| | 
Dear friends of the Singularity Institute, This month marks the biggest shift in our operations since the Singularity Summit was founded in 2006. Now that Singularity University has acquired the Singularity Summit (details below), and SI’s interests in rationality training are being developed by the now-separate Center for Applied Rationality, the Singularity Institute is making a major transition. For 12 years we’ve largely focused on movement-building — through the Singularity Summit, Less Wrong, and other programs. This work was needed to build up a community of support for our mission and a pool of potential researchers for our unique interdisciplinary work. Now, the time has come to say “Mission Accomplished Well Enough to Pivot to Research.” Our community of supporters is now large enough that qualified researchers are available for us to hire, if we can afford to hire them. Having published 30+ research papers and dozens more original research articles on Less Wrong, we certainly haven’t neglected research. But in 2013 we plan to pivot so that a much larger share of the funds we raise is spent on research. If you’d like to help with that, please contribute to our ongoing fundraising drive. Onward and upward, Luke |
Singularity Summit Conference Acquired by Singularity University
 The Singularity Summit conference, founded by SI in 2006, has been acquired from SI by Singularity University. As part of the agreement, the Singularity Institute will change its name (to reduce brand confusion), but will remain as co-producers of the Singularity Summit in some succeeding years. We are pleased that we can transition the conference to an organization with a strong commitment to maintaining its quality as it grows. The Singularity Summit conference, founded by SI in 2006, has been acquired from SI by Singularity University. As part of the agreement, the Singularity Institute will change its name (to reduce brand confusion), but will remain as co-producers of the Singularity Summit in some succeeding years. We are pleased that we can transition the conference to an organization with a strong commitment to maintaining its quality as it grows.
Most of the funds from the Summit acquisition will be placed in a separate fund for a “Friendly AI team,” and therefore does not support our daily operations or other programs. We wish to thank everyone who participated in making the Singularity Summit a success, especially past SI president Michael Vassar (now with Panacea Research) and Summit organizer Amy Willey. |
2012 Winter Matching Challenge!
We’re excited to announce our 2012 Winter Matching Challenge. Thanks to the generosity of several major donors, every donation to the Singularity Institute made now until January 5th, 2013 will be matched dollar-for-dollar, up to a total of $115,000! Now is your chance to double your impact while helping us raise up to $230,000 to help fund our research program. Note that the new Center for Applied Rationality (CFAR) will be running a separate fundraiser soon. Please read our blog post for the challenge for more details, including our accomplishments throughout the last year and our plans for the next 6 months. Please support our transition from a movement-building phase into a research phase. |
A Week of Friendly AI Math at the Singularity Institute
From Nov. 11th-17th, SI held a Friendly AI math workshop at our headquarters in Berkeley, California. The participants — Eliezer Yudkowsky, Marcello Herreshoff, Paul Christiano, and Mihaly Barasz — tackled a particular problem related to Friendly AI. We held the workshop mostly to test hypotheses about ideal team size and the problem’s tractability, while allowing there was some small chance the team would achieve a significant result in just one week. Happily, it seems the team did achieve a significant result, which the participants estimate would be the equivalent of 1-3 papers if published. More details are forthcoming. |
SI’s Turing Prize Awarded to Bill Hibbard for “Avoiding Unintended AI Behaviors”

This year’s AGI-12 conference, held in Oxford UK, included a special track on AGI Impacts. A selection of papers from this track will be published in a special volume of the Journal of Experimental & Theoretical Artificial Intelligence in 2013.
The Singularity Institute had previously announced a $1000 prize for the best paper from AGI-12 or AGI Impacts on the question of how to develop safe architectures or goals for AGI. At the event, the prize was awarded to Bill Hibbard for his paper Avoiding Unintended AI Behaviors. SI’s Turing Prize is awarded in honor of Alan Turing, who not only discovered some of the key ideas of machine intelligence, but also grasped its importance, writing that “…it seems probable that once [human-level machine thinking] has started, it would not take long to outstrip our feeble powers… At some stage therefore we should have to expect the machines to take control…” The prize is awarded for work that not only increases awareness of this important problem, but also makes technical progress in addressing it. SI researcher Carl Shulman also presented at AGI Impacts. You can read the abstract of his talk, “Could we use untrustworthy human brain emulations to make trustworthy ones?”, here. If video of the talk becomes available later, we’ll link to it in a future newsletter. |
New Paper: How We’re Predicting AI — or Failing To
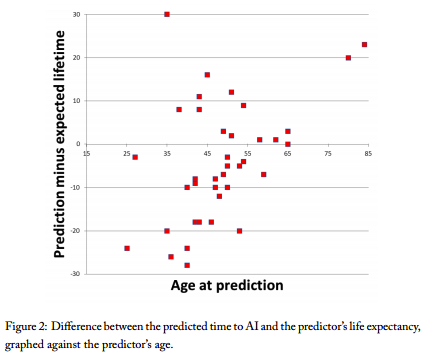
The new paper by Stuart Armstrong (FHI) and Kaj Sotala (SI) has now been published (PDF) as part of the Beyond AI conference proceedings. Some of these results were previously discussed here. The original predictions data are available here. The Less Wrong thread is here. We thank Stuart and Kaj for this valuable meta-study of AI predictions. For the study, Stuart Armstrong and Kaj Sotala examined a database of 257 AI predictions, made in a period spanning from the 1950s to the present day. This database was assembled by researchers from the Singularity Institute (Jonathan Wang and Brian Potter) systematically searching though the literature. 95 of these are considered AI timeline predictions. The paper examines a couple folk theories of AI prediction, the “Maes-Garreau law” (that people predict AI happening near the end of their own lifetime) and the prediction that “AI is always 15-25 years into the future”. Systematic analysis of the database of AI predictions revealed support for the second theory but not the first. Many of the predictions were concentrated around 15-25 years in the future, and this trend held whether the predictions were being made in the 1950s or the 2000s. Predictions were not observed to cluster around the expected end of lifetime of the predictors, a result which contradicts the Maes-Garreau hypothesis. It was also found that the predictions of experts do not correlate in any distinct way relative to non-experts; i.e., there seems to be little evidence that experts make better AI predictions than non-experts. At Singularity Summit 2012, Stuart Armstrong summarized the results of the study in an onstage talk. The major take-away from this study is that predicting the arrival of human-level AI is such a fuzzy endeavor that we should take any prediction with a large grain of salt. The rational approach is to widen our confidence intervals — that is, recognize that we don’t really know when human-level AI will be developed, and make plans accordingly. Just as we cannot confidently state that AI is near, we can’t confidently state that AI is far off. (This was also the conclusion of an earlier Singulairty Institute publication, “Intelligence Explosion: Evidence and Import.”) |
Michael Anissimov Publishes Responses to P.Z. Myers and Kevin Kelly

SI media director Michael Anissimov has published blog posts responding tobiologist P.Z. Myers on whole brain emulation and bestselling author Kevin Kelly on AI takeoff. In a blog post, P.Z. Myers rejected the idea of whole brain emulation in general, stating “It won’t work. It can’t.” However, his response focuses on the scanning of a live brain with current technology. In response, Anissimov concedes that Myers’ criticisms make sense in the narrow context in which he makes them, but his response misunderstands that whole brain emulation refers to a wide range of possible scanning approaches, not just the reductionistic straw man of “scan in, emulation out”. So, while Myers’ critique applies to certain types of brain scanning approaches, it does not apply to whole brain emulation in general. Anissimov’s response to Kevin Kelly is a response to a blog post from four years ago, “Thinkism.” Kelly’s blog post is notable as one of the most substantive critiques of the fast AI takeoff idea by a prominent intellectual. Kelly argues that the idea of scientific and technological research and development occurring more rapidly than “calendar time” is incredulous, because there are inherently time-limited processes, such as cellular metabolism, which limit progress on difficult research problems, namely indefinitely extending human healthspans. Anissimov argues that faster-than-human, smarter-than-human intelligence could overcome the human-characteristic rate of innovation through superior insight, breaking problems into their constituent parts, and by making experimentation massively accelerated and parallel. |
Original Research on Less Wrong

SI executive director Luke Muehlhauser, with help from our research team, has compiled a list of original research produced by the web community Less Wrong. Though many of the posts on Less Wrong are summaries of previously published research, there is also a substantial amount of original expert material in philosophy, decision theory, mathematical logic, and other fields. Examples of original research on Less Wrong include Eliezer Yudkowsky’s “Highly Advanced Epistemology 101 for Beginners” sequence, Wei Dai’s posts on his original decision theory (UDT), Vladimir Nesov’s thoughts on counterfactual mugging, and Benja Fallstein’s investigation of the problem of logical uncertainty. In all, the list compiles over 50 examples of original research on Less Wrong stretching from 2008 to the present. Of particular interest is original research that contributes towardssolving open problems in Friendly AI. Original research on Less Wrong continues to be pursued in several discussion threads on the site. |
How Can I Reduce Existential Risk From AI?

Another recent Less Wrong post of note by Luke Muehlhauser is “How can I reduce existential risk from AI?” “Existential risk”, a term coined by Oxford philosopher Nick Bostrom, specifically refers to risks to the survival of the human species. The Singularity Institute argues that advanced artificial intelligence is an existential risk to the future of the human species. “Existential risk” generally refers to the total destruction of the human species, rather than risks which threaten 90% or 99% of the population, which would constitute global catastrophic risks but not true existential risks. Since our founding in 2000, the Singularity Institute has argued that smarter-than-human, self-improving Artificial Intelligence is an existential risk to humanity. The concern is that, at some point over the next hundred years, advanced AI will be created that can manufacture its own sophisticated robotics and threaten to displace human civilization, not necessarily through deliberate action but merely as a side-effect of the exploitation of resources required for our survival, such as carbon, oxygen, or physical space. For additional background, please read our concise summary, “Reducing Long-Term Catastrophic Risks from Artificial Intelligence”. The post outlines three major categories of work towards reducing AI risk: (1) meta-work, such as making money to contribute to Friendly AI research; (2) strategic work, work towards a better strategic understanding of the challenges we face; and (3) direct work, such as technical research, political action, or particular kinds of technological development. All three are crucial to building the “existential risk mitigation ecosystem,” a cooperative effort of hundreds of people to better understand AI risk and do something about it. |
New Research Associates
The Singularity Institute is pleased to announce four new research associates, Benja Fallenstein, Marcello Herreshoff, Mihaly Barasz, and Bill Hibbard. Benja Fallenstein is interested in the basic research necessary for the development of safe AI goals, especially from the perspective of mathematical models of evolutionary psychology, and also in anthropic reasoning, decision theory, game theory, reflective mathematics, and programming languages with integrated proof checkers. Benja is a mathematics student at University of Vienna, with a focus in biomathematics. Marcello Herreshoff has worked with the Singularity Institute on the math of Friendly AI, from time to time since 2007. In High School, he was a two time USACO finalist and he published a novel combinatorics result, which he presented at the Twelfth International Conference on Fibonacci Numbers and Their Applications. He holds a BA in Math from Stanford University. At Stanford he was awarded two honorable mentions on the Putnam mathematics competition, and submitted his honors thesis for publication in the Logic Journal of the IGPL. His research interests include mathematical logic, and in its use in formalizing coherent goal systems. Mihaly Barasz is interested in functional languages and type theory and their application in formal proof systems. He cares deeply about reducing existential risks. He has an M.Sc. summa cum laude in Mathematics from Eotvos Lorand University, Budapest and currently works at Google. Bill Hibbard is an Emeritus Senior Scientist at the University of Wisconsin-Madison Space Science and Engineering Center, currently working on issues of AI safety and unintended behaviors. He has a BA in Mathematics and MS and PhD in Computer Sciences, all from the University of Wisconsin-Madison. |
AI Risk-Related Improvements to the LW Wiki

The Singularity Institute has greatly improved the Less Wrong wiki with new entries, featuring topics from Seed AI to moral uncertainty and more. Over 120 pages were updated in total. The improvements to the wiki were prompted by earlier proposals for a dedicated scholarly AI risk wiki. The improvements to the wiki enable more background knowledge for publishing short, clear, scholarly articles on AI risk. Some articles of interest include the 5-and-10 problem, AGI skepticism, AGI Sputnik moment, AI advantages, AI takeoff, basic AI drives, benevolence, biological cognitive enhancement, Coherent Extrapolated Volition, computing overhang, computronium,differential intellectual progress, economic consequences of AI and whole brain emulation, Eliezer Yudkowsky, emulation argument for human-level AI, extensibility argument for greater-than-human intelligence, evolutionary argument for human-level AI, complexity of human value, Friendly artificial intelligence, Future of Humanity Institute, history of AI risk thought, intelligence explosion, moral divergence, moral uncertainty, Nick Bostrom, optimal philanthropy, optimization process, Oracle AI,orthogonality thesis, paperclip maximizer, Pascal’s mugging, recursive self-improvement, reflective decision theory, singleton, Singularitarianism, Singularity,subgoal stomp, superintelligence, terminal value, timeless decision theory, tool AI,utility extraction, value extrapolation, value learning, and whole brain emulation. |
Featured Volunteer: Ethan Dickinson
This month, we thank Ethan Dickinson for his volunteer work transcribing videos from the Singularity Summit 2012 conference. When we talked with Ethan about his work, he mentioned how one talk, Julia Galef’s (embedded below), even inspired a teary-eyed emotional climax. Ethan became involved in volunteer work for SI after several years of developing an increasing interest in rationality, originally introduced via Harry Potter and the Methods of Rationality. Today, he feels he is using the full powers of his imagination to understand the Singularity. Paraphrasing Jaan Tallin, he has used his own reading of science fiction such as William Gibson’s Neuromancer and Isaac Asimov’s novels to imagine worlds “much more optimistic and much more pessimistic” than many of the middle ground scenarios for the future widely assumed today. |
Featured Summit Video: Julia Galef on Rationality
[Link.] Four decades of cognitive science have confirmed that Homo sapiens are far from “rational animals.” Scientists have amassed a daunting list of ways that our brain’s fast-and-frugal judgment heuristics fail in modern contexts for which they weren’t adapted, or stymie our attempts to be happy and effective. Hence the project we’re undertaking at the new Center for Applied Rationality (CFAR) — training human brains to run algorithms that optimize for our interests as autonomous beings in the modern world, not for the interests of ancient replicators. This talk explores what we’ve learned from that process so far, and why training smart people to be rational decision-makers is crucial to a better future. |
|

{kind=link}
{kind=link}