Вопрос про вертикальный merge + ускорение слияния

kona...@gmail.com

Vitaliy Lyudvichenko
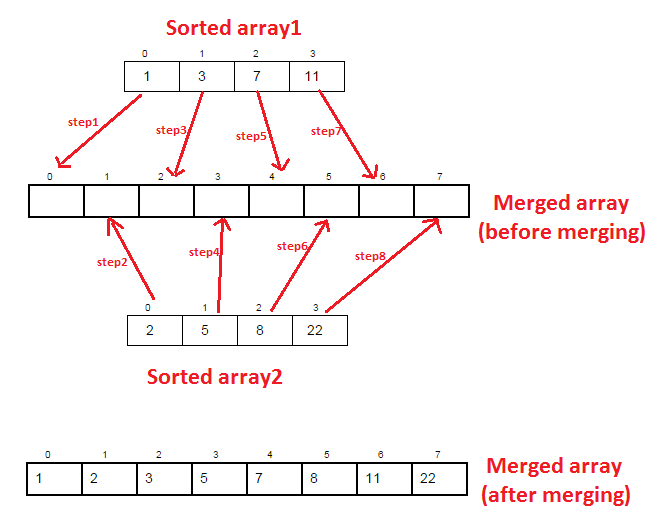
Как известно данные в MergeTree хранятся в виде набора кусков.
Кусок - это по сути полноценная таблица (без метаданных), строки которой хранятся в порядке возрастания первичного ключа.
Очевидно, что для более эффективного выполнения SELECT выгодней хранить один большой кусок вместо множества маленьких.
Поэтому куски надо время от времени сливать, т.е. из нескольких упорядоченных по первичному кулючу таблиц получать одну большую.
В процессе слияния строки из исходных кусков укладываются так, чтобы они образовывали возрастающую относительно первичного ключа последовательность.
Таким образом этот процесс может выполняться только построчно, что снижает эффективность использования колоночной схемы хранения и обработки данных, используемой в КликХаусе.
Однако тут можно схитрить и оптимизировать этот процесс, если заметить, что на самом деле "построчную укладку" можно выполнить не для всех колонок, а только для колонок, входящих в первичный ключ (ведь только они и определяют порядок сортировки).
А оставшиеся данные (т.е. колонки не входящие в первичный ключ) можно уже "укладывать" поколоночно (одну колонку за раз), что положительно сказывается скорости слияния за счет большей локальности по чтению/записи.
Более детально, новый алгоритм слияния работает следующим образом:
1) Горизонтальный этап. Читаем из всех кусков только колонки, входящие в первичный ключ, сливаем их, записываем отсортированный результат. В процессе слияния запоминаем в опративке индексный массив, хранящий для каждой строки результирующего куска номер исходного куска из которого она была туда положена.
2) Вертикальный этап. Для каждой оставшейся необработанной колонки читаем её исходные кусочки. Эффективно собираем эти куски одной строки в один кусок за счет использования массива индексов в оперативке. Записываем собранную колонку, переходим к следующей.
По моим замерам новый алгоритм на широких таблицах (>100 колонок, 5 колонок, входящих в первичный ключ) работает суммарно в 2,5-3 раза быстрее старого, который всю обработку делал построчно.
вторник, 10 января 2017 г., 9:22:10 UTC+3 пользователь kona...@gmail.com написал:

man...@gmail.com
Сейчас включили вручную на продакшен кластерах, на половине реплик. Пока всё Ок - за конец декабря и начало января проблем не обнаружено.
По результатам, всё действительно в 2.5-3 раза быстрее. К тому же, на широких таблицах (сотни столбцов), во время мержа потребляется меньше оперативки - более чем на порядок.
Скорее всего, это будет включено по-умолчанию в релизе до конца января.
kona...@gmail.com
Здравствуйте.
Vitaliy Lyudvichenko
Спасибо за ответ. Однако, осталось недопонимание второго этапа. Точно так?"В процессе слияния запоминаем в опративке индексный массив, хранящий для каждой строки результирующего куска номер исходного куска из которого она была туда положена."???Что даст такой массив? Не мало? Может, для каждой строки результирующего куска запоминается номер исходного куска из которого она, и еще номер строки в исходном куске? Тогда понятно, как сливается - понятно,куда писать ее в результирующий парт.
Но тут сразу второй вопрос. Вся идеология обеспечения скорости строится на массовых операциях, таких как сортировка, слияние и т. п. Индексные массивы - это всегда избирательность, это операции по одной записи и т. п. Немассовость, короче. В меру моего понимания. Если сливать через индексные массивы небольшие куски, и все в памяти, то, наверное, все быстро. А если большие? Когда из уже ближе к данным за месяц объем подходит?
Vitaliy Lyudvichenko
среда, 11 января 2017 г., 19:14:05 UTC+3 пользователь Vitaliy Lyudvichenko написал:
kona...@gmail.com
Здравствуйте.