Round-up of the first Little Schemer book club meeting
123 views
Skip to first unread message

Tom Stuart
Jan 21, 2014, 6:44:28 PM1/21/14
to computa...@googlegroups.com
Hi all,
Here's a quick summary of what happened at Monday's inaugural meeting of the Little Schemer book club, which was formed to continue the momentum of the Understanding Computation book club.
Roughly 20 people showed up, and we began by discussing chapter 1 of The Little Schemer. A few people said they'd found the book's style difficult to understand because of its technical vagueness, although it wasn't clear whether this was the majority view. There was some confusion about what programming language (if any) is actually being described, given the footnotes containing disclaimers and real-world syntax for users of Lisp and Scheme. However, there was general enthusiasm for the challenge/response format of the book, as well as for the idea of us trying to build a Scheme interpreter in Ruby based on the "tests" it contains.
We then talked a bit about how the Scheme language separates cleanly into "brackety notation for hierarchical data structures" and "rules for evaluating hierarchical data structures", and discussed how we could collectively make practical progress towards building an interpreter.
Then, because there were so many people in the room, we split into four independent groups to build stuff:
* @thattommyhall et al partially implemented a Scheme parser using Treetop: https://github.com/thattommyhall/littleT-J
* @threedaymonk et al implemented a recursive descent parser, along with a Graphviz visusaliser for the resulting abstract syntax trees: https://gist.github.com/threedaymonk/8528281
* @bishboria et al implemented a recursive descent parser too: https://gist.github.com/bishboria/8544144
* @chrislowis et al partially implemented an AST evaluator: https://gist.github.com/chrislo/8543385
As a result, we now almost have the pieces of a Scheme interpreter that can handle some of chapter 1 (syntax, `car`, `cdr`). We just need to polish those pieces and connect them together.
Here are some ideas for self-contained things that anyone could work on between now and the next meeting if they were sufficiently interested:
* Make the Treetop parser build an abstract syntax tree. The grammar's rules (https://github.com/thattommyhall/littleT-J/blob/master/scheme.treetop) are correct, but right now the parser generates a concrete syntax tree which contains too much irrelevant information. The trick is to put an inline method definition (see http://treetop.rubyforge.org/semantic_interpretation.html) on the `list` and `atom` rules so that we can call some method (e.g. `to_ast`) on the root node of the concrete syntax tree to convert it into an abstract one. There's an example of this on pages 58-62 of Understanding Computation, which you can download from http://computationbook.com/sample.
* Disregarding the visualisation code, the recursive descent parser from @threedaymonk's group looks longer and more complicated than the one from @bishboria's group. Can it be made simpler? (I don't know.)
* Wrap up the top-level parsing methods from @bishboria's group in a nice Parser class so that the state can be stored in an instance variable instead of the $EXPR global.
* Make the evaluator from @chrislowis's group pass its tests. They began to change the representation of S-expressions (from `[:cdr, :l]` to `List.new(Atom.new(:cdr), Atom.new(:l))`) but ran out of time. Is the #evaluate function correct, and can it be improved? (FWIW, I don't believe that `(car (a b c))` is meant to evaluate to `a`.)
* The parser from @threedaymonk's group supports the idea of parsing a _program_, i.e. a whitespace-separated sequence of S-expressions. Add this feature to one or both of the other parsers.
* Once the evaluator is working, combine it with one of the parsers to build a working interpreter, and get it to pass some tests adapted from the book. If you don't want to spend time transcribing tests, @jgwhite has already put some minitest tests online at https://github.com/jgwhite/little-schemer/blob/master/little_scheme_test.rb, and I've put some RSpec examples at https://github.com/tomstuart/little_scheme/blob/chapter-one/spec/01_toys_spec.rb.
Does anyone else have any ideas for fun stuff to try?
I really enjoyed the meeting and was incredibly impressed by the level of enthusiasm and the amount of progress that got made in such a relatively short time. Thanks everyone. Looking forward to the next one!
Cheers,
-Tom
Here's a quick summary of what happened at Monday's inaugural meeting of the Little Schemer book club, which was formed to continue the momentum of the Understanding Computation book club.
Roughly 20 people showed up, and we began by discussing chapter 1 of The Little Schemer. A few people said they'd found the book's style difficult to understand because of its technical vagueness, although it wasn't clear whether this was the majority view. There was some confusion about what programming language (if any) is actually being described, given the footnotes containing disclaimers and real-world syntax for users of Lisp and Scheme. However, there was general enthusiasm for the challenge/response format of the book, as well as for the idea of us trying to build a Scheme interpreter in Ruby based on the "tests" it contains.
We then talked a bit about how the Scheme language separates cleanly into "brackety notation for hierarchical data structures" and "rules for evaluating hierarchical data structures", and discussed how we could collectively make practical progress towards building an interpreter.
Then, because there were so many people in the room, we split into four independent groups to build stuff:
* @thattommyhall et al partially implemented a Scheme parser using Treetop: https://github.com/thattommyhall/littleT-J
* @threedaymonk et al implemented a recursive descent parser, along with a Graphviz visusaliser for the resulting abstract syntax trees: https://gist.github.com/threedaymonk/8528281
* @bishboria et al implemented a recursive descent parser too: https://gist.github.com/bishboria/8544144
* @chrislowis et al partially implemented an AST evaluator: https://gist.github.com/chrislo/8543385
As a result, we now almost have the pieces of a Scheme interpreter that can handle some of chapter 1 (syntax, `car`, `cdr`). We just need to polish those pieces and connect them together.
Here are some ideas for self-contained things that anyone could work on between now and the next meeting if they were sufficiently interested:
* Make the Treetop parser build an abstract syntax tree. The grammar's rules (https://github.com/thattommyhall/littleT-J/blob/master/scheme.treetop) are correct, but right now the parser generates a concrete syntax tree which contains too much irrelevant information. The trick is to put an inline method definition (see http://treetop.rubyforge.org/semantic_interpretation.html) on the `list` and `atom` rules so that we can call some method (e.g. `to_ast`) on the root node of the concrete syntax tree to convert it into an abstract one. There's an example of this on pages 58-62 of Understanding Computation, which you can download from http://computationbook.com/sample.
* Disregarding the visualisation code, the recursive descent parser from @threedaymonk's group looks longer and more complicated than the one from @bishboria's group. Can it be made simpler? (I don't know.)
* Wrap up the top-level parsing methods from @bishboria's group in a nice Parser class so that the state can be stored in an instance variable instead of the $EXPR global.
* Make the evaluator from @chrislowis's group pass its tests. They began to change the representation of S-expressions (from `[:cdr, :l]` to `List.new(Atom.new(:cdr), Atom.new(:l))`) but ran out of time. Is the #evaluate function correct, and can it be improved? (FWIW, I don't believe that `(car (a b c))` is meant to evaluate to `a`.)
* The parser from @threedaymonk's group supports the idea of parsing a _program_, i.e. a whitespace-separated sequence of S-expressions. Add this feature to one or both of the other parsers.
* Once the evaluator is working, combine it with one of the parsers to build a working interpreter, and get it to pass some tests adapted from the book. If you don't want to spend time transcribing tests, @jgwhite has already put some minitest tests online at https://github.com/jgwhite/little-schemer/blob/master/little_scheme_test.rb, and I've put some RSpec examples at https://github.com/tomstuart/little_scheme/blob/chapter-one/spec/01_toys_spec.rb.
Does anyone else have any ideas for fun stuff to try?
I really enjoyed the meeting and was incredibly impressed by the level of enthusiasm and the amount of progress that got made in such a relatively short time. Thanks everyone. Looking forward to the next one!
Cheers,
-Tom

James Mead
Jan 21, 2014, 7:02:05 PM1/21/14
to computa...@googlegroups.com
I've got the evaluator to pass the tests using the Atom & List classes that we introduced towards the end of the evening. I'm sure there's a lot more we could do to refactor the code, but at least it's now in a more self-consistent state.
Cheers, James.
Tom Stuart
Jan 21, 2014, 7:14:41 PM1/21/14
to computa...@googlegroups.com
On Tuesday, January 21, 2014 11:44:28 PM UTC, Tom Stuart wrote:
Does anyone else have any ideas for fun stuff to try?
One idea I forgot:
* Refactor one or both of the recursive descent parsers into a separate tokeniser and parser. The tokeniser's job is to split up the source string into a series of tokens (e.g. [Token.new(:left_bracket, '('), Token.new(:identifier, 'car'), Token.new(:identifier, 'l'), Token.new(:right_bracket, ')')] or however you choose to represent them (hashes, two-element arrays, different classes for different types of token...)), thereby encapsulating boring concerns like "what characters can an identifier contain" and "when should we ignore whitespace" etc, so that the parser can consume those nice clean tokens instead of having to touch the string directly. This is covered on pages 125-128 of Understanding Computation if you have a copy.
Cheers,
-Tom
Tom Stuart
Jan 22, 2014, 8:50:46 AM1/22/14
to computa...@googlegroups.com
On Tuesday, January 21, 2014 11:44:28 PM UTC, Tom Stuart wrote:
Does anyone else have any ideas for fun stuff to try?
Here’s another idea, stolen from something @jgwhite said on Monday:
* Our interpreter uses a big-step semantics: we make one call to an `#evaluate` function and it recursively evaluates the entire S-expression to give a final result. Is it possible to write an interpreter that uses a small-step semantics instead? In other words, could we repeatedly call a `#reduce` function to gradually “boil down” an initial S-expression to a final result via a series of intermediate S-expressions? I assume this is possible, not least because R6RS gives a small-step semantics for Scheme (http://www.r6rs.org/final/html/r6rs/r6rs-Z-H-15.html), but I haven’t thought about it at all. What should the steps look like when you repeatedly reduce, say, `(car (cdr (l))` where `l` is `(a b c)`? How do you know when to stop reducing?
Cheers,
-Tom

Murray Steele
Jan 22, 2014, 9:41:37 AM1/22/14
to Tom Stuart, computa...@googlegroups.com
Not having read UC yet, is it asinine to suggest you stop when:
s-exp == reduce(s-exp)
?
--
You received this message because you are subscribed to the Google Groups "Understanding Computation discussion" group.
To unsubscribe from this group and stop receiving emails from it, send an email to computationbo...@googlegroups.com.
For more options, visit https://groups.google.com/groups/opt_out.
Tom Stuart
Jan 22, 2014, 9:47:26 AM1/22/14
to Murray Steele, computa...@googlegroups.com
On 22 Jan 2014, at 14:41, Murray Steele <murray...@gmail.com> wrote:
> is it asinine to suggest you stop when:
>
> s-exp == reduce(s-exp)
>
> ?
Not if it works! The usual formal setup is to declare that certain kinds of syntax are irreducible — i.e. values — and to keep reducing until you reach one of those (see pages 25-28 of http://computationbook.com/sample), but that doesn't necessarily have to be the case here.
> is it asinine to suggest you stop when:
>
> s-exp == reduce(s-exp)
>
> ?
On the other hand, for what S-expressions would `s-exp == reduce(s-exp)` hold? (Depends on the definition of `reduce`.)
Cheers,
-Tom

Tim Cowlishaw
Jan 23, 2014, 11:55:59 AM1/23/14
to Tom Stuart, Murray Steele, computa...@googlegroups.com
Hi all!
Really sorry I didn't make the first meeting. I'm really enjoying
seeing everyone else's code on here though!
One question though, I've been having a crack at an implementation
following Tom's specs [1], however, I'm using Treetop [2] to define
the parser. I've noticed noone else is doing the same thing - am I
flagrantly cheating by doing so?
[1] https://github.com/tomstuart/little_scheme
[2] http://treetop.rubyforge.org/
Cheers,
Tim.
Really sorry I didn't make the first meeting. I'm really enjoying
seeing everyone else's code on here though!
One question though, I've been having a crack at an implementation
following Tom's specs [1], however, I'm using Treetop [2] to define
the parser. I've noticed noone else is doing the same thing - am I
flagrantly cheating by doing so?
[1] https://github.com/tomstuart/little_scheme
[2] http://treetop.rubyforge.org/
Cheers,
Tim.
Tom Stuart
Jan 23, 2014, 12:02:27 PM1/23/14
to Tim Cowlishaw, computa...@googlegroups.com
On 23 Jan 2014, at 16:55, Tim Cowlishaw <t...@timcowlishaw.co.uk> wrote:
> I've been having a crack at an implementation
> following Tom's specs [1], however, I'm using Treetop [2] to define
> the parser. I've noticed noone else is doing the same thing - am I
> flagrantly cheating by doing so?
Not at all. That's what one of the groups did at the meeting too (https://github.com/thattommyhall/littleT-J).
> I've been having a crack at an implementation
> following Tom's specs [1], however, I'm using Treetop [2] to define
> the parser. I've noticed noone else is doing the same thing - am I
> flagrantly cheating by doing so?
I think the people who built recursive descent parsers were just interested in how to do it from scratch instead of using Treetop, but other people just wanted to get the parser out of the way or ignore it completely. :)
Cheers,
-Tom

Jamie White
Jan 23, 2014, 12:08:50 PM1/23/14
to Tom Stuart, Tim Cowlishaw, computa...@googlegroups.com
I’ve still stuck on “how do you know when to stop reducing?”
is it when reduce(s-exp) == s-exp?
or when you hit a quoted s-expression?
but then, the book hasn't defined what it means to be `quoted` yet, so…
Cheers,
-Tom
--
You received this message because you are subscribed to the Google Groups "Understanding Computation discussion" group.
To unsubscribe from this group and stop receiving emails from it, send an email to computationbo...@googlegroups.com.
For more options, visit https://groups.google.com/groups/opt_out.
Tom Stuart
Jan 23, 2014, 12:15:50 PM1/23/14
to Jamie White, computa...@googlegroups.com
On 23 Jan 2014, at 17:08, Jamie White <ja...@jgwhite.co.uk> wrote:
> I’ve still stuck on “how do you know when to stop reducing?”
Yeah, it's not clear to me either. My vague guess is that we'd have to say something like "when you hit a value" and then define values as various kinds of S-expression: numbers, lists whose first atom is `quote` (which, yes, the book hasn't explained yet), etc.
> I’ve still stuck on “how do you know when to stop reducing?”
And then there's the question of what you do with the S-expression once you've stopped reducing it. If you've stopped reduction at `(quote (a b c))` then that means the final result is `(a b c)`, right? But if you've stopped at `42`, that means the result is just `42`. So there's some mysterious mapping required to get the output of `#reduce` to agree with `#evaluate`, but I don't know how to justify its existence.
Cheers,
-Tom
Tom Stuart
Jan 23, 2014, 1:07:46 PM1/23/14
to Jamie White, computa...@googlegroups.com
> On 23 Jan 2014, at 17:43, Jamie White <ja...@jgwhite.co.uk> wrote:
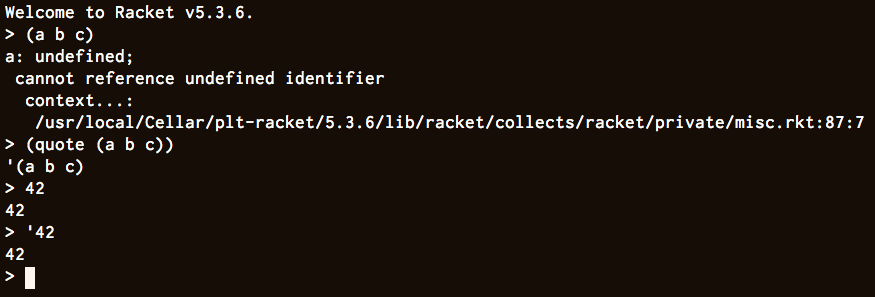
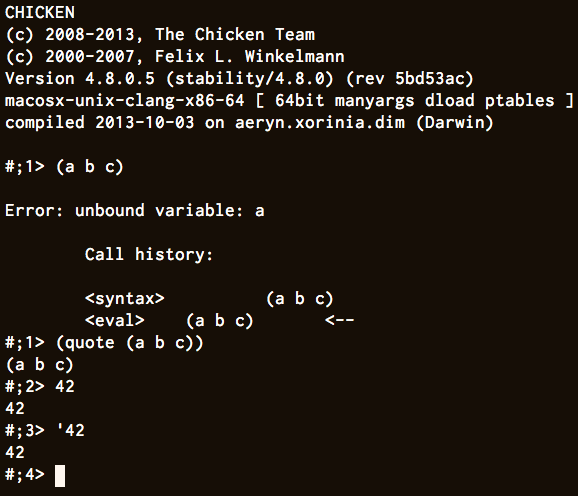
> I thought I’d ask Racket and Chicken, but they don’t seem to exactly agree. Then again, maybe it’s just their REPLs?
I think it is the REPL, because it has to make a choice about how to render an S-expression as a string.
> I thought I’d ask Racket and Chicken, but they don’t seem to exactly agree. Then again, maybe it’s just their REPLs?
In the book's parlance, what do you expect `(cdr (quote (a b c)))` to evaluate to? My answer would be `(b c)`, i.e. the S-expression that is a list containing two atoms called "b" and "c", but I suspect Racket would tell you that `(cdr (quote (a b c)))` evaluates to `(quote (b c))`, aka `'(b c)`, because that's how it's decided to show you a literal list.
So I think it depends how you choose to represent the results of evaluation, but I don't think the intended result is actually different.
Cheers,
-Tom
Reply all
Reply to author
Forward
0 new messages