About min_bytes_to_rebalance_partition_over_jbod
208 views
Skip to first unread message

Tiago Krebs
Apr 21, 2021, 10:21:58 AM4/21/21
to ClickHouse
Hi all.
This was my recent experience with the min_bytes_to_rebalance_partition_over_jbod setting provided using the 21.4.4 2021-04-12 release.
Release note:
- Introduce a new merge tree setting min_bytes_to_rebalance_partition_over_jbod which allows assigning new parts to different disks of a JBOD volume in a balanced way. #16481 (Amos Bird).
To give some context, I'm working on a cluster with:
- 6 Clickhouse nodes cluster + 3 Zookeeper Nodes
- 2x 2TB NVMe disks on each node used by a JBOD hot layer policy.
- 2 Tables (shared and replicated)
- 3 Shards
- 2 Replicas
- ~80k inserts on each node (done by 2 Kafka engine tables)
- ~160B per event after stored
- ~1.3TB ingested data per day on the total
- Table TTL of 2 days on the hot layer
The nature of the data on the tables is Nginx events from a global Edge Computing Platform. The partitions are configured to be the year and month of the events.
This was the first 24h before I upgrade the nodes and set the min_bytes_to_rebalance_partition_over_jbod on my table settings.

On average ~150GB (~11%) of difference between disks.
On the second day, I decided to upgrade to 21.4.4 and enable the new setting but start to wonder what the correct minimal size a partition should have in order to rebalance over JBOD. So these are the sizes of my parts on system.parts table from one of the nodes.
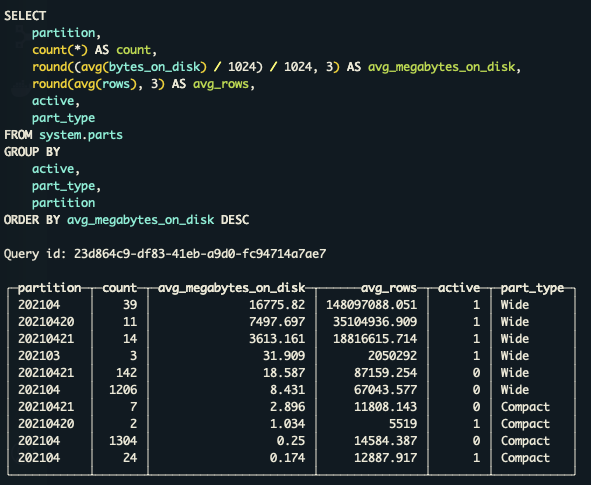
As more than 90% of the partitions are really small compared with the big ones I decided to focus the new setting only on the big parts. I set the min_bytes_to_rebalance_partition_over_jbod to 1GB. Here is the result.

The first mark is the version upgrade and the second one the moment when the new setting was set on the tables.
Although I don't know if my method makes sense I am considering the value used for the new parameter as correct. Some feedback on this would be much appreciated.
Regards,
Message has been deleted

Amos Bird
Apr 22, 2021, 6:39:01 AM4/22/21
to Tiago Krebs, click...@googlegroups.com
Hi Tiago!
Those partitions look quite small to utilize the JBOD balancer.
You can try setting `min_bytes_to_rebalance_partition_over_jbod =
100MB` and see if it brings any benefits. You can setup a test env
and ship those data into it via ALTER TABLE FETCH PARTITION, which
will also apply JBOD balancer.
> This was my recent experience with the*
> min_bytes_to_rebalance_partition_over_jbod* setting provided
> using the 21.4.4
> 2021-04-12 release.
> Release note:
> *- Introduce a new merge tree setting
> 2021-04-12 release.
> Release note:
> min_bytes_to_rebalance_partition_over_jbod which allows
> assigning new parts
> to different disks of a JBOD volume in a balanced way. #16481
> <https://github.com/ClickHouse/ClickHouse/pull/16481> (Amos Bird
> assigning new parts
> to different disks of a JBOD volume in a balanced way. #16481
> <https://github.com/amosbird>).*
> min_bytes_to_rebalance_partition_over_jbod to 1GB*. Here is the
Tiago Krebs
Apr 22, 2021, 9:25:17 AM4/22/21
to Amos Bird, click...@googlegroups.com
Reply all
Reply to author
Forward
0 new messages