Strategies for building a corpus using common crawl data
309 views
Skip to first unread message

D.C Hilliard
May 27, 2022, 6:59:40 PM5/27/22
to Common Crawl
Hello,
I am a historian doing work on anti-vaccination in Canada since the 1980s. I am hoping to use distant reading (LDA topic modelling and Network Analysis) to talk about the more recent history and to try and push some analysis into COVID.
I have the topic modelling and Network analysis tools figured out with sample corpora. But I am having some problems creating my own corpus.
I have a few related questions.
1) How do I extract a domain (eg.vaccinechoicecanada.com) from a crawl? It is feasible to store and manipulate the data locally? Is using the .CDX to find the file and then extracting the relevant the best way. Should I only extract .WAT and .WET files for the textual and hyperlink analysis ... would I lose valuable pertinent information not using the WARC.
I am a historian doing work on anti-vaccination in Canada since the 1980s. I am hoping to use distant reading (LDA topic modelling and Network Analysis) to talk about the more recent history and to try and push some analysis into COVID.
I have the topic modelling and Network analysis tools figured out with sample corpora. But I am having some problems creating my own corpus.
I have a few related questions.
1) How do I extract a domain (eg.vaccinechoicecanada.com) from a crawl? It is feasible to store and manipulate the data locally? Is using the .CDX to find the file and then extracting the relevant the best way. Should I only extract .WAT and .WET files for the textual and hyperlink analysis ... would I lose valuable pertinent information not using the WARC.
2) Do you have any suggestions for curating sites to include beyond starting with current sites (vaccinechoicecanada.com, nvic.org etc. etc.) and keyword searching for current sites that pertain to the subject in the now ... Should I use hyperlinks to slowly build out my own corpora (and automate this process using code)?

Sebastian Nagel
May 30, 2022, 9:53:11 AM5/30/22
to common...@googlegroups.com
Hi,
first, let me note that there are dedicated COVID-19 web archives, eg.
https://netpreserve.org/events/iipc-cdg-collection-novel-coronavirus-outbreak/
https://www.bac-lac.gc.ca/eng/about-us/about-collection/Pages/documenting-2020-covid-19-pandemic.aspx
It may be worth to look at these focused collections first.
But I do not know whether anti-vaccination sites are included.
A curated collection could be quite different than Common Crawl's
broad sampling approach.
> It is feasible to store and manipulate the data locally? Is using the
> .CDX to find the file and then extracting the relevant the best way.
You only need to fetch the WARC records you're interested in using the
WARC record offset and length, not the entire WARC files. The CDX index
is good to extract the WARC record "coordinates" except you want to do
this for thousands or millions of sites: then a table join on the
columnar index is definitely faster.
> 2) Do you have any suggestions for curating sites to include beyond
> starting with current sites (vaccinechoicecanada.com, nvic.org etc.
One approach could be to look into the webgraphs to find sites
either referencing or being referenced from these domains.
Let me know if you need help for any of the described steps.
Best,
Sebastian
first, let me note that there are dedicated COVID-19 web archives, eg.
https://netpreserve.org/events/iipc-cdg-collection-novel-coronavirus-outbreak/
https://www.bac-lac.gc.ca/eng/about-us/about-collection/Pages/documenting-2020-covid-19-pandemic.aspx
It may be worth to look at these focused collections first.
But I do not know whether anti-vaccination sites are included.
A curated collection could be quite different than Common Crawl's
broad sampling approach.
> It is feasible to store and manipulate the data locally? Is using the
> .CDX to find the file and then extracting the relevant the best way.
WARC record offset and length, not the entire WARC files. The CDX index
is good to extract the WARC record "coordinates" except you want to do
this for thousands or millions of sites: then a table join on the
columnar index is definitely faster.
> 2) Do you have any suggestions for curating sites to include beyond
> starting with current sites (vaccinechoicecanada.com, nvic.org etc.
either referencing or being referenced from these domains.
Let me know if you need help for any of the described steps.
Best,
Sebastian
D.C Hilliard
May 30, 2022, 5:28:40 PM5/30/22
to Common Crawl
Thanks for the reply,
I will definitely be using the dedicated archival material, and hoping to get access to LAC's private WARCs for part of this project, though I am planning to use Common Crawl to help fill in some of the gaps for anti-vaccination sites, especially.
As for using the graph, I think that would be a good place to start and will begin there. It was something I had stumbled upon and decided to pursue, so it's good to know that this would be one way to begin identifying more sites.
I will definitely be using the dedicated archival material, and hoping to get access to LAC's private WARCs for part of this project, though I am planning to use Common Crawl to help fill in some of the gaps for anti-vaccination sites, especially.
As for using the graph, I think that would be a good place to start and will begin there. It was something I had stumbled upon and decided to pursue, so it's good to know that this would be one way to begin identifying more sites.
I am not familiar with the columnar index, or how to manipulate it at scale. Could you explain how to do this using cc-pyspark? I have browsed some of the example code and am having a bit of trouble identifying where I would input the domain(s) to query the index once I have a list of domains via the webgraph.
Best,
Derek
Sebastian Nagel
Jun 2, 2022, 7:54:48 AM6/2/22
to common...@googlegroups.com
Hi Derek,
> As for using the graph, I think that would be a good place to start
> and will begin there.
You could use PyWebGraph [1] to explore the graphs, see [2].
> I am not familiar with the columnar index, or how to manipulate it at
> scale. Could you explain how to do this using cc-pyspark?
If possible, I'd recommend to use Athena to do a bulk lookup of host or
domain names, cf. [3,4]. You can use Spark later to download or process
the WARC records of all the pages you're interested in.
> where I would input the domain(s) to query the index once I have a
> list of domains via the webgraph.
There are a couple of options, see [4].
Best,
Sebastian
[1] https://github.com/mapio/py-web-graph
[2]
https://github.com/commoncrawl/cc-notebooks/blob/main/cc-webgraph-statistics/interactive_webgraph.md
[3]
https://github.com/commoncrawl/cc-index-table/blob/main/src/sql/examples/cc-index/count-domains-alexa-top-1m.sql
[4]
https://github.com/commoncrawl/cc-notebooks/blob/main/cc-index-table/bulk-url-lookups-by-table-joins.ipynb
On 5/30/22 23:28, D.C Hilliard wrote:
> Thanks for the reply,
>
> I will definitely be using the dedicated archival material, and hoping
> to get access to LAC's private WARCs for part of this project, though I
> am planning to use Common Crawl to help fill in some of the gaps for
> anti-vaccination sites, especially.
>
> As for using the graph, I think that would be a good place to start and
> will begin there. It was something I had stumbled upon and decided to
> pursue, so it's good to know that this would be one way to begin
> identifying more sites.
>
> I am not familiar with the columnar index, or how to manipulate it at
> scale. Could you explain how to do this using cc-pyspark? I have browsed
> some of the example code and am having a bit of trouble identifying
> where I would input the domain(s) to query the index once I have a list
> of domains via the webgraph.
>
> Best,
>
> Derek
>
> On Monday, May 30, 2022 at 7:53:11 AM UTC-6 Sebastian Nagel wrote:
>
> Hi,
>
> first, let me note that there are dedicated COVID-19 web archives, eg.
>
> https://netpreserve.org/events/iipc-cdg-collection-novel-coronavirus-outbreak/
> <https://netpreserve.org/events/iipc-cdg-collection-novel-coronavirus-outbreak/>
>
>
> https://www.bac-lac.gc.ca/eng/about-us/about-collection/Pages/documenting-2020-covid-19-pandemic.aspx
> As for using the graph, I think that would be a good place to start
> and will begin there.
> I am not familiar with the columnar index, or how to manipulate it at
> scale. Could you explain how to do this using cc-pyspark?
domain names, cf. [3,4]. You can use Spark later to download or process
the WARC records of all the pages you're interested in.
> where I would input the domain(s) to query the index once I have a
> list of domains via the webgraph.
Best,
Sebastian
[1] https://github.com/mapio/py-web-graph
[2]
https://github.com/commoncrawl/cc-notebooks/blob/main/cc-webgraph-statistics/interactive_webgraph.md
[3]
https://github.com/commoncrawl/cc-index-table/blob/main/src/sql/examples/cc-index/count-domains-alexa-top-1m.sql
[4]
https://github.com/commoncrawl/cc-notebooks/blob/main/cc-index-table/bulk-url-lookups-by-table-joins.ipynb
On 5/30/22 23:28, D.C Hilliard wrote:
> Thanks for the reply,
>
> I will definitely be using the dedicated archival material, and hoping
> to get access to LAC's private WARCs for part of this project, though I
> am planning to use Common Crawl to help fill in some of the gaps for
> anti-vaccination sites, especially.
>
> As for using the graph, I think that would be a good place to start and
> will begin there. It was something I had stumbled upon and decided to
> pursue, so it's good to know that this would be one way to begin
> identifying more sites.
>
> I am not familiar with the columnar index, or how to manipulate it at
> scale. Could you explain how to do this using cc-pyspark? I have browsed
> some of the example code and am having a bit of trouble identifying
> where I would input the domain(s) to query the index once I have a list
> of domains via the webgraph.
>
> Best,
>
> Derek
>
> On Monday, May 30, 2022 at 7:53:11 AM UTC-6 Sebastian Nagel wrote:
>
> Hi,
>
> first, let me note that there are dedicated COVID-19 web archives, eg.
>
> https://netpreserve.org/events/iipc-cdg-collection-novel-coronavirus-outbreak/
>
>
> https://www.bac-lac.gc.ca/eng/about-us/about-collection/Pages/documenting-2020-covid-19-pandemic.aspx
> <https://www.bac-lac.gc.ca/eng/about-us/about-collection/Pages/documenting-2020-covid-19-pandemic.aspx>
>
> It may be worth to look at these focused collections first.
> But I do not know whether anti-vaccination sites are included.
> A curated collection could be quite different than Common Crawl's
> broad sampling approach.
>
> > It is feasible to store and manipulate the data locally? Is using the
> > .CDX to find the file and then extracting the relevant the best way.
>
> You only need to fetch the WARC records you're interested in using the
> WARC record offset and length, not the entire WARC files. The CDX index
> is good to extract the WARC record "coordinates" except you want to do
> this for thousands or millions of sites: then a table join on the
> columnar index is definitely faster.
>
> > 2) Do you have any suggestions for curating sites to include beyond
> > starting with current sites (vaccinechoicecanada.com
> <http://vaccinechoicecanada.com>, nvic.org <http://nvic.org> etc.
>
> It may be worth to look at these focused collections first.
> But I do not know whether anti-vaccination sites are included.
> A curated collection could be quite different than Common Crawl's
> broad sampling approach.
>
> > It is feasible to store and manipulate the data locally? Is using the
> > .CDX to find the file and then extracting the relevant the best way.
>
> You only need to fetch the WARC records you're interested in using the
> WARC record offset and length, not the entire WARC files. The CDX index
> is good to extract the WARC record "coordinates" except you want to do
> this for thousands or millions of sites: then a table join on the
> columnar index is definitely faster.
>
> > 2) Do you have any suggestions for curating sites to include beyond
> > starting with current sites (vaccinechoicecanada.com
>
> One approach could be to look into the webgraphs to find sites
> either referencing or being referenced from these domains.
>
>
> Let me know if you need help for any of the described steps.
>
>
> Best,
> Sebastian
>
> On 5/28/22 00:59, D.C Hilliard wrote:
> > Hello,
> >
> > I am a historian doing work on anti-vaccination in Canada since the
> > 1980s. I am hoping to use distant reading (LDA topic modelling and
> > Network Analysis) to talk about the more recent history and to try
> and
> > push some analysis into COVID.
> >
> > I have the topic modelling and Network analysis tools figured out
> with
> > sample corpora. But I am having some problems creating my own corpus.
> >
> > I have a few related questions.
> >
> > 1) How do I extract a domain (eg.vaccinechoicecanada.com
> <http://eg.vaccinechoicecanada.com>) from a crawl?
> One approach could be to look into the webgraphs to find sites
> either referencing or being referenced from these domains.
>
>
> Let me know if you need help for any of the described steps.
>
>
> Best,
> Sebastian
>
> On 5/28/22 00:59, D.C Hilliard wrote:
> > Hello,
> >
> > I am a historian doing work on anti-vaccination in Canada since the
> > 1980s. I am hoping to use distant reading (LDA topic modelling and
> > Network Analysis) to talk about the more recent history and to try
> and
> > push some analysis into COVID.
> >
> > I have the topic modelling and Network analysis tools figured out
> with
> > sample corpora. But I am having some problems creating my own corpus.
> >
> > I have a few related questions.
> >
> > 1) How do I extract a domain (eg.vaccinechoicecanada.com
> > It is feasible to store and manipulate the data locally? Is using the
> > .CDX to find the file and then extracting the relevant the best way.
> > Should I only extract .WAT and .WET files for the textual and
> hyperlink
> > analysis ... would I lose valuable pertinent information not using
> the WARC.
> >
> > 2) Do you have any suggestions for curating sites to include beyond
> > starting with current sites (vaccinechoicecanada.com
> <http://vaccinechoicecanada.com>, nvic.org <http://nvic.org> etc.
> > .CDX to find the file and then extracting the relevant the best way.
> > Should I only extract .WAT and .WET files for the textual and
> hyperlink
> > analysis ... would I lose valuable pertinent information not using
> the WARC.
> >
> > 2) Do you have any suggestions for curating sites to include beyond
> > starting with current sites (vaccinechoicecanada.com
D.C Hilliard
Jun 9, 2022, 12:58:10 PM6/9/22
to Common Crawl
Hi Sebastian,
I am having a little trouble building the webgraphs. I am able to create the offsets etc.
The problem comes when building py-web-graph I am able to clone everything but run into a few issues.
Caused by: java.lang.ClassNotFoundException: org.python.util.jython
Derek
I am having a little trouble building the webgraphs. I am able to create the offsets etc.
The problem comes when building py-web-graph I am able to clone everything but run into a few issues.
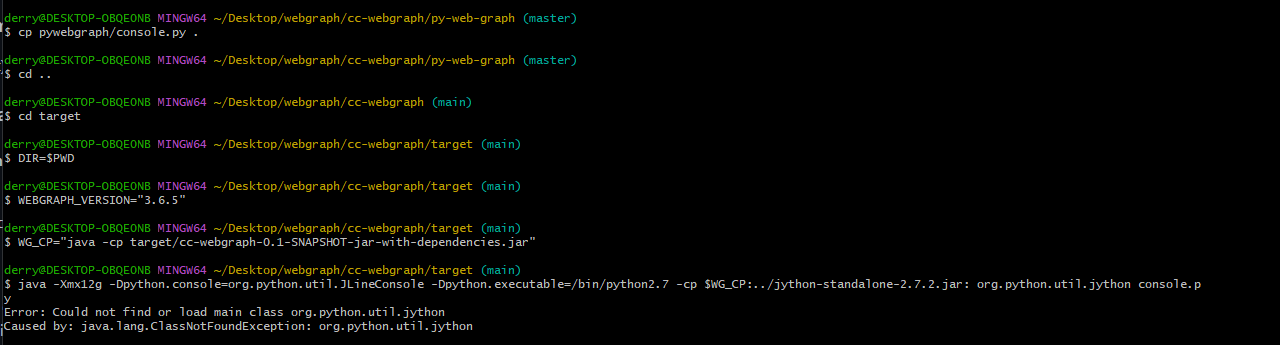
First, following the first and second notebook I am running into a couple errors here:
When I input the final command $ java -Xmx12g -Dpython.console=org.python.util.JLineConsole -Dpython.executable=/Python27 -cp $WG_CP\;../jython-standalone-2.7.2.jar\; org.python.util.jython console.py
I receive this:
Error: Could not find or load main class org.python.util.jythonI receive this:
Caused by: java.lang.ClassNotFoundException: org.python.util.jython
I did some work getting around that but when the application launches it immediately runs into issues with "Immutable Graphs" is not defined when I input the graph command.
Any ideas?
Best,
Derek

{kind=link}
{kind=link}
{kind=link}
{kind=link}
Richard Hill
Jun 10, 2022, 4:15:36 AM6/10/22
to Common Crawl
First of all I am not an expert regarding cc-webgraph so I could be wrong about this.
It looks like jython is not on your Java classpath. You are using windows when the tool was developed and documented for use with linux , its sometimes more difficult to configure an env this way because the path is less trodden. I would install the WSL on your machine and use linux. There is a lot of code written in shell https://github.com/commoncrawl/cc-webgraph
You are also using a snapshot version of cc-webgraph according to the bash.png, couldn't you be using a release version?
It looks like jython is not on your Java classpath. You are using windows when the tool was developed and documented for use with linux , its sometimes more difficult to configure an env this way because the path is less trodden. I would install the WSL on your machine and use linux. There is a lot of code written in shell https://github.com/commoncrawl/cc-webgraph
You are also using a snapshot version of cc-webgraph according to the bash.png, couldn't you be using a release version?
Sebastian Nagel
Jun 10, 2022, 11:30:01 AM6/10/22
to common...@googlegroups.com
Hi Derek, hi Richard,
there is an error in the description [1]: instead of
WG_CP="java -cp
target/cc-webgraph-0.1-SNAPSHOT-jar-with-dependencies.jar"
the classpath element must be
WG_CP="target/cc-webgraph-0.1-SNAPSHOT-jar-with-dependencies.jar"
I'll fix the description asap. But I do not know whether this is the
reason for the problem. It depends whether the java executable allows
for multiple "-cp" arguments.
Other points (see the "bash.png" screenshot):
- you'd need to remove "target/" if you're already in the directory "target"
- make sure that the jython jar is found on
../jython-standalone-2.7.2.jar - in doubt, use an absolute path
> You are also using a snapshot version of cc-webgraph according to
> the bash.png, couldn't you be using a release version?
There was never a release of the cc-webgraph project, even no change of
the 0.1 version. But good idea, I'll do a release latest together with
the next webgraph release. Thanks for the suggestion, Richard!
Indeed, in the beginning it was shell only, just a wrapper to call the
webgraph tools. The Java classes and bundling was added later.
Sorry, again. I'll review the description (also the notebook) over the
weekend. And yes, setting up Jython isn't easy at all. I still hope
to use the Python bindings of JGraphT [2] which added support for the
webgraph formats as an replacement. See [3].
Best,
Sebastian
[1]
https://github.com/commoncrawl/cc-notebooks/blob/main/cc-webgraph-statistics/interactive_webgraph.md
[2] https://jgrapht.org/
[3] https://github.com/commoncrawl/cc-notebooks/issues/3
> I did some work getting around that *but when the application
> > <http://vaccinechoicecanada.com
> <http://vaccinechoicecanada.com>>, nvic.org
> <http://nvic.org> <http://nvic.org <http://nvic.org>> etc.
> <http://vaccinechoicecanada.com>>, nvic.org
> <http://nvic.org> <http://nvic.org <http://nvic.org>> etc.
> You received this message because you are subscribed to the Google
> Groups "Common Crawl" group.
> To unsubscribe from this group and stop receiving emails from it, send
> an email to common-crawl...@googlegroups.com
> <mailto:common-crawl...@googlegroups.com>.
> To view this discussion on the web visit
> https://groups.google.com/d/msgid/common-crawl/91c8e982-f770-4486-b8fb-be7063670901n%40googlegroups.com
> <https://groups.google.com/d/msgid/common-crawl/91c8e982-f770-4486-b8fb-be7063670901n%40googlegroups.com?utm_medium=email&utm_source=footer>.
there is an error in the description [1]: instead of
WG_CP="java -cp
target/cc-webgraph-0.1-SNAPSHOT-jar-with-dependencies.jar"
the classpath element must be
WG_CP="target/cc-webgraph-0.1-SNAPSHOT-jar-with-dependencies.jar"
I'll fix the description asap. But I do not know whether this is the
reason for the problem. It depends whether the java executable allows
for multiple "-cp" arguments.
Other points (see the "bash.png" screenshot):
- you'd need to remove "target/" if you're already in the directory "target"
- make sure that the jython jar is found on
../jython-standalone-2.7.2.jar - in doubt, use an absolute path
> You are also using a snapshot version of cc-webgraph according to
> the bash.png, couldn't you be using a release version?
the 0.1 version. But good idea, I'll do a release latest together with
the next webgraph release. Thanks for the suggestion, Richard!
Indeed, in the beginning it was shell only, just a wrapper to call the
webgraph tools. The Java classes and bundling was added later.
Sorry, again. I'll review the description (also the notebook) over the
weekend. And yes, setting up Jython isn't easy at all. I still hope
to use the Python bindings of JGraphT [2] which added support for the
webgraph formats as an replacement. See [3].
Best,
Sebastian
[1]
https://github.com/commoncrawl/cc-notebooks/blob/main/cc-webgraph-statistics/interactive_webgraph.md
[2] https://jgrapht.org/
[3] https://github.com/commoncrawl/cc-notebooks/issues/3
> launches it immediately runs into issues with "Immutable Graphs"
> is not defined when I input the graph command. *
> <http://vaccinechoicecanada.com>>, nvic.org
> <http://nvic.org> <http://nvic.org <http://nvic.org>> etc.
> >
> > One approach could be to look into the webgraphs to find
> sites
> > either referencing or being referenced from these domains.
> >
> >
> > Let me know if you need help for any of the described steps.
> >
> >
> > Best,
> > Sebastian
> >
> > On 5/28/22 00:59, D.C Hilliard wrote:
> > > Hello,
> > >
> > > I am a historian doing work on anti-vaccination in
> Canada since the
> > > 1980s. I am hoping to use distant reading (LDA topic
> modelling and
> > > Network Analysis) to talk about the more recent history
> and to try
> > and
> > > push some analysis into COVID.
> > >
> > > I have the topic modelling and Network analysis tools
> figured out
> > with
> > > sample corpora. But I am having some problems creating
> my own corpus.
> > >
> > > I have a few related questions.
> > >
> > > 1) How do I extract a domain (eg.vaccinechoicecanada.com
> <http://eg.vaccinechoicecanada.com>
> > <http://eg.vaccinechoicecanada.com
> > One approach could be to look into the webgraphs to find
> sites
> > either referencing or being referenced from these domains.
> >
> >
> > Let me know if you need help for any of the described steps.
> >
> >
> > Best,
> > Sebastian
> >
> > On 5/28/22 00:59, D.C Hilliard wrote:
> > > Hello,
> > >
> > > I am a historian doing work on anti-vaccination in
> Canada since the
> > > 1980s. I am hoping to use distant reading (LDA topic
> modelling and
> > > Network Analysis) to talk about the more recent history
> and to try
> > and
> > > push some analysis into COVID.
> > >
> > > I have the topic modelling and Network analysis tools
> figured out
> > with
> > > sample corpora. But I am having some problems creating
> my own corpus.
> > >
> > > I have a few related questions.
> > >
> > > 1) How do I extract a domain (eg.vaccinechoicecanada.com
> <http://eg.vaccinechoicecanada.com>
> <http://eg.vaccinechoicecanada.com>>) from a crawl?
> > > It is feasible to store and manipulate the data locally?
> Is using the
> > > .CDX to find the file and then extracting the relevant
> the best way.
> > > Should I only extract .WAT and .WET files for the
> textual and
> > hyperlink
> > > analysis ... would I lose valuable pertinent information
> not using
> > the WARC.
> > >
> > > 2) Do you have any suggestions for curating sites to
> include beyond
> > > starting with current sites (vaccinechoicecanada.com
> <http://vaccinechoicecanada.com>
> > <http://vaccinechoicecanada.com
> > > It is feasible to store and manipulate the data locally?
> Is using the
> > > .CDX to find the file and then extracting the relevant
> the best way.
> > > Should I only extract .WAT and .WET files for the
> textual and
> > hyperlink
> > > analysis ... would I lose valuable pertinent information
> not using
> > the WARC.
> > >
> > > 2) Do you have any suggestions for curating sites to
> include beyond
> > > starting with current sites (vaccinechoicecanada.com
> <http://vaccinechoicecanada.com>
> <http://vaccinechoicecanada.com>>, nvic.org
> <http://nvic.org> <http://nvic.org <http://nvic.org>> etc.
> > > etc.) and keyword searching for current sites that
> pertain to the
> > > subject in the now ... Should I use hyperlinks to slowly
> build out my
> > > own corpora (and automate this process using code)?
> > >
> > >
> >
>
> --
> pertain to the
> > > subject in the now ... Should I use hyperlinks to slowly
> build out my
> > > own corpora (and automate this process using code)?
> > >
> > >
> >
>
> You received this message because you are subscribed to the Google
> Groups "Common Crawl" group.
> To unsubscribe from this group and stop receiving emails from it, send
> an email to common-crawl...@googlegroups.com
> <mailto:common-crawl...@googlegroups.com>.
> To view this discussion on the web visit
> https://groups.google.com/d/msgid/common-crawl/91c8e982-f770-4486-b8fb-be7063670901n%40googlegroups.com
> <https://groups.google.com/d/msgid/common-crawl/91c8e982-f770-4486-b8fb-be7063670901n%40googlegroups.com?utm_medium=email&utm_source=footer>.
D.C Hilliard
Jun 10, 2022, 1:12:22 PM6/10/22
to Common Crawl
Success!
Thanks to both of you for the help. I really appreciate this.
D
Reply all
Reply to author
Forward
0 new messages