generation of a null distribution with which to compare our observed data against) and TFCE. So, according to the function's notes, it appears that
> 1) We do the permutations first. That is, we get a z-map based on the probability of the observed data given the null distribution
> 2) Then we apply TFCE on the zmap.
>
> Is this correct?
a) data from each subject is used in a group analysis, using a one-sample t-test, two-sample t-test, one-way ANOVA or repeated-measures ANOVA. (Which test is being done depends on how targets and chunks have been assigned). The resulting t or F value is then converted to a z-score, resulting in an "uncorrected" z-map. "uncorrected" here means not corrected for multiple comparisons.
b) the uncorrected z-map is converted to a TFCE map.
c) null TFCE maps are generated in the same way as in steps (a) and (b), but with permuted data.
d) a corrected p-map is computed based on the original TFCE map from (b), and the null maps in (c), by computing, for each feature, how often its TFCE value (in (b)) is smaller than the maximum TFCE value across the null maps in (c). This is then divided by the number of iterations to get a corrected p-map.
e) the p-map is converted to a corrected z-map, mainly to make visualization easier - so that effects of interest (with a small - i.e. significant effect) having a large absolute z-score.
I hope that clarifies things, please let us know if you have more questions.
Heath Matheson
Apr 1, 2016, 9:16:53 AM4/1/16
to Nick Oosterhof, CoSMoMVPA, alexisper...@gmail.com
Hi,
Yes that does! Perfect. Thanks a lot.
Just for interest sake (and because I am trying to learn about TFCE and permutations), could you generate a TFCE map at the very end (i.e. after permutations and getting z values)? (Maybe this is too loaded a question to write out, but I am interested in any tips or thoughts you may have).
Heath
--
Heath E Matheson PhD
Postdoctoral Fellow
Postdoctoral Fellow
Center for Cognitive Neuroscience
University of Pennsylvania
3720 Walnut Street
Philadelphia, PA
Philadelphia, PA
19104-6241
Nick Oosterhof
Apr 1, 2016, 9:22:22 AM4/1/16
to Heath Matheson, CoSMoMVPA, alexisper...@gmail.com
> On 01 Apr 2016, at 15:16, Heath Matheson <heatheri...@gmail.com> wrote:
>
> Yes that does! Perfect. Thanks a lot.
> Just for interest sake (and because I am trying to learn about TFCE and permutations), could you generate a TFCE map at the very end (i.e. after permutations and getting z values)?
Heath Matheson
Apr 1, 2016, 9:36:39 AM4/1/16
to Nick Oosterhof, CoSMoMVPA, alexisper...@gmail.com
That is my intuition on that too! Great!
(I just downloaded Daria's recent JoCN paper-- Cosmo in action!)
Heath
Reply all
Reply to author
Forward
0 new messages