Spark versions for Cloudera CDAP
463 views
Skip to first unread message

simo...@gmail.com
Jul 31, 2018, 12:29:28 PM7/31/18
to CDAP User
Hi All
Can anyone go through how CDAP works from a 'Spark program' point of view? I've scoured the documentation but I can't find anything really detailed about this.
For example, in what mode does the spark driver run in? Is it 'client' or 'YARN' based? Can we influence this? Does CDAP run it's own spark jars (as we're finding there is a single version available, no matter what Spark 2.x version is installed on the Cloudera system) - effectively using the CDH system as a YARN container host, rather than running native CDH SPARK2. Notice that the classpath is favouring CDAP jars for CDAP based Spark UI, and CDH jars for CDH based spark UI.
Some explanation... We've got a PoC running for CDAP 4.3.4 currently, installed on Cloudera 5.13.1. We're kerberized. We have a requirement to run Scala based pipelines (I'm assuming I need to use the ScalaSpark program for this!) and we need to run Spark 2.
Thank you!
SC

Albert Shau
Jul 31, 2018, 1:49:45 PM7/31/18
to cdap...@googlegroups.com
Hi SC,
CDAP uses the Spark version installed on your cluster, it does not package and run its own in distributed mode. If you only have Spark2 installed, it will discover that and use it automatically. If you have both Spark1 and Spark2 installed, you have to configure it to use the version you want (https://docs.cask.co/cdap/4.3.4/en/admin-manual/installation/cloudera.html#cluster-home-page-configuring-for-spark). What behavior are you seeing that indicates a different Spark than the one on the cluster is being used? When you say the CDAP based Spark UI are you referring to the UI you get to when clicking on the tracking URL for the Spark program in YARN?
CDAP will run spark programs in YARN. When you run a spark program, you will see two applications in YARN, the first is a CDAP application that submits the spark job. The second is the actual Spark job, which will be like any other Spark job run on the cluster except with some integrations with CDAP.
When you say you need to run scala based pipelines, does that mean you have custom logic that you want to implement as pipeline plugins? Any plugin that you can write in Java can also be written in scala. See https://docs.cask.co/cdap/4.3.4/en/developer-manual/pipelines/index.html for more information about developing pipeline plugins.
To run a pipeline using Spark, all you need to do is configure the engine to be Spark instead of MapReduce. If you have existing scala spark code, you can upload your jar as a 'library', then chain them together in a pipeline (see https://www.youtube.com/watch?v=gDnINRBzg2s).
Best,
Albert
--
You received this message because you are subscribed to the Google Groups "CDAP User" group.
To unsubscribe from this group and stop receiving emails from it, send an email to cdap-user+...@googlegroups.com.
To post to this group, send email to cdap...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/cdap-user/c2fdbeb5-38f6-4200-83ae-c8463a3165aa%40googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
simo...@gmail.com
Jul 31, 2018, 2:50:39 PM7/31/18
to CDAP User
Hi Albert
Thanks. That's great information.
Yes, the URL you mentioned is the one - the tracking URL in YARN for the application master.
I've also had a go with CDAP 5.0.0 which I've built myself. I'm currently testing with Spark 2.2 on CDH 5.14.2. Again it's kerberized. The CDAP installation still needs the SPARK_MAJOR_VERSION environment variable - when it's set, Spark2 is used. Looking at the SparkUI shows a Spark version of 2.1.
I have Spark 2.2 installed on the CDH cluster.
Here's a screen shot of the SparkUI under a CDAP pipeline:
And here's one running a vanilla 'spark2-shell' on an edge node:
simo...@gmail.com
Jul 31, 2018, 2:55:43 PM7/31/18
to CDAP User
Sorry - and now with the screenshots!
2.1 running under a CDAP pipeline:
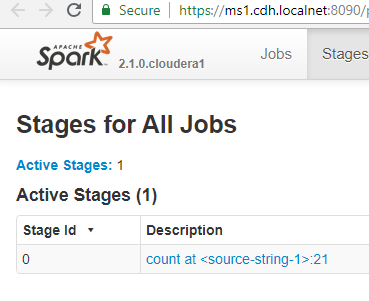
And under a default 'spark2-shell' on an edge node - using the cluster spark:

Looking at installed packages on the cluster:

Thanks again...!
simo...@gmail.com
Jul 31, 2018, 3:05:22 PM7/31/18
to CDAP User
Sorry - I have Spark 2.3 installed (not doing very well at this am I?!)
I've also tried with Spark 2.2 - same result. Let me know if you'd like me to reproduce it and post...
simo...@gmail.com
Jul 31, 2018, 3:15:51 PM7/31/18
to CDAP User
And here's the program and logfile:
Program:
import co.cask.cdap.api.spark._
import org.apache.spark._
import org.slf4j._
class SparkProgram extends SparkMain {
import SparkProgram._
override def run(implicit sec: SparkExecutionContext): Unit = {
LOG.info("Spark Program Started")
LOG.info("---------------------")
val conf = new SparkConf().setMaster("yarn").setAppName("CDAP_Spark-On-Yarn")
val sc = new SparkContext(conf)
LOG.info("Spark Context : " + sc)
LOG.info("Spark Version : " + sc.version)
val text = sc.textFile("hdfs://cl1/user/simon/bigShakes.txt")
val counts = text.flatMap(line => line.split(" ")).map(word => (word,1)).reduceByKey(_+_)
val col = counts.collect
LOG.info("Result : " + col)
LOG.info("Spark Program Completed")
LOG.info("-----------------------")
}
}
object SparkProgram {
val LOG = LoggerFactory.getLogger(getClass())
}
Logfile:
2018-07-31 19:43:21,208 - INFO [program.status:c.c.c.i.a.r.d.DistributedProgramRunner@475] - Starting Workflow Program 'DataPipelineWorkflow' with Arguments [logical.start.time=1533062593447]
2018-07-31 19:43:21,208 - INFO [program.status:c.c.c.i.a.r.d.DistributedProgramRunner@475] - Starting Workflow Program 'DataPipelineWorkflow' with Arguments [logical.start.time=1533062593447]
2018-07-31 19:44:55,379 - INFO [WorkflowDriver:c.c.c.d.SmartWorkflow@440] - Pipeline 'SV14' is started by user 'cdap' with arguments {logical.start.time=1533062593447}
2018-07-31 19:44:55,435 - INFO [WorkflowDriver:c.c.c.d.SmartWorkflow@474] - Pipeline 'SV14' running
2018-07-31 19:44:55,530 - INFO [WorkflowDriver:c.c.c.i.a.r.w.WorkflowDriver@611] - Starting workflow execution for 'DataPipelineWorkflow' with Run id '9486c6d1-94f1-11e8-8a9d-000c299af245'
2018-07-31 19:45:04,535 - INFO [action-phase-1-0:c.c.c.i.a.r.w.WorkflowDriver@342] - Starting Spark Program 'phase-1' in workflow
2018-07-31 19:45:06,551 - INFO [SparkExecutionService STARTING:c.c.h.NettyHttpService@172] - Starting HTTP Service phase-1-spark-exec-service at address wk2.cdh.localnet/192.168.10.24:0
2018-07-31 19:45:11,676 - WARN [spark-submitter-phase-1-d6b8bae1-94f1-11e8-aaec-000c29ad103d:o.a.s.d.y.s.ConfigurableCredentialManager@66] - spark.yarn.security.tokens.hbase.enabled is deprecated, using spark.yarn.security.credentials.hbase.enabled instead
2018-07-31 19:45:11,684 - WARN [spark-submitter-phase-1-d6b8bae1-94f1-11e8-aaec-000c29ad103d:o.a.s.d.y.s.ConfigurableCredentialManager@66] - spark.yarn.security.tokens.hive.enabled is deprecated, using spark.yarn.security.credentials.hive.enabled instead
2018-07-31 19:45:51,337 - INFO [SparkDriverHttpService STARTING:c.c.h.NettyHttpService@172] - Starting HTTP Service phase-1-http-service at address wk1.cdh.localnet/192.168.10.23:0
2018-07-31 19:45:51,871 - INFO [Driver:c.c.c.a.r.s.d.SparkDriverService@188] - Credentials DIR: hdfs://cl1/user/cdap/.sparkStaging/application_1533062157811_0003
2018-07-31 19:45:54,071 - INFO [SparkDriverService:c.c.c.a.r.s.d.SparkDriverService@98] - SparkDriverService started.
2018-07-31 19:45:54,122 - INFO [Driver:c.c.c.a.r.s.SparkMainWrapper$@77] - Launching user spark class class co.cask.cdap.datapipeline.JavaSparkMainWrapper
2018-07-31 19:46:18,497 - INFO [Driver:SparkProgram$@9] - Spark Program Started
2018-07-31 19:46:18,499 - INFO [Driver:SparkProgram$@10] - ---------------------
2018-07-31 19:46:20,037 - INFO [Driver:o.s.j.u.log@186] - Logging initialized @48543ms
2018-07-31 19:46:20,322 - INFO [Driver:o.s.j.s.Server@327] - jetty-9.2.z-SNAPSHOT
2018-07-31 19:46:20,414 - INFO [Driver:o.s.j.s.h.ContextHandler@744] - Started o.s.j.s.ServletContextHandler@2d614990{/jobs,null,AVAILABLE}
2018-07-31 19:46:20,417 - INFO [Driver:o.s.j.s.h.ContextHandler@744] - Started o.s.j.s.ServletContextHandler@4a6124fb{/jobs/json,null,AVAILABLE}
2018-07-31 19:46:20,419 - INFO [Driver:o.s.j.s.h.ContextHandler@744] - Started o.s.j.s.ServletContextHandler@ba1e844{/jobs/job,null,AVAILABLE}
2018-07-31 19:46:20,420 - INFO [Driver:o.s.j.s.h.ContextHandler@744] - Started o.s.j.s.ServletContextHandler@6a9e5b19{/jobs/job/json,null,AVAILABLE}
2018-07-31 19:46:20,420 - INFO [Driver:o.s.j.s.h.ContextHandler@744] - Started o.s.j.s.ServletContextHandler@4d14a213{/stages,null,AVAILABLE}
2018-07-31 19:46:20,421 - INFO [Driver:o.s.j.s.h.ContextHandler@744] - Started o.s.j.s.ServletContextHandler@e9111b6{/stages/json,null,AVAILABLE}
2018-07-31 19:46:20,421 - INFO [Driver:o.s.j.s.h.ContextHandler@744] - Started o.s.j.s.ServletContextHandler@af62be8{/stages/stage,null,AVAILABLE}
2018-07-31 19:46:20,422 - INFO [Driver:o.s.j.s.h.ContextHandler@744] - Started o.s.j.s.ServletContextHandler@12a8ff3c{/stages/stage/json,null,AVAILABLE}
2018-07-31 19:46:20,424 - INFO [Driver:o.s.j.s.h.ContextHandler@744] - Started o.s.j.s.ServletContextHandler@7a44c340{/stages/pool,null,AVAILABLE}
2018-07-31 19:46:20,425 - INFO [Driver:o.s.j.s.h.ContextHandler@744] - Started o.s.j.s.ServletContextHandler@7c5e611f{/stages/pool/json,null,AVAILABLE}
2018-07-31 19:46:20,433 - INFO [Driver:o.s.j.s.h.ContextHandler@744] - Started o.s.j.s.ServletContextHandler@474cbc17{/storage,null,AVAILABLE}
2018-07-31 19:46:20,434 - INFO [Driver:o.s.j.s.h.ContextHandler@744] - Started o.s.j.s.ServletContextHandler@1248fadd{/storage/json,null,AVAILABLE}
2018-07-31 19:46:20,434 - INFO [Driver:o.s.j.s.h.ContextHandler@744] - Started o.s.j.s.ServletContextHandler@4eca6517{/storage/rdd,null,AVAILABLE}
2018-07-31 19:46:20,435 - INFO [Driver:o.s.j.s.h.ContextHandler@744] - Started o.s.j.s.ServletContextHandler@4193b348{/storage/rdd/json,null,AVAILABLE}
2018-07-31 19:46:20,436 - INFO [Driver:o.s.j.s.h.ContextHandler@744] - Started o.s.j.s.ServletContextHandler@631d0369{/environment,null,AVAILABLE}
2018-07-31 19:46:20,437 - INFO [Driver:o.s.j.s.h.ContextHandler@744] - Started o.s.j.s.ServletContextHandler@36d693c5{/environment/json,null,AVAILABLE}
2018-07-31 19:46:20,438 - INFO [Driver:o.s.j.s.h.ContextHandler@744] - Started o.s.j.s.ServletContextHandler@2ba9bad5{/executors,null,AVAILABLE}
2018-07-31 19:46:20,439 - INFO [Driver:o.s.j.s.h.ContextHandler@744] - Started o.s.j.s.ServletContextHandler@77fc451b{/executors/json,null,AVAILABLE}
2018-07-31 19:46:20,440 - INFO [Driver:o.s.j.s.h.ContextHandler@744] - Started o.s.j.s.ServletContextHandler@7cf106c6{/executors/threadDump,null,AVAILABLE}
2018-07-31 19:46:20,440 - INFO [Driver:o.s.j.s.h.ContextHandler@744] - Started o.s.j.s.ServletContextHandler@7ebbfa26{/executors/threadDump/json,null,AVAILABLE}
2018-07-31 19:46:20,465 - INFO [Driver:o.s.j.s.h.ContextHandler@744] - Started o.s.j.s.ServletContextHandler@18a29836{/static,null,AVAILABLE}
2018-07-31 19:46:20,466 - INFO [Driver:o.s.j.s.h.ContextHandler@744] - Started o.s.j.s.ServletContextHandler@de3d2a4{/,null,AVAILABLE}
2018-07-31 19:46:20,470 - INFO [Driver:o.s.j.s.h.ContextHandler@744] - Started o.s.j.s.ServletContextHandler@79d032e8{/api,null,AVAILABLE}
2018-07-31 19:46:20,471 - INFO [Driver:o.s.j.s.h.ContextHandler@744] - Started o.s.j.s.ServletContextHandler@581b9d3e{/jobs/job/kill,null,AVAILABLE}
2018-07-31 19:46:20,472 - INFO [Driver:o.s.j.s.h.ContextHandler@744] - Started o.s.j.s.ServletContextHandler@5474cd23{/stages/stage/kill,null,AVAILABLE}
2018-07-31 19:46:20,494 - INFO [Driver:o.s.j.s.ServerConnector@266] - Started ServerConnector@65953dab{HTTP/1.1}{0.0.0.0:45608}
2018-07-31 19:46:20,495 - INFO [Driver:o.s.j.s.Server@379] - Started @49001ms
2018-07-31 19:46:21,810 - INFO [Driver:o.s.j.s.h.ContextHandler@744] - Started o.s.j.s.ServletContextHandler@56457c3a{/metrics/json,null,AVAILABLE}
2018-07-31 19:46:22,208 - WARN [dispatcher-event-loop-1:o.a.s.s.c.YarnSchedulerBackend$YarnSchedulerEndpoint@66] - Attempted to request executors before the AM has registered!
2018-07-31 19:46:22,348 - INFO [Driver:SparkProgram$@16] - Spark Context : org.apache.spark.SparkContext@7e09c844
2018-07-31 19:46:22,349 - INFO [Driver:SparkProgram$@17] - Spark Version : 2.1.0.cloudera1
2018-07-31 19:46:40,477 - WARN [Timer-0:o.a.s.s.c.YarnClusterScheduler@66] - Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources
2018-07-31 19:46:55,486 - WARN [Timer-0:o.a.s.s.c.YarnClusterScheduler@66] - Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources
2018-07-31 19:47:07,407 - WARN [main:o.a.s.d.y.s.ConfigurableCredentialManager@66] - spark.yarn.security.tokens.hbase.enabled is deprecated, using spark.yarn.security.credentials.hbase.enabled instead
2018-07-31 19:47:07,460 - WARN [main:o.a.s.d.y.s.ConfigurableCredentialManager@66] - spark.yarn.security.tokens.hive.enabled is deprecated, using spark.yarn.security.credentials.hive.enabled instead
2018-07-31 19:47:07,531 - WARN [main:o.a.s.d.y.s.ConfigurableCredentialManager@66] - spark.yarn.security.tokens.hbase.enabled is deprecated, using spark.yarn.security.credentials.hbase.enabled instead
2018-07-31 19:47:07,541 - WARN [main:o.a.s.d.y.s.ConfigurableCredentialManager@66] - spark.yarn.security.tokens.hive.enabled is deprecated, using spark.yarn.security.credentials.hive.enabled instead
2018-07-31 19:47:10,485 - WARN [Timer-0:o.a.s.s.c.YarnClusterScheduler@66] - Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources
2018-07-31 19:47:18,900 - WARN [main:o.a.s.d.y.s.ConfigurableCredentialManager@66] - spark.yarn.security.tokens.hbase.enabled is deprecated, using spark.yarn.security.credentials.hbase.enabled instead
2018-07-31 19:47:18,912 - WARN [main:o.a.s.d.y.s.ConfigurableCredentialManager@66] - spark.yarn.security.tokens.hive.enabled is deprecated, using spark.yarn.security.credentials.hive.enabled instead
2018-07-31 19:47:19,256 - WARN [main:o.a.s.d.y.s.ConfigurableCredentialManager@66] - spark.yarn.security.tokens.hbase.enabled is deprecated, using spark.yarn.security.credentials.hbase.enabled instead
2018-07-31 19:47:19,264 - WARN [main:o.a.s.d.y.s.ConfigurableCredentialManager@66] - spark.yarn.security.tokens.hive.enabled is deprecated, using spark.yarn.security.credentials.hive.enabled instead
2018-07-31 19:52:45,219 - INFO [Driver:SparkProgram$@23] - Result : [Lscala.Tuple2;@2f40d16e
2018-07-31 19:52:45,219 - INFO [Driver:SparkProgram$@25] - Spark Program Completed
2018-07-31 19:52:45,219 - INFO [Driver:SparkProgram$@26] - -----------------------
2018-07-31 19:52:45,254 - INFO [SparkDriverService:c.c.c.a.r.s.d.SparkDriverService@145] - SparkDriverService stopped.
2018-07-31 19:52:45,341 - INFO [Thread-11:o.s.j.s.ServerConnector@306] - Stopped ServerConnector@65953dab{HTTP/1.1}{0.0.0.0:0}
2018-07-31 19:52:46,108 - INFO [SparkExecutionService STOPPING:c.c.h.NettyHttpService@242] - Stopping HTTP Service phase-1-spark-exec-service
2018-07-31 19:52:46,309 - INFO [action-phase-1-0:c.c.c.i.a.r.w.WorkflowDriver@345] - Spark Program 'phase-1' in workflow completed
2018-07-31 19:52:46,335 - INFO [WorkflowDriver:c.c.c.i.a.r.w.WorkflowDriver@619] - Workflow 'DataPipelineWorkflow' with run id '9486c6d1-94f1-11e8-8a9d-000c299af245' completed
2018-07-31 19:52:46,401 - INFO [WorkflowDriver:c.c.c.d.SmartWorkflow@531] - Pipeline 'SV14' succeeded.Albert Shau
Jul 31, 2018, 4:01:38 PM7/31/18
to cdap...@googlegroups.com
Hi SC,
Thanks for the screenshots, it makes things clearer. That's really odd, I'm not sure where it could be picking 2.1 from. We don't have the cloudera version of spark in our dependencies, so it must be picking that up from the environment somewhere. If you run spark shell on the node that CDAP master is installed on, what version of Spark do you see? Also, can you check what jars you see in the [/path/to/cdap-master-directory]/ext/runtimes/spark2_2.11 directory?
By the way, I don't believe CDAP supports Spark 2.3 yet, so you may have to use Spark 2.2. I don't think it's related to this version mismatch though.
Thanks,
Albert
--
You received this message because you are subscribed to the Google Groups "CDAP User" group.
To unsubscribe from this group and stop receiving emails from it, send an email to cdap-user+...@googlegroups.com.
To post to this group, send email to cdap...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/cdap-user/6d3a16f5-0a8a-4e64-b690-690d4736fae1%40googlegroups.com.
simo...@gmail.com
Aug 1, 2018, 2:39:45 AM8/1/18
to CDAP User
Thanks Albert
So for the pre-GA CDAP 5.0.0 I've got installed - I can confirm that starting a spark2-shell from the command prompt on the node running CDAP shows:
[simon@edge ~]$ spark2-shell
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://edge.cdh.localnet:4040
Spark context available as 'sc' (master = yarn, app id = application_1533103930402_0003).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.3.0.cloudera3
/_/
Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_172)
Type in expressions to have them evaluated.
Type :help for more information.
scala> spark.version
res0: String = 2.3.0.cloudera3
Looking at the path; these files are in place:
[root@edge spark2_2.11]# pwd
/opt/cloudera/parcels/CDAP/master/ext/runtimes/spark2_2.11
[root@edge spark2_2.11]# ls -l
total 1164
-rw-r--r-- 1 root root 44963 Jul 27 17:54 co.cask.cdap.cdap-api-spark2_2.11-5.0.0-SNAPSHOT.jar
-rw-r--r-- 1 root root 1134118 Jul 27 17:54 co.cask.cdap.cdap-spark-core2_2.11-5.0.0-SNAPSHOT.jar
-rw-r--r-- 1 root root 8781 Jul 27 17:54 co.cask.cdap.cdap-spark-python-5.0.0-SNAPSHOT.jar
Thanks very much for your help.
Simon
simo...@gmail.com
Aug 1, 2018, 1:15:12 PM8/1/18
to CDAP User
Hi
I've now tried with 5.0.0 GA - same thing. Can't get anything other than Spark 2.1 (specifically 2.1.0.cloudera1), although I'm running 2.3.0.cloudera3 for CDH.
Environment for driver is completely different between CDAP and CDH based spark. Unfortunately I can't enclose it as it's dozens of pages, but if you'd like it please pm me.
If I look at the 2.1.0.cloudera1 executors page, it's blank.
Thanks for all the help thus far!
Thanks for all the help thus far!
Albert Shau
Aug 1, 2018, 2:19:01 PM8/1/18
to cdap...@googlegroups.com
Hi,
Are you able to see what environment variables are set for the CDAP Master? More specifically, the spark related environment variables like SPARK_HOME. I'm guessing it is somehow getting set to the spark 2.1 home during startup. If so, you can try setting the SPARK_HOME environment vairable explicitly to the home directory that you want.
Regards,
Albert
To view this discussion on the web visit https://groups.google.com/d/msgid/cdap-user/d4fe7fa0-1fe0-4ede-b167-c68c7c7e55a2%40googlegroups.com.
simo...@gmail.com
Aug 1, 2018, 3:11:04 PM8/1/18
to CDAP User
Hi Albert
Thanks for getting back...
I've added SPARK_HOME=/opt/cloudera/parcels/SPARK2/lib/spark2
in all the CDAP safety valves that accept variables.
in all the CDAP safety valves that accept variables.
This results in the following error:
java.util.concurrent.ExecutionException: org.apache.spark.SparkException: Application application_1533138626296_0025 finished with failed status
at com.google.common.util.concurrent.AbstractFuture$Sync.getValue(AbstractFuture.java:294) ~[com.google.guava.guava-13.0.1.jar:na]
at com.google.common.util.concurrent.AbstractFuture$Sync.get(AbstractFuture.java:281) ~[com.google.guava.guava-13.0.1.jar:na]
at com.google.common.util.concurrent.AbstractFuture.get(AbstractFuture.java:116) ~[com.google.guava.guava-13.0.1.jar:na]
at co.cask.cdap.app.runtime.spark.SparkRuntimeService.run(SparkRuntimeService.java:347) ~[co.cask.cdap.cdap-spark-core2_2.11-5.0.0.jar:na]
at com.google.common.util.concurrent.AbstractExecutionThreadService$1$1.run(AbstractExecutionThreadService.java:52) ~[com.google.guava.guava-13.0.1.jar:na]
at co.cask.cdap.app.runtime.spark.SparkRuntimeService$5$1.run(SparkRuntimeService.java:405) [co.cask.cdap.cdap-spark-core2_2.11-5.0.0.jar:na]
at java.lang.Thread.run(Thread.java:748) [na:1.8.0_172]
Caused by: org.apache.spark.SparkException: Application application_1533138626296_0025 finished with failed status
at org.apache.spark.deploy.yarn.Client.run(Client.scala:1153) ~[na:na]
at org.apache.spark.deploy.yarn.YarnClusterApplication.start(Client.scala:1568) ~[na:na]
at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:894) ~[na:na]
at org.apache.spark.deploy.SparkSubmit$.doRunMain$1(SparkSubmit.scala:198) ~[na:na]
at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:228) ~[na:na]
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:137) ~[na:na]
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala) ~[na:na]
at co.cask.cdap.app.runtime.spark.submit.AbstractSparkSubmitter.submit(AbstractSparkSubmitter.java:172) ~[na:na]
at co.cask.cdap.app.runtime.spark.submit.AbstractSparkSubmitter.access$000(AbstractSparkSubmitter.java:54) ~[na:na]
at co.cask.cdap.app.runtime.spark.submit.AbstractSparkSubmitter$5.run(AbstractSparkSubmitter.java:111) ~[na:na]
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) ~[na:1.8.0_172]
at java.util.concurrent.FutureTask.run(FutureTask.java:266) ~[na:1.8.0_172]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) ~[na:1.8.0_172]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) ~[na:1.8.0_172]
... 1 common frames omitted
Two of these safety valves (CDAP Master Service Environment Advanced Configuration Snippet and CDAP Client Advanced Configuration Snippet (Safety Valve) for cdap-conf/cdap-env.sh) also have
SPARK_MAJOR_VERSION=2 already set.
Without setting SPARK_MAJOR_VERSION=2 spark2 isn't used.
Thanks
Thanks
Simon
simo...@gmail.com
Aug 1, 2018, 3:50:13 PM8/1/18
to CDAP User
And sorry - to answer your question:
Looking at the reported environment in both cases:
SPARK_HOME is not set in CDAP spark environment
SPARK_HOME is set is CDH spark environment (correctly - to the SPARK2 parcel location)
Thanks again
Simon Cole
Aug 1, 2018, 3:54:20 PM8/1/18
to cdap...@googlegroups.com
If there’s an email address I can use I can send you a copy of the environment in both cases... can’t seem to post it on here.
You received this message because you are subscribed to a topic in the Google Groups "CDAP User" group.
To unsubscribe from this topic, visit https://groups.google.com/d/topic/cdap-user/MxPmIeor81c/unsubscribe.
To unsubscribe from this group and all its topics, send an email to cdap-user+...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/cdap-user/83979d1d-9a81-461a-a706-d5a3485b2e48%40googlegroups.com.
Albert Shau
Aug 1, 2018, 5:50:57 PM8/1/18
to cdap...@googlegroups.com
Hi,
For SPARK_HOME, all that really matters is the environment variable for the CDAP master process. This is used when the CDAP master examines the local filesystem for the relevant spark libraries to use when submitting the job. I don't think it is carried over to the actual Spark programs that get run in YARN, which is why you don't see it in the environment tab of the Spark UI.
The fact that there is now an error after setting SPARK_HOME at least indicates that different spark libraries are getting picked up now. I know Spark 2.3 is also not supported in CDAP 5.0.0, though I'm unsure whether that always manifests itself as a program failure or if only some subset of Spark functionality breaks. It's possible it's using your Spark2.3 jars now but is hitting the unsupported issues.
The stack trace you pasted is just a generic error saying the program failed for some reason. Do you see any other errors in your logs? The root cause should be in there somewhere. You can also try downgrading to Spark 2.2 and see if that helps.
Regards,
Albert
To view this discussion on the web visit https://groups.google.com/d/msgid/cdap-user/78E35CF4-21F9-4D07-8147-1B5C6460C0C9%40gmail.com.
simo...@gmail.com
Aug 2, 2018, 6:13:30 AM8/2/18
to CDAP User
Hi Albert
Thanks for the info. I've tried downgrading - same / similar thing.
Here's the Spark UI for a CDH spark2-shell:

And the CDAP Spark UI (unchanged!):

If I now add the SPARK_HOME (the CDH one) to the master environment safety valve, the pipeline fails to run. It can't start the 'phase-1' process (it sits unscheduled in YARN) as it errors with:
2018-08-02 10:21:25,209 - ERROR [main:c.c.c.a.r.s.d.SparkContainerLauncher@145] - Exception raised when calling org.apache.spark.deploy.yarn.ApplicationMaster.main(String[]) method java.lang.reflect.InvocationTargetException: null at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) ~[na:1.8.0_172] at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) ~[na:1.8.0_172] at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) ~[na:1.8.0_172] at java.lang.reflect.Method.invoke(Method.java:498) ~[na:1.8.0_172] at co.cask.cdap.app.runtime.spark.distributed.SparkContainerLauncher.launch(SparkContainerLauncher.java:114) ~[co.cask.cdap.cdap-spark-core2_2.11-5.0.0.jar:na] at org.apache.spark.deploy.yarn.ApplicationMaster.main(Unknown Source) [cdap-spark-launcher.jar:na] Caused by: java.lang.IllegalStateException: SparkContextProvider.getSparkContext should only be called in Spark executor process. at com.google.common.base.Preconditions.checkState(Preconditions.java:149) ~[com.google.guava.guava-13.0.1.jar:na] at co.cask.cdap.app.runtime.spark.SparkRuntimeContextProvider.createIfNotExists(SparkRuntimeContextProvider.java:177) ~[co.cask.cdap.cdap-spark-core2_2.11-5.0.0.jar:na] at co.cask.cdap.app.runtime.spark.SparkRuntimeContextProvider.get(SparkRuntimeContextProvider.java:157) ~[co.cask.cdap.cdap-spark-core2_2.11-5.0.0.jar:na] ... 6 common frames omitted
Subsequent pipeline deployments also fail with:
duplicate key: plugin:ScalaSparkProgram:sparkprogram
Thanks
Simon

Matt Wuenschel
Aug 2, 2018, 4:20:15 PM8/2/18
to cdap...@googlegroups.com
Hi Simon,

Did you set Spark2 as a service dependency for CDAP? I've never tried setting SPARK_HOME in a Cloudera manager cluster. When the service dependency is set, Cloudera Manager copies the Spark config to CDAPs process directory and adds it to the class path.
Thanks,
Matt
To view this discussion on the web visit https://groups.google.com/d/msgid/cdap-user/9503a21e-b27a-4743-a9d7-f51679085070%40googlegroups.com.
Simon Cole
Aug 2, 2018, 5:13:53 PM8/2/18
to cdap...@googlegroups.com
Hi Matt, thanks - yes, its set to Spark 2. I’ve tried spark 1 on and off with no change.
Thanks
Simon
Hi Simon,Did you set Spark2 as a service dependency for CDAP? I've never tried setting SPARK_HOME in a Cloudera manager cluster. When the service dependency is set, Cloudera Manager copies the Spark config to CDAPs process directory and adds it to the class path.
To view this discussion on the web visit https://groups.google.com/d/msgid/cdap-user/CADh7uLJ8Ge0jVJ9ReT6K9jGE8jLn3_UMM9y3bxkYKPB21hgG6w%40mail.gmail.com.
Albert Shau
Aug 2, 2018, 5:34:44 PM8/2/18
to cdap...@googlegroups.com
I'm not really sure how the exception:
SparkContextProvider.getSparkContext should only be called in Spark executor process.
could get triggered. I'm wondering if the setMaster("yarn") call is causing an issue, since CDAP does some special spark conf handling in order to provide integration with CDAP datasets and services.
val sc = SparkSession
.builder
.appName("CDAP-Spark-On-Yarn")
.getOrCreate().sparkContext
Could you try getting the SparkContext like:
val sc = SparkSession
.builder
.appName("CDAP-Spark-On-Yarn")
.getOrCreate().sparkContext
If that does not work, maybe we can test if the dynamic scala spark plugin is having issues by trying to run a simple spark pipeline. You can try creating a pipeline that just reads from a file using the File source and writes to the Trash sink (you can find the Trash plugin in the Hub/Market, it just throws away whatever it receives). If you set the engine to Spark, does that pipeline complete successfully or does it error?
Regards,
Albert
To view this discussion on the web visit https://groups.google.com/d/msgid/cdap-user/31AB6483-DF91-4BBA-93A5-3EBAEED1AD6A%40gmail.com.
simo...@gmail.com
Aug 5, 2018, 11:06:17 AM8/5/18
to CDAP User
Thanks Albert. That works great, so I'll use that way from here on.
I've managed to get round the duplicate plugin issue by selecting a different (the latest in the case - 2.2.0-SNAPSHOT) version of the plugin from the toolkit (hover over spark program icon). I can deploy successfully with this (but not the default - 2.0.0)
I've also managed to get my spark 2 history server accepting logins. This has changed things somewhat. I can now see - from the history server view:

.
Version 2.2 The same one I'm running on the cluster. Hooray! :-)
The Spark UI that runs the job reports no executors in use and version 2.1.0.cloudera1.
The history UI reports on executors and has a version of 2.2.0.cloudera2
So do you think there's some versioning strangeness going on somewhere... and where on earth is that 2.1.0.cloudera1 spark version coming from??!
Thanks
Albert Shau
Aug 6, 2018, 1:01:35 PM8/6/18
to cdap...@googlegroups.com
Glad things at least run now. Yeah there is something weird going on in the environment. What Matt commented on is supposed to set things up so that CDAP picks up the correct spark version with the correct configs. I don't think we've run into a case yet where we've had to explicitly set SPARK_HOME.
Can you check if there are any spark 2.1 libraries on the CDAP master node? If not, I think there is some way to configure Spark such that libraries on HDFS are used (spark.yarn.archive I think?), though my memory is pretty fuzzy on how it works. If that config is set on your cluster, it might be that we're picking up spark 2.1 from there?
For the duplicate plugin error, I'm not sure where that is coming from. You should be able to use multiple copies of the same plugin from the same version, as long as each stage has a unique name.
Regards,
Albert
Reply all
Reply to author
Forward
0 new messages