Error in commoncrawl.py of newsplease library
369 views
Skip to first unread message

Parteek Rajvats
Jul 12, 2020, 11:10:53 PM7/12/20
to Common Crawl
hello all, 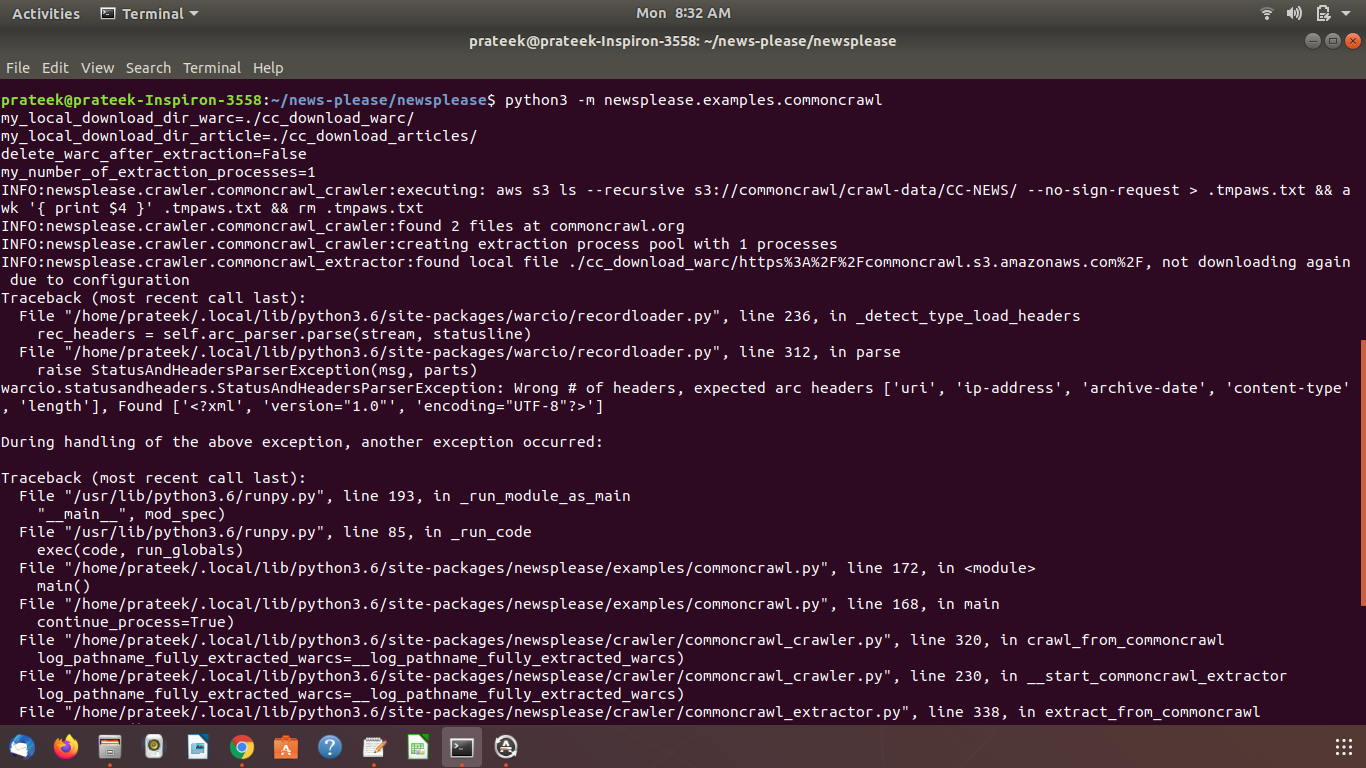

i am using python newsplease's commoncrawl functionality to get news articles from commoncrawl datasets. newsplease provides a file commoncrawl.py that downloads warc files and extracts news articles from them.
i am facing an exception in when i run that file.
i am attaching screenshoots of terminal showing errors.
please look in these snapshots and try to suggest me a solution.
i have single python installed in my stystem.
i have also atteched all commoncral related files from newsplease here.
commoncrawl.py is the file that i need to run for doing this thing according to newsplease github page.
these two more files i have attached that that are related to commoncrawl and get used in commoncrawl.py
commoncrawl_crawler.py and commoncrawl_extractor.py

Sebastian Nagel
Jul 13, 2020, 4:37:32 AM7/13/20
to common...@googlegroups.com
Hi,
the name of the local file logged immediately before the error:
INFO:newsplease.crawler.commoncrawl_extractor:found local file ./cc_download_warc/https%3A%2F%2Fcommoncrawl.s3.amazonaws.com%2F, not
downloading again due to configuration
could be an indicator you're trying to process the XML-listing show if the URL
https://commoncrawl.s3.amazonaws.com/
is fetched. This is not a WARC but an XML file
<?xml version="1.0" encoding="UTF-8"?>
<ListBucketResult ...
which fits with the logged exceptions:
warcio.exceptions.ArchiveLoadFailed: Unknown archive format, first line: ['<?xml', 'version="1.0"', 'encoding="UTF-8"?>']
No glue why this URL was downloaded to a local file,
- move it away to be able to continue
- news-please, of course, could skip over files it fails to parse as WARC files
only reporting them
Best,
Sebastian
On 7/13/20 5:10 AM, Parteek Rajvats wrote:
> hello all,
> i am using python newsplease's commoncrawl functionality to get news articles from commoncrawl datasets. newsplease provides a file
> commoncrawl.py that downloads warc files and extracts news articles from them.
> i am facing an exception in when i run that file.
> i am attaching screenshoots of terminal showing errors.
> Screenshot from 2020-07-13 08-32-32.pngScreenshot from 2020-07-13 08-32-57.png
> *
> *
>
> --
> You received this message because you are subscribed to the Google Groups "Common Crawl" group.
> To unsubscribe from this group and stop receiving emails from it, send an email to common-crawl...@googlegroups.com
> <mailto:common-crawl...@googlegroups.com>.
> To view this discussion on the web visit
> https://groups.google.com/d/msgid/common-crawl/eb02241c-2624-4ce4-a8d1-079f5c2fb2c7n%40googlegroups.com
> <https://groups.google.com/d/msgid/common-crawl/eb02241c-2624-4ce4-a8d1-079f5c2fb2c7n%40googlegroups.com?utm_medium=email&utm_source=footer>.
the name of the local file logged immediately before the error:
INFO:newsplease.crawler.commoncrawl_extractor:found local file ./cc_download_warc/https%3A%2F%2Fcommoncrawl.s3.amazonaws.com%2F, not
downloading again due to configuration
could be an indicator you're trying to process the XML-listing show if the URL
https://commoncrawl.s3.amazonaws.com/
is fetched. This is not a WARC but an XML file
<?xml version="1.0" encoding="UTF-8"?>
<ListBucketResult ...
which fits with the logged exceptions:
warcio.exceptions.ArchiveLoadFailed: Unknown archive format, first line: ['<?xml', 'version="1.0"', 'encoding="UTF-8"?>']
No glue why this URL was downloaded to a local file,
- move it away to be able to continue
- news-please, of course, could skip over files it fails to parse as WARC files
only reporting them
Best,
Sebastian
On 7/13/20 5:10 AM, Parteek Rajvats wrote:
> hello all,
> i am using python newsplease's commoncrawl functionality to get news articles from commoncrawl datasets. newsplease provides a file
> commoncrawl.py that downloads warc files and extracts news articles from them.
> i am facing an exception in when i run that file.
> i am attaching screenshoots of terminal showing errors.
>
> please look in these snapshots and try to suggest me a solution.
> i have single python installed in my stystem.
> i have also atteched all commoncral related files from newsplease here.
> *commoncrawl.py *is the file that i need to run for doing this thing according to newsplease github page.
> please look in these snapshots and try to suggest me a solution.
> i have single python installed in my stystem.
> i have also atteched all commoncral related files from newsplease here.
> these two more files i have attached that that are related to commoncrawl and get used in commoncrawl.py
> *commoncrawl_crawler.py and commoncrawl_extractor.py*
> *
> *
>
> --
> You received this message because you are subscribed to the Google Groups "Common Crawl" group.
> To unsubscribe from this group and stop receiving emails from it, send an email to common-crawl...@googlegroups.com
> <mailto:common-crawl...@googlegroups.com>.
> To view this discussion on the web visit
> https://groups.google.com/d/msgid/common-crawl/eb02241c-2624-4ce4-a8d1-079f5c2fb2c7n%40googlegroups.com
> <https://groups.google.com/d/msgid/common-crawl/eb02241c-2624-4ce4-a8d1-079f5c2fb2c7n%40googlegroups.com?utm_medium=email&utm_source=footer>.
Parteek Rajvats
Jul 16, 2020, 5:36:17 AM7/16/20
to Common Crawl
Hi,
above mentioned error has been solved. problem was with the latest versions of the libraries used in newsplease. now i installed all python packages that are mentioned in requirement.txt file and it is working fine now..
start_date = '2020-03-01 00:00:00'
end_date = '2020-03-20 06:00:00'
i have another question now.
i want to download warc files of specific time interval only.
eg -
start_date = '2020-03-01 00:00:00'
end_date = '2020-03-20 06:00:00'
end_date = '2020-03-20 06:00:00'
this time duration has 2 or 3 warc files only.
i want news data that was crawl in these 6 hours only.
changes that i made for this -
this is in commoncrawl_crawler.py file -
warc_dates = __iterate_by_month(warc_files_start_date, datetime.datetime.today())
warc_dates = __iterate_by_month(warc_files_start_date, datetime.datetime(2020,3,21))
warc_dates = __iterate_by_month(warc_files_start_date, datetime.datetime(2020,3,21))
this is in both config.cfg and config_lib.cfg -
start_date = '2020-03-01 00:00:00'
end_date = '2020-03-20 06:00:00'
this is commoncrawl_extractor.py -
_filter_start_date = None
__filter_start_date = datetime.datetime(2020, 3, 1)
# end date (if None, any date is OK as end date)
__filter_end_date = None
__filter_end_date =datetime.datetime(2020, 3, 20)
__filter_start_date = datetime.datetime(2020, 3, 1)
# end date (if None, any date is OK as end date)
__filter_end_date = None
__filter_end_date =datetime.datetime(2020, 3, 20)
this is in commoncrawl.py -
# if date filtering is strict and news-please could not detect the date of an article, the article will be discarded
my_warc_files_start_date = datetime.datetime(2020, 3, 1)
my_warc_files_start_date = datetime.datetime(2020, 3, 1)
after making this changes it is still want to download all 441 warc files of march 2020. which results in "no space left on disk" warning.
these are the changes i made. i think most of this change are limited to article filter process.
what are the changes required to download limited warc files ?
Reply all
Reply to author
Forward
0 new messages