Lesbarkeit vs. Abhängigkeiten vermeiden

Leba

Tim Gesekus
Onkel Bob mach in seinen Code Beispiel viele Dinge, die die Lesbarkeit erhöhen, die ich in deinem Beispiel nicht gemacht wurden. Nimm mal eine Zeile wie:
IterateUpTo(limit,i => CheckIfCrossed(crossedOut, i, () => CrossOutputMultiplesOf(crossedOut, i)));
Wenn ich den Algorithmus nicht kenne muss ich jetzt erst mal Analyse machen, was diese Zeile macht:
1. IterateUpTo .. wird wohl bis zum limit hochzaehlen und CheckIf Crossed fuer jedes i machen
2. CheckIfCrossed .. wird wohl .....
3. CrossOutMulitplesOf .. wird wohl .....
und zusammen macht das wohl ....
Viel Denken und Lesen für eine Zeile und der Parameter crossedout kommt auch noch mehrfach darin vor.
Also packe die Zeile in einen Methoden Aufruf:
CrossOutMulitplesOf(..);
Dann hat man wenigstens eine Idee was die Zeile leisten soll.
Ich empfehle das Buch Clean Code :)
Ansonsten gilt für mich Lesbarkeit als eine der wichtigsten Merkmale von Software, allerdings bezogen auf das gewählte Paradigma.
Vergleiche:
mit
Das erste ist Prosa und sagt mir was der Code macht und das zweite sagt mir nur wie es etwas macht. Auf der höchsten Abstraktion Ebene will ich aber wissen, was er macht.
HTH
Tim

Stephan Roth
Guten Tag,
ich schließe mich Tims Ausführungen an. Das für mich wesentliche Prinzip, welches hier berücksichtigt werden sollte, lautet "Use Intention-revealing names".
Die herausgegriffene Codezeile zeigt zwar, WIE etwas gelöst wurde, es wird aber in keinster Weise ersichtlich WAS dieses Stück Code aus einer fachlichen Perspektive macht.
Versuche einen Semantik-reichen Namen für die Codezeile zu finden, der beschreibt, was sich fachlich dahinter verbirgt.
LG,
Stephan
> --
> Sie erhalten diese Nachricht, weil Sie in Google Groups E-Mails von der Gruppe "Clean Code Developer" abonniert haben.
> Wenn Sie sich von dieser Gruppe abmelden und keine E-Mails mehr von dieser Gruppe erhalten möchten, senden Sie eine E-Mail an clean-code-devel...@googlegroups.com.
> Wenn Sie in dieser Gruppe einen Beitrag posten möchten, senden Sie eine E-Mail an clean-code...@googlegroups.com.
> Gruppe besuchen: http://groups.google.com/group/clean-code-developer
> Weitere Optionen finden Sie unter https://groups.google.com/d/optout.
Leba
> Wenn Sie sich von dieser Gruppe abmelden und keine E-Mails mehr von dieser Gruppe erhalten möchten, senden Sie eine E-Mail an clean-code-developer+unsub...@googlegroups.com.

Ralf Westphal
Leba
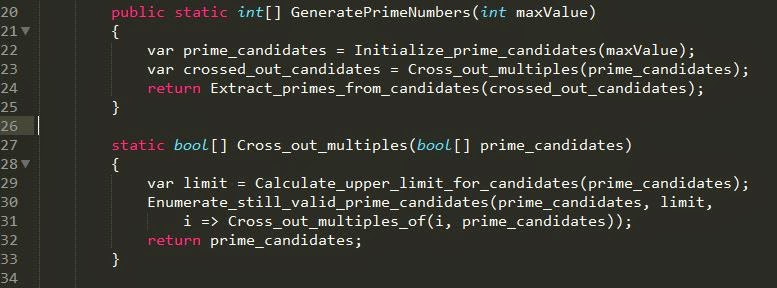
1. Den Test auf den Edge-Case (if (maxValue<2)...) habe ich weggelassen. Der ist überflüssig. Er ist ein Relikt des Vorgehens nach TDD. Da war mal ein Testfall, der so grün gemacht werden konnte. Doch das Wissen, dass es unterhalt 2 keine Primzahlen gibt, ist dadurch an mindestens zwei Stellen codiert. Einmal in dem Vergleich und einmal in PutUncrossedIntegersIntoResult. Dort steht nämlich for(..., i=2; ...). Dadurch werden Zahlen <2 als Primzahlen ebenfalls ausgeschlossen.Ich habe also diesen Vergleich gestrichen - das ist wirklich KISS, finde ich :-) - und habe die Behandlung von zu kleinen Zahlen über eine Konstante sichtbar gemacht.
Daraus ließe sich übrigens auch eine Datenstruktur (ADT) ableiten. Deshalb sind die beiden Methoden Initialize_prime_candidates und Extract_primes_from_candidates etwas abgesetzt am Ende. Sie könnten in einer Klasse Primescandidates oder so zusammengefasst werden. Damit wäre die Trennung von Domänenlogik (Operationen in Zeilen 19 bis 38) und Daten deutlich. Das habe ich hier mal versuchsweise gebaut: https://gist.github.com/ralfw/08dc32b3f51236ad557e#file-primegenerator_with_adt-cs.
An der Erkenntnis, dass IOSP/PoMO einer besseren Lesbarkeit nicht im Wege stehen, ändert das aber nichts. Refactoring ist auch mit IOSP/PoMO nur zu einem gewissen grad mechanisch. Wenn es hakt, dann muss man sich Gedanken machen. Dann ist das ein Hinweis darauf, dass irgendwas noch nicht stimmt, eine Prämisse hinterfragt werden sollte.
Ralf Westphal
--
Sie erhalten diese Nachricht, weil Sie in Google Groups ein Thema der Gruppe "Clean Code Developer" abonniert haben.
Wenn Sie sich von diesem Thema abmelden möchten, rufen Sie https://groups.google.com/d/topic/clean-code-developer/2rkrMmt3u7o/unsubscribe auf.
Wenn Sie sich von dieser Gruppe und allen Themen dieser Gruppe abmelden möchten, senden Sie eine E-Mail an clean-code-devel...@googlegroups.com.
Wenn Sie in dieser Gruppe einen Beitrag posten möchten, senden Sie eine E-Mail an clean-code...@googlegroups.com.
Gruppe besuchen: http://groups.google.com/group/clean-code-developer
Weitere Optionen finden Sie unter https://groups.google.com/d/optout.
D-22085 Hamburg
Germany
Tel 0170-3200458
Email in...@ralfw.de
Leba
Wenn Sie sich von dieser Gruppe und allen Themen dieser Gruppe abmelden möchten, senden Sie eine E-Mail an clean-code-developer+unsub...@googlegroups.com.
Wenn Sie in dieser Gruppe einen Beitrag posten möchten, senden Sie eine E-Mail an clean-code...@googlegroups.com.
Gruppe besuchen: http://groups.google.com/group/clean-code-developer
Weitere Optionen finden Sie unter https://groups.google.com/d/optout.