Access Content Inside of the each GZ file
283 views
Skip to first unread message

Uzair Nouman
Jun 2, 2022, 6:41:19 AM6/2/22
to Common Crawl
Hi,
I am Uzair working on common crawl data. I want to get the news related data from the common crawl. As we now that each warc file have thousands of gz files. Each gz file have almost 1 GB of size (contain 80% raw data).
currently I have a script i run my script on dgx server to get news related data from GZ file but the problem is that it took almost 6 to 7 weeks to download the 1 month of the clean data from crawl data.
but we need to download one decade of news related data just in 4 months.
Suggest me alternate ways to extract clean data fastly..
is that possible can we get the inside of the content of the gz file using AWS athena queries??
I am Uzair working on common crawl data. I want to get the news related data from the common crawl. As we now that each warc file have thousands of gz files. Each gz file have almost 1 GB of size (contain 80% raw data).
currently I have a script i run my script on dgx server to get news related data from GZ file but the problem is that it took almost 6 to 7 weeks to download the 1 month of the clean data from crawl data.
but we need to download one decade of news related data just in 4 months.
Suggest me alternate ways to extract clean data fastly..
is that possible can we get the inside of the content of the gz file using AWS athena queries??
OR any other alternative way...
kindly expert suggest me how i can get my meaning ful data from inside the gz file.
kindly expert suggest me how i can get my meaning ful data from inside the gz file.

Sebastian Nagel
Jun 2, 2022, 7:32:18 AM6/2/22
to common...@googlegroups.com
Hi Usair,
> is that possible can we get the inside of the content of the gz file
> using AWS athena queries??
Yes, you can look up the WARC record positions for even a huge list of
URLs or sites (host or domain name) very quickly. Once you have the list
of WARC records, you need to send one request per record. But this job
can be parallelized, and will be sufficiently fast if you run it on an
AWS EC2 instance in the us-east-1 region where the data is located.
The basic ideas are described in
https://github.com/commoncrawl/cc-notebooks/blob/main/cc-index-table/bulk-url-lookups-by-table-joins.ipynb
> but we need to download one decade of news related data just in 4
> months.
Did you have a look at
https://commoncrawl.org/2016/10/news-dataset-available/
(however, a decade is not yet covered)
Best,
Sebastian
> is that possible can we get the inside of the content of the gz file
> using AWS athena queries??
URLs or sites (host or domain name) very quickly. Once you have the list
of WARC records, you need to send one request per record. But this job
can be parallelized, and will be sufficiently fast if you run it on an
AWS EC2 instance in the us-east-1 region where the data is located.
The basic ideas are described in
https://github.com/commoncrawl/cc-notebooks/blob/main/cc-index-table/bulk-url-lookups-by-table-joins.ipynb
> but we need to download one decade of news related data just in 4
> months.
https://commoncrawl.org/2016/10/news-dataset-available/
(however, a decade is not yet covered)
Best,
Sebastian
Uzair Nouman
Jun 3, 2022, 7:07:01 AM6/3/22
to Common Crawl
Hi Sebastian Nagel,
Hope you are fine & doing great. Thanks for your reply to my recent email.
I am doing it in the same way that you mentioned. like we are using threads in our script for parallelism.
But how I can do this fastly using an EC2 instance?
But how I can do this fastly using an EC2 instance?
I have an account on AWS. I have an EC2 instance. when I deployed my script (same script running on DGX) ec2 instance it was killed within 3 to 4 minutes. IDK why the script is killed. I think for less memory or due to fewer resources.
I have a t2.micro EC2 instance. my EC2 instance is in the us-east-1 region.
kindly share in steps (points) how I can Extract data Efficiently/fastly using the AWS EC2.
Thanks & Regards,
Muhammad Uzair Noman
Sebastian Nagel
Jun 3, 2022, 7:32:32 AM6/3/22
to common...@googlegroups.com
Hi Uzair,
> I have a t2.micro EC2 instance.
This means you have only 1 GiB of RAM. It might be sufficient,
but you need to "economize" memory. And you hardly can do anything
else than fetching the WARC records, concatenate them and write
the resulting WARC files to S3 for later processing.
> IDK why the script is killed. I think for less memory or due to fewer
> resources.
Shouldn't this be visible in the log files?
In doubt, could you share the script or at least more context?
Best,
Sebastian
> I have a t2.micro EC2 instance.
but you need to "economize" memory. And you hardly can do anything
else than fetching the WARC records, concatenate them and write
the resulting WARC files to S3 for later processing.
> IDK why the script is killed. I think for less memory or due to fewer
> resources.
In doubt, could you share the script or at least more context?
Best,
Sebastian
Uzair Nouman
Jun 9, 2022, 6:41:50 AM6/9/22
to Common Crawl
Hi Sebastian Nagel,
Hope you are fine & doing great. Thanks for your reply to my recent email.
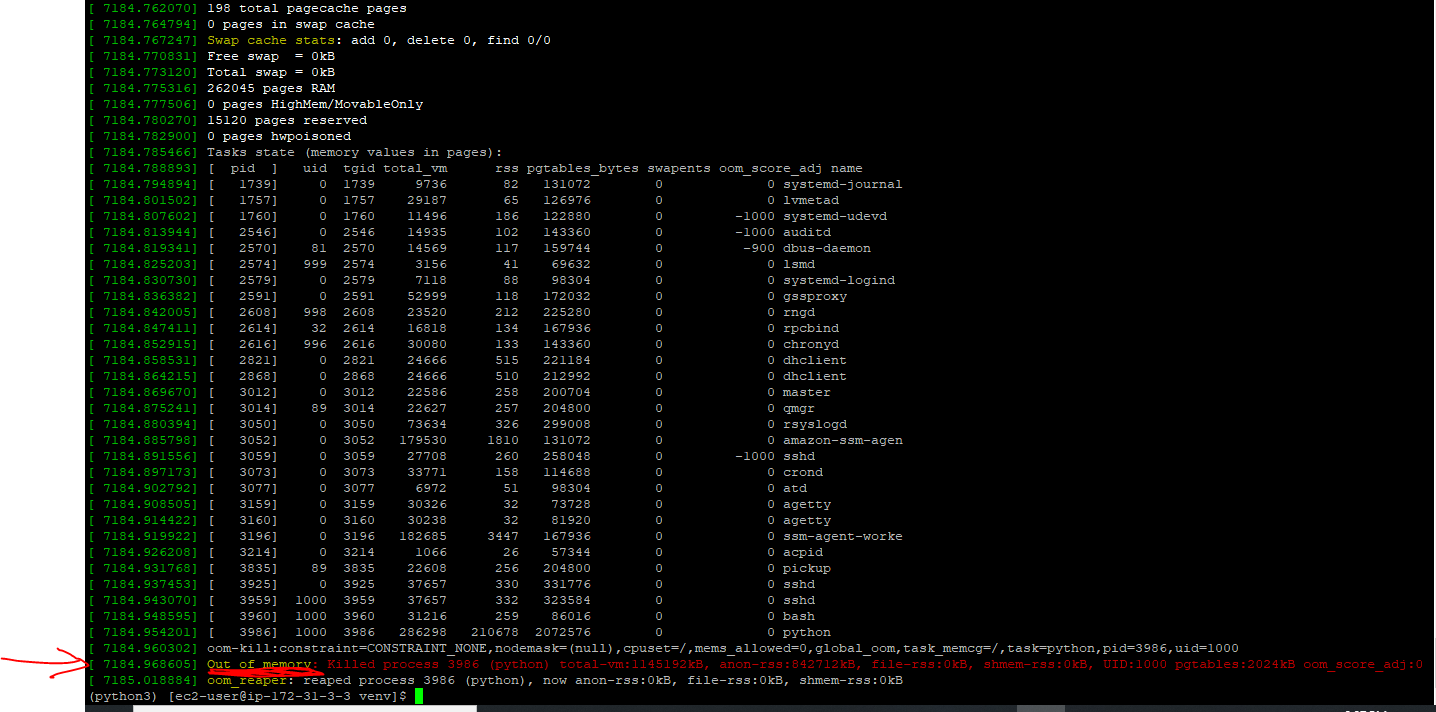
I have checked the logs on my EC2 instance. My script is killed due to the low amount of RAM. I am sharing logs of the EC2 instance kindly find the attachment.
and I know you are an Expert you know better about the AWS services & Common Crawl data.
According to that, kindly suggest to me the Best Ec2 instance for the processing of Common crawl Data efficiently, effectively & fastly for downloading the files.
and I know you are an Expert you know better about the AWS services & Common Crawl data.
According to that, kindly suggest to me the Best Ec2 instance for the processing of Common crawl Data efficiently, effectively & fastly for downloading the files.
Thanks & Regards,
Muhammad UZair Noman
{kind=link}
Sebastian Nagel
Jun 9, 2022, 7:07:16 AM6/9/22
to common...@googlegroups.com
Hi,
> According to that, kindly suggest to me the Best Ec2 instance for the
> processing of Common crawl Data efficiently, effectively & fastly for
> downloading the files.
If it's only about downloading and not processing, I'd use
memory-optimized ARM-based instances (r6g[d].xlarge for example) -
enough RAM
is required to buffer/cache the data. If you want to do any
CPU-intensive processing, compute-optimized or general-purpose instances
with less threads or parallel processes per instance may be the better
choice (eg. c6g[d].2xlarge or m6g[d].2xlarge).
For faster downloading: configure the S3 client not to use SSL:
boto3.client('s3', use_ssl=False)
Other options to optimize the fetching of WARC records are provided here:
https://code402.com/blog/s3-scans-vs-index/
Best,
Sebastian
> --
> You received this message because you are subscribed to the Google
> Groups "Common Crawl" group.
> To unsubscribe from this group and stop receiving emails from it, send
> an email to common-crawl...@googlegroups.com
> <mailto:common-crawl...@googlegroups.com>.
> To view this discussion on the web visit
> https://groups.google.com/d/msgid/common-crawl/5aeff6a0-a24e-4fb2-aaac-3fce9ab9c006n%40googlegroups.com
> <https://groups.google.com/d/msgid/common-crawl/5aeff6a0-a24e-4fb2-aaac-3fce9ab9c006n%40googlegroups.com?utm_medium=email&utm_source=footer>.
> According to that, kindly suggest to me the Best Ec2 instance for the
> processing of Common crawl Data efficiently, effectively & fastly for
> downloading the files.
memory-optimized ARM-based instances (r6g[d].xlarge for example) -
enough RAM
is required to buffer/cache the data. If you want to do any
CPU-intensive processing, compute-optimized or general-purpose instances
with less threads or parallel processes per instance may be the better
choice (eg. c6g[d].2xlarge or m6g[d].2xlarge).
For faster downloading: configure the S3 client not to use SSL:
boto3.client('s3', use_ssl=False)
Other options to optimize the fetching of WARC records are provided here:
https://code402.com/blog/s3-scans-vs-index/
Best,
Sebastian
> You received this message because you are subscribed to the Google
> Groups "Common Crawl" group.
> To unsubscribe from this group and stop receiving emails from it, send
> an email to common-crawl...@googlegroups.com
> <mailto:common-crawl...@googlegroups.com>.
> To view this discussion on the web visit
> https://groups.google.com/d/msgid/common-crawl/5aeff6a0-a24e-4fb2-aaac-3fce9ab9c006n%40googlegroups.com
> <https://groups.google.com/d/msgid/common-crawl/5aeff6a0-a24e-4fb2-aaac-3fce9ab9c006n%40googlegroups.com?utm_medium=email&utm_source=footer>.
Uzair Nouman
Jun 9, 2022, 7:31:07 AM6/9/22
to Common Crawl
Hi,
Thanks & Regards
Our Script work for both Downloading + processing.
First downloads the files then start the process on it and extract the meaningful data according to our need. Then make a new file of jsonl and remove the wrac/gz file.
First downloads the files then start the process on it and extract the meaningful data according to our need. Then make a new file of jsonl and remove the wrac/gz file.
kindly suggest according to both download + Process.
Thanks & Regards
Muhammad Uzair Noman
Uzair Nouman
Aug 2, 2022, 1:58:27 AM8/2/22
to Common Crawl
Hi CC Team,
We are working on Common Crawl data. we are trying to download the warc/gz file.
Our script is multi-threaded but we face an issue.
in single threads, the downloading speed is 2MB/file and if we run 100 threads the downloading speed is the same.
in single threads, the downloading speed is 2MB/file and if we run 100 threads the downloading speed is the same.
We discussed this with the DevOps team, they said the COmmon_Crawl team sets this bottleneck in the C_C S3 bucket.
one more thing is that Our script is running on DGX. Downloading speed on DGX is more than 400/Mbit.
if u have applied any speed limit and u can tell us about it would be help full for us.
Thanks & Regards,
Muhammad Uzair Noman
Data Engineer
Innovative Solution
Islamabad, Pakistan
Reply all
Reply to author
Forward
0 new messages