Using Spark to analyse WARC files

Andreiwid Sh. Corrêa

Ala Anvari
--
You received this message because you are subscribed to the Google Groups "Common Crawl" group.
To unsubscribe from this group and stop receiving emails from it, send an email to common-crawl...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/common-crawl/CANwgJutxzspHqnsRMzLccqXN%3DMpHEUC%2BOF4aR3ZTsTStNPmLjg%40mail.gmail.com.

Tom Morris
--

Sebastian Nagel
there is
https://github.com/commoncrawl/cc-pyspark
That's Python, obviously.
And yes, you can run the examples in a Spark cluster on AWS, eg. EMR.
I'm aware of the following projects using Java or Scala:
https://github.com/ntent/cc-scala
https://github.com/iproduct-database/vpm-filter-spark
https://github.com/Synerzip/CommonCrawl-Spark
But I hadn't a closer look on them, so no warranty! See also our list of examples and projects:
https://commoncrawl.org/the-data/examples/
Best,
Sebastian
> You received this message because you are subscribed to the Google Groups "Common Crawl" group.
> To unsubscribe from this group and stop receiving emails from it, send an email to common-crawl...@googlegroups.com
> https://groups.google.com/d/msgid/common-crawl/CANwgJutxzspHqnsRMzLccqXN%3DMpHEUC%2BOF4aR3ZTsTStNPmLjg%40mail.gmail.com

Basil Latif
I am doing a project to run Spark queries on the common crawl dataset in AWS.
I have looked closely at this link - https://github.com/commoncrawl/cc-pyspark. For the section for running on AWS, it explains some of the settings that need to be adjusted. How exactly is the sparkcc.py file listed in step 4 used in the spark deployment?
Right now, I am deploying an emr cluster with spark pre-installed. Then, I am running a Python AWS notebook that is linked to the cluster. I want to query the Crawl’s S3 bucket to run Spark queries. I have followed this link to query Common Crawl using AWS Athena. https://commoncrawl.org/2018/03/index-to-warc-files-and-urls-in-columnar-format/.
These readings also suggest that the crawl archives can also be accessed using Spark in a similar way to how Athena runs SQL queries on the crawl data using the parquet format.
What is the way to run Spark queries in a Jupyter notebook using this setup? If not, what is the other way to query the crawl data using EMR and Spark?

Sebastian Nagel
> How exactly is the sparkcc.py file listed in step 4 used in the spark deployment?
$SPARK_HOME/bin/spark-submit \
--conf ... \
... (other Spark options) \
--py-files sparkcc.py \
script.py \
... (script-specific options)
> These readings also suggest that the crawl archives can also be accessed using Spark in a
> similar way to how Athena runs SQL queries on the crawl data using the parquet format.
It's not possible to directly query on WARC files.
Best,
Sebastian

Jerome Banks
Hi Basil,
FYI, we’re developing a system in Spark, which uses SparkSQL to query the common crawl index. These results are then mapped to a task which does an HTTP range request to retrieve the WARC text from S3, and then uses the jwarc library to parse the actual text. This is all in Scala.
- jerome
--
You received this message because you are subscribed to the Google Groups "Common Crawl" group.
To unsubscribe from this group and stop receiving emails from it, send an email to common-crawl...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/common-crawl/2615619c-f1c2-7563-1305-30f9fc0ebddc%40commoncrawl.org.
Sebastian Nagel
is this system open source? I would then add it to the Common Crawl examples page. Thanks!
> in Scala.
Same in Python:
https://github.com/commoncrawl/cc-pyspark/blob/master/cc_index_word_count.py
~ Sebastian
On 5/26/20 9:02 PM, Jerome Banks wrote:
> Hi Basil,
>
> FYI, we’re developing a system in Spark, which uses SparkSQL to query the common crawl index. These results are then mapped to a task
> which does an HTTP range request to retrieve the WARC text from S3, and then uses the jwarc library to parse the actual text. This is all
> in Scala.
>
>
>
>
>
>
> *From: *<common...@googlegroups.com> on behalf of Sebastian Nagel <seba...@commoncrawl.org>
> *Reply-To: *"common...@googlegroups.com" <common...@googlegroups.com>
> *Date: *Tuesday, May 26, 2020 at 11:55 AM
> *To: *"common...@googlegroups.com" <common...@googlegroups.com>
> *Subject: *Re: [cc] Using Spark to analyse WARC files
>
>
> Hi Basil,
>
>> How exactly is the sparkcc.py file listed in step 4 used in the spark deployment?
>
> The easiest way is to add it directly via `--py-files`:
>
> $SPARK_HOME/bin/spark-submit \
> --conf ... \
> ... (other Spark options) \
> --py-files sparkcc.py \
> script.py \
> ... (script-specific options)
>
>
>> These readings also suggest that the crawl archives can also be accessed using Spark in a
>> similar way to how Athena runs SQL queries on the crawl data using the parquet format.
>
> The columnar index can be queried using SQL either from Athena, Spark or Hive.
> It's not possible to directly query on WARC files.
>
> Best,
> Sebastian
>
>
> On 5/26/20 3:50 AM, Basil Latif wrote:
>> Hi All,
>> I am doing a project to run Spark queries on the common crawl dataset in AWS.
>>
>> I have looked closely at this link - https://github.com/commoncrawl/cc-pyspark. For the section for running on AWS, it explains some of
> the settings that need to be adjusted. How exactly is the sparkcc.py file listed in step 4 used in the spark deployment?
>>
>>
>> Right now, I am deploying an emr cluster with spark pre-installed. Then, I am running a Python AWS notebook that is linked to the cluster.
> I want to query the Crawl’s S3 bucket to run Spark queries. I have followed this link to query Common Crawl using AWS Athena.
> https://commoncrawl.org/2018/03/index-to-warc-files-and-urls-in-columnar-format/
>> These readings also suggest that the crawl archives can also be accessed using Spark in a similar way to how Athena runs SQL queries on
> the crawl data using the parquet format.
>>
>> What is the way to run Spark queries in a Jupyter notebook using this setup? If not, what is the other way to query the crawl data using
> EMR and Spark?
>>
>
> --
> You received this message because you are subscribed to the Google Groups "Common Crawl" group.
> To unsubscribe from this group and stop receiving emails from it, send an email to common-crawl...@googlegroups.com.
> To view this discussion on the web visit https://groups.google.com/d/msgid/common-crawl/2615619c-f1c2-7563-1305-30f9fc0ebddc%40commoncrawl.org.
>
> --
> You received this message because you are subscribed to the Google Groups "Common Crawl" group.
> To unsubscribe from this group and stop receiving emails from it, send an email to common-crawl...@googlegroups.com
> <https://groups.google.com/d/msgid/common-crawl/F2E0F9E5-F5AF-46FB-B4B1-917716BCA859%40demandbase.com?utm_medium=email&utm_source=footer>.
Basil Latif
>> How exactly is the sparkcc.py file listed in step 4 used in the spark deployment?
>The easiest way is to add it directly via `--py-files`:
$SPARK_HOME/bin/spark-submit \
--conf ... \
... (other Spark options) \
--py-files sparkcc.py \
script.py \
... (script-specific options)
Is anything else needed in order to run a spark job on this file? What is the data source for this spark job?
>> These readings also suggest that the crawl archives can also be accessed using Spark in a similar way to how Athena runs SQL queries on the crawl data using the parquet format.
>The columnar index can be queried using SQL either from Athena, Spark or Hive.
It's not possible to directly query on WARC files.
s3://commoncrawl/cc-index/table/cc-main/warc/ in a Spark shell?
Regards,
Basil L
Jerome Banks
Sebastien,
Sorry, not currently open-source, but I’d like to if my employer would allow. We’re also investigating a Google Cloud Dataflow implementation, but we’re not sure about all the S3/AWS egress costs. I’ll keep the group posted.
- Jerome
From: <common...@googlegroups.com> on behalf of Sebastian Nagel <seba...@commoncrawl.org>
Reply-To: "common...@googlegroups.com" <common...@googlegroups.com>
Date: Tuesday, May 26, 2020 at 12:11 PM
To: "common...@googlegroups.com" <common...@googlegroups.com>
To view this discussion on the web visit https://groups.google.com/d/msgid/common-crawl/7a58f263-5cb3-39a7-61dc-ce04e39ad2de%40commoncrawl.org.
Sebastian Nagel
> What is the data source for this spark job?
https://github.com/commoncrawl/cc-pyspark#get-sample-data
Paths can point to local files (recommended for development) or
s3://commoncrawl/crawl-data/...
Every line should reference one single WARC/WAT/WET file.
Which format (WARC, WAT or WET) depends on "script.py".
"script.py" is just a place-holder for one of the tools listed in
https://github.com/commoncrawl/cc-pyspark/README.md
More information about WARC/WAT/WET files is given on
https://commoncrawl.org/the-data/get-started/
> Is anything else needed in order to run a spark job on this file?
and those provided by Spark, you need to provide them explicitly.
> What is the columnar index then?
- the URL
- some metadata (date, MIME type, etc.)
- and WARC file name, record offset and length
The latter allows to fetch the actual capture from the WARC archives.
But nice insights are already possible using only URLs and metadata.
> I ran the queries in Athena using your tutorial. Could I do the same
> |s3://commoncrawl/cc-index/table/cc-main/warc/ in a Spark shell?|
unless you have a Spark/Hadoop cluster running with unused slots.
The cc-pyspark jobs fetching and processing WARC records selected by a SQL query
on the columnar index can also consume a CSV file (written by Athena)
which lists <URL, WARC_file, offset, length>.
Best,
Sebastian
On 5/26/20 9:31 PM, Basil Latif wrote:
> Hi Sebastian,
>
>
> />> How exactly is the sparkcc.py file listed in step 4 used in the spark deployment?
> >The easiest way is to add it directly via `--py-files`: /
> --conf ... \
> ... (other Spark options) \
> --py-files sparkcc.py \
> script.py \
> ... (script-specific options)
>
> Is anything else needed in order to run a spark job on this file? What is the data source for this spark job?
>
>
>
> >The columnar index can be queried using SQL either from Athena, Spark or Hive.
>
> It seems I'm not understanding. What is the columnar index then? I ran the queries in Athena using your tutorial. Could I do the same
> |s3://commoncrawl/cc-index/table/cc-main/warc/ in a Spark shell?|
> |
> |
> |Regards,
> |
> |Basil L
> |
>
>
>
>
> You received this message because you are subscribed to the Google Groups "Common Crawl" group.
> To unsubscribe from this group and stop receiving emails from it, send an email to common-crawl...@googlegroups.com
> <mailto:common-crawl...@googlegroups.com>.
> To view this discussion on the web visit
> <https://groups.google.com/d/msgid/common-crawl/64c17582-09b5-4b92-9cfd-05261548ef4f%40googlegroups.com?utm_medium=email&utm_source=footer>.
Basil Latif
aws emr add-steps --cluster-id j-2AXXXXXXGAPLF --steps Type=Spark,Name="Spark Program",
ActionOnFailure=CONTINUE,Args=[--class,org.apache.spark.examples.SparkPi,/usr/lib/spark
/examples/jars/spark-examples.jar,10]
What is the "spark-examples.jar" file that I need here and how do I generate this .jar file?
On the cc-pyspark github, it says I can submit a job with this code? Do I just include the server_count.py file with the job?$SPARK_HOME/bin/spark-submit ./server_count.py --help
Sebastian Nagel
> |aws emr add-steps --cluster-id j-2AXXXXXXGAPLF --steps Type=Spark,Name="Spark Program",
> ActionOnFailure=CONTINUE,Args=[--class,org.apache.spark.examples.SparkPi,/usr/lib/spark
> /examples/jars/spark-examples.jar,10]
> What is the "spark-examples.jar" file that I need here and how do I generate this .jar file?
There are basically two ways to launch a Spark job on EMR:
1. ssh to the master node and run `spark-submit ...`
- I'd prefer this way because it's consistent (apart from certain arguments/parameters) when
running the job locally for development and debugging or on any cluster (not only EMR)
2. `aws emr add-steps` will call spark-submit using the arguments provided in "Args" as
a comma-separated list or alternatively as a JSON list. See more detail by running
`aws emr add-steps help`
3. the AWS console allows you to configure a step, here arguments are space-separated
In all cases, you need to deploy the cc-pyspark files (the used script and sparkcc.py)
either on the master node or on s3://
You'll find many good tutorials about using PySpark on AWS EMR, for example
https://becominghuman.ai/real-world-python-workloads-on-spark-emr-clusters-3c6bda1a1350
Best,
Sebastian
> You received this message because you are subscribed to the Google Groups "Common Crawl" group.
> To unsubscribe from this group and stop receiving emails from it, send an email to common-crawl...@googlegroups.com
> <mailto:common-crawl...@googlegroups.com>.
> To view this discussion on the web visit
> <https://groups.google.com/d/msgid/common-crawl/d37db963-dae5-401d-bc6f-05feff31aed2%40googlegroups.com?utm_medium=email&utm_source=footer>.
Basil Latif
I followed the tutorial. I am unsure of what to put for the s3 bucket command jar in the spark configuration setting. Which jar file do I use and what do I put for the spark settings?
Basil Latif

On Thursday, May 28, 2020 at 1:10:41 PM UTC-7, Sebastian Nagel wrote:
> To unsubscribe from this group and stop receiving emails from it, send an email to common...@googlegroups.com
> <mailto:common-crawl+unsub...@googlegroups.com>.
Sebastian Nagel
the "Step Type" should be "Spark application" (not "Custom JAR")
In case: make sure that Spark is included in the EMR cluster.
Regarding the argument list:
> spark-submit --master yarn --deploy-mode cluster \
> --py-files s3://pyspark-on-emr/pyspark/project.zip \
> --files s3://pyspark-on-emr/data/data-source.ini \
> s3://pyspark-on-emr/pyspark/project.py
I assume that "spark-submit" is not required to be given in the argument list and also "--deploy-mode" should be configurable in the AWS
console, according to the documentation
https://docs.aws.amazon.com/emr/latest/ReleaseGuide/emr-spark-submit-step.html
Best,
Sebastian
On 5/30/20 8:55 AM, Basil Latif wrote:
> Hi Sebastian,
>
>
> > https://groups.google.com/d/msgid/common-crawl/d37db963-dae5-401d-bc6f-05feff31aed2%40googlegroups.com
> <https://groups.google.com/d/msgid/common-crawl/d37db963-dae5-401d-bc6f-05feff31aed2%40googlegroups.com>
> >
> <https://groups.google.com/d/msgid/common-crawl/d37db963-dae5-401d-bc6f-05feff31aed2%40googlegroups.com?utm_medium=email&utm_source=footer>>.
>
> --
> You received this message because you are subscribed to the Google Groups "Common Crawl" group.
> <mailto:common-crawl...@googlegroups.com>.
> <https://groups.google.com/d/msgid/common-crawl/5e5678ca-1273-4c03-a161-600cb9bce198%40googlegroups.com?utm_medium=email&utm_source=footer>.
Basil Latif
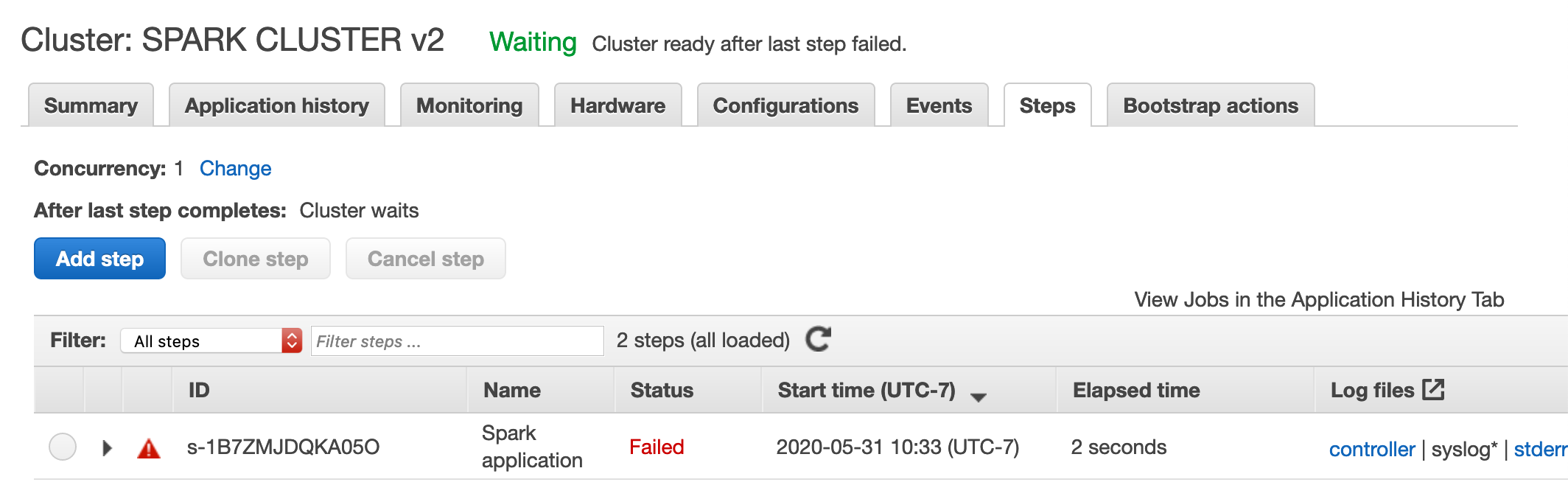
Under "Steps" it says that the spark application failed.
I am also having
trouble ssh'ing into the cluster. I am figuring out how to overcome
that.
What is the next step? How do I run a spark job on the Common Crawl data?
Sebastian Nagel
> Under "Steps" it says that the spark application failed.
Because a cluster-deployed Spark job produces many log files,
I strongly recommend to start a test run of "project.py" before
on your development machine and a small set of input data.
> I am also having trouble ssh'ing into the cluster. I am figuring out how to overcome that.
during the cluster setup.
> What is the next step? How do I run a spark job on the Common Crawl data?
- pass a list of WARC (or WAT or WET) files - in the beginning keep the list short
- if you're using the columnar index, the input would be a SQL query or the result
of a query (a CSV file)
Important: only run the EMR cluster in the us-east-1 region where the Common Crawl data
is hosted to avoid possible costs for cross-region internet traffic. But I see that's
the case from you screen shots.
Best,
Sebastian
On 5/31/20 8:06 PM, Basil Latif wrote:
> Hi Sebastian,
>
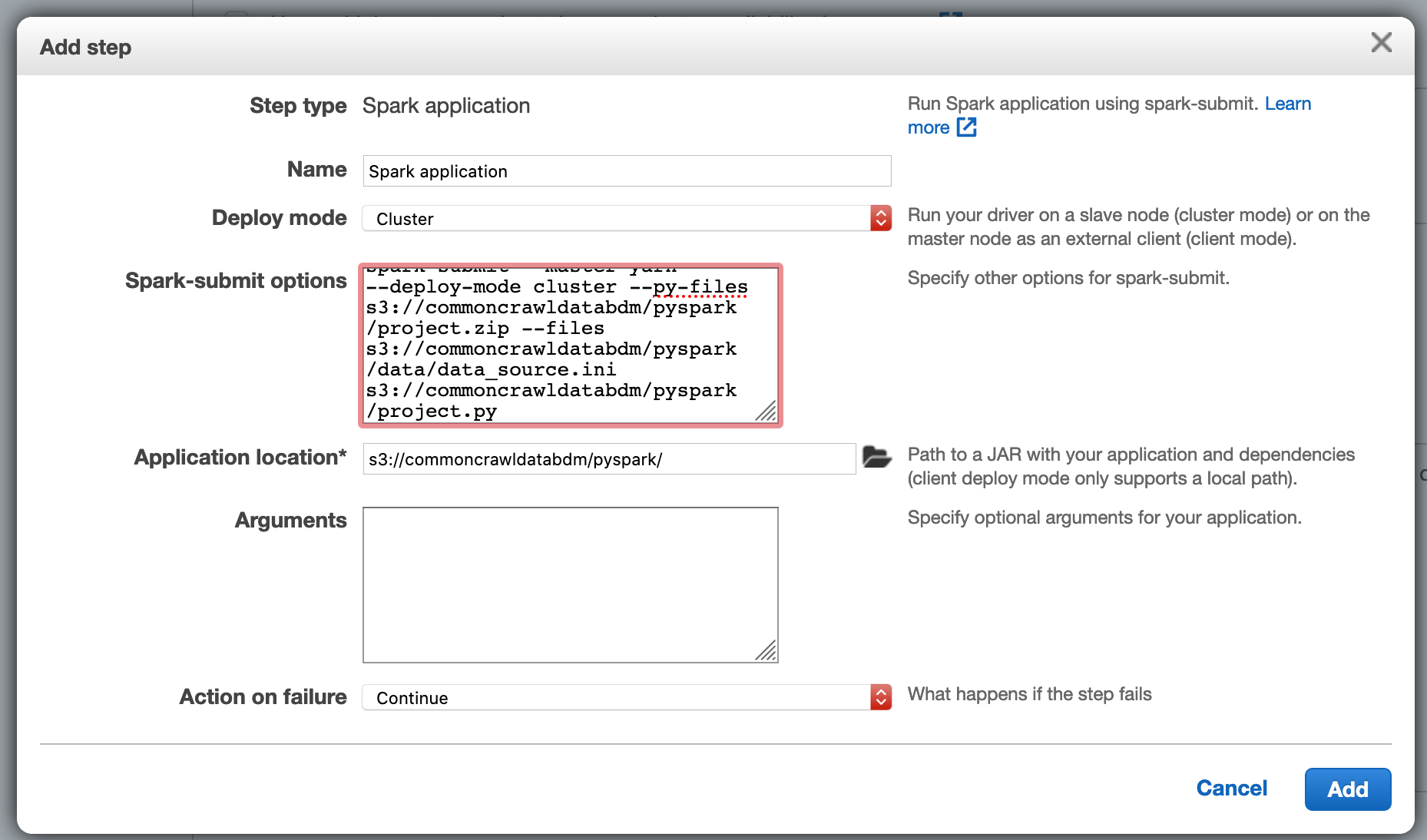
> I setup the cluster using this:
>
>
>
>
>
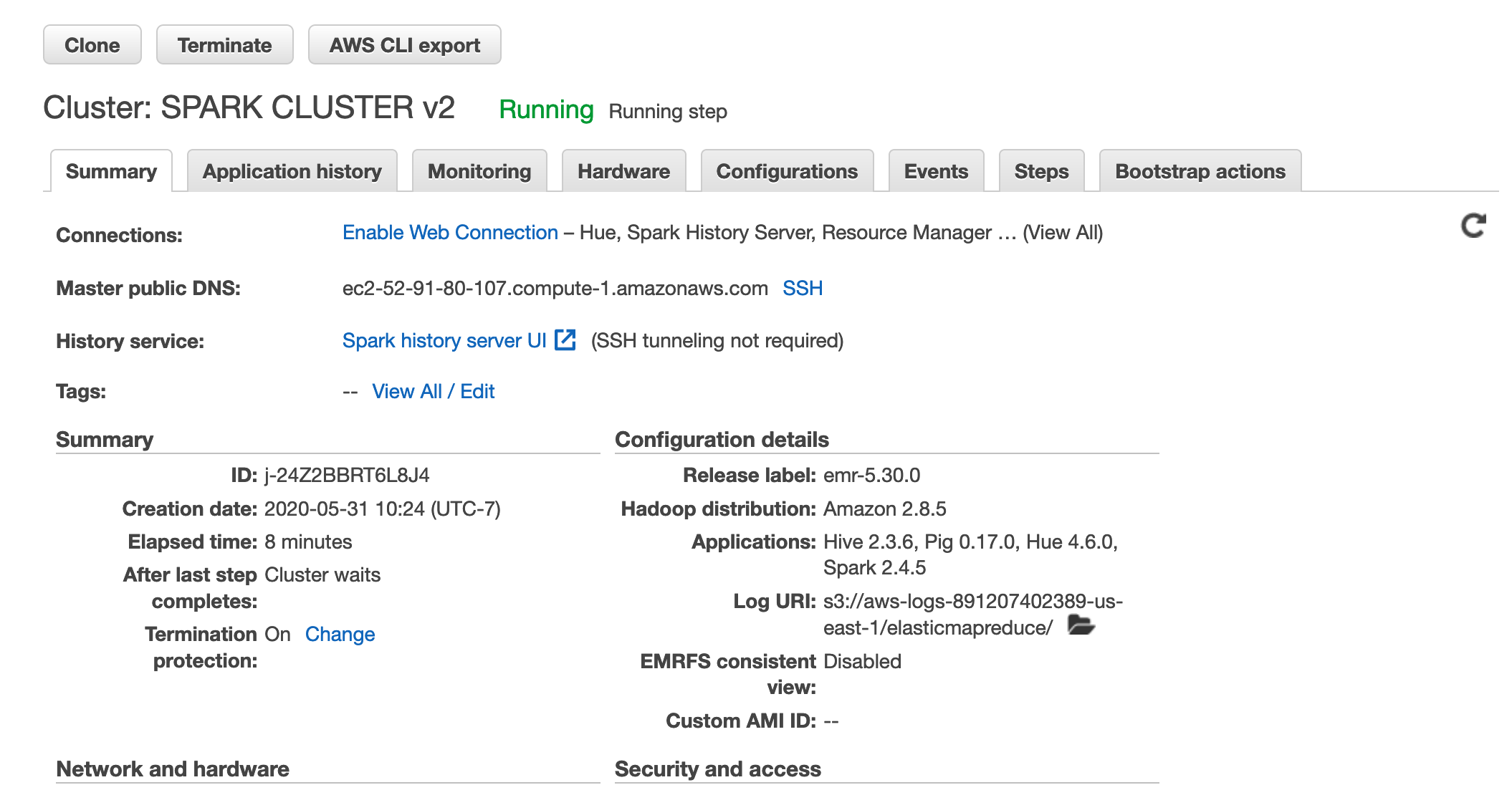
> And I am able to launch the cluster:
>
>
>
>
>
> Under "Steps" it says that the spark application failed.
>
>
>
>
> I am also having trouble ssh'ing into the cluster. I am figuring out how to overcome that.
>
>
> What is the next step? How do I run a spark job on the Common Crawl data?
>
>
> Regards,
> Basil Latif
>
> You received this message because you are subscribed to the Google Groups "Common Crawl" group.
> To unsubscribe from this group and stop receiving emails from it, send an email to common-crawl...@googlegroups.com
> <mailto:common-crawl...@googlegroups.com>.
> To view this discussion on the web visit
> <https://groups.google.com/d/msgid/common-crawl/25e82327-72fa-4042-8de6-7680df565598%40googlegroups.com?utm_medium=email&utm_source=footer>.
Sebastian Nagel
> Under "Steps" it says that the spark application failed.
Because a cluster-deployed Spark job produces many log files,
I strongly recommend to start a test run of "project.py" before
on your development machine and a small set of input data.
during the cluster setup.
- pass a list of WARC (or WAT or WET) files - in the beginning keep the list short
- if you're using the columnar index, the input would be a SQL query or the result
of a query (a CSV file)
Important: only run the EMR cluster in the us-east-1 region where the Common Crawl data
is hosted to avoid possible costs for cross-region internet traffic. But I see that's
the case from you screen shots.
Best,
Sebastian
On 5/31/20 8:06 PM, Basil Latif wrote:
>
> I setup the cluster using this:
>
>
>
>
>
> And I am able to launch the cluster:
>
>
>
>
>
> Under "Steps" it says that the spark application failed.
>
>
>
>
> I am also having trouble ssh'ing into the cluster. I am figuring out how to overcome that.
>
>
> What is the next step? How do I run a spark job on the Common Crawl data?
>
>
> Regards,
> Basil Latif
>
> You received this message because you are subscribed to the Google Groups "Common Crawl" group.
> To unsubscribe from this group and stop receiving emails from it, send an email to common-crawl...@googlegroups.com
> <mailto:common-crawl...@googlegroups.com>.
> To view this discussion on the web visit
> <https://groups.google.com/d/msgid/common-crawl/25e82327-72fa-4042-8de6-7680df565598%40googlegroups.com?utm_medium=email&utm_source=footer>.
Basil Latif
Sebastian Nagel
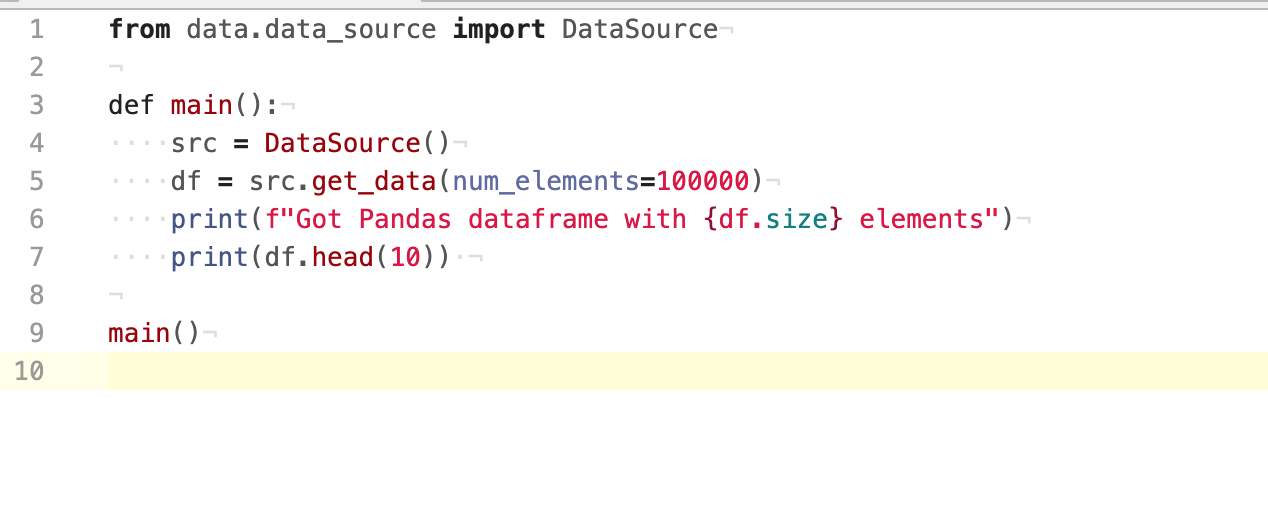
> def main():
> src = DataSource()
> df = src.get_data(num_elements=100000)
> print(f"Got Pandas dataframe with {df.size} elements")
> print(df.head(10))
> So inside of the DataSource() command I put in the path to a warc file?
- select a WARC file
- parse it and select records
- extract the desired information
- map it to a DataFrame
That's a lot of stuff to implement and maybe it's better to start with a lower
abstraction level by focusing of the processing of Common Crawl data. I recommend
to start with an existing example and understand how the data is formatted and
how it can be processed. That's why we provide
https://github.com/commoncrawl/cc-pyspark
and maintain a broad list of example use cases
https://commoncrawl.org/the-data/examples/
Best,
Sebastian
On 6/2/20 4:32 AM, Basil Latif wrote:
> Hi Sebastian,
> You are saying to "- pass a list of WARC (or WAT or WET) files - in the beginning keep the list short. "
> Here is what my project.py file looks like now:
>
>
> So inside of the DataSource() command I put in the path to a warc file?
>
> Regards,
> Basil
>
> You received this message because you are subscribed to the Google Groups "Common Crawl" group.
> To unsubscribe from this group and stop receiving emails from it, send an email to common-crawl...@googlegroups.com
> <mailto:common-crawl...@googlegroups.com>.
> To view this discussion on the web visit
> <https://groups.google.com/d/msgid/common-crawl/662ed47a-b50e-4541-b7c0-f6e82f12930d%40googlegroups.com?utm_medium=email&utm_source=footer>.