Skip to first unread message

Fil K.
Dec 9, 2016, 4:37:36 PM12/9/16
to Caffe Users
Hi. I am trying to run my updated PascalContext fcn8s,and I have only modified the amount of possible labels ( went for 400+ classes). I have 4GB GPU and would like to train using that ( wondering how long would it take). Anyway,
I have modified my pascalcontext-layers.py ( and modified the NN where it was outputting 21 classes to 400+ classes):
import caffe
import numpy as np
from PIL import Image
import scipy.io
import random
class PASCALContextSegDataLayer(caffe.Layer):
"""
Load (input image, label image) pairs from PASCAL-Context
one-at-a-time while reshaping the net to preserve dimensions.
The labels follow the 59 class task defined by
R. Mottaghi, X. Chen, X. Liu, N.-G. Cho, S.-W. Lee, S. Fidler, R.
Urtasun, and A. Yuille. The Role of Context for Object Detection and
Semantic Segmentation in the Wild. CVPR 2014.
Use this to feed data to a fully convolutional network.
"""
'''
Setup data layer according to parameters:
- voc_dir: path to PASCAL VOC dir (must contain 2010)
- context_dir: path to PASCAL-Context annotations
- split: train / val / test
- randomize: load in random order (default: True)
- seed: seed for randomization (default: None / current time)
for PASCAL-Context semantic segmentation.
example: params = dict(voc_dir="/path/to/PASCAL", split="val")
'''
def setup(self, bottom, top):
params = eval(self.param_str)
self.voc_dir = params['voc_dir'] + '/VOC2010'
self.context_dir = params['context_dir']
self.split = params['split']
self.mean = np.array((104.007, 116.669, 122.679), dtype=np.float32)
self.random = params.get('randomize', True)
self.seed = params.get('seed', None)
# load labels and resolve inconsistencies by mapping to full 400 labels
#lists of 400 labels
print self.context_dir + '/labels.txt'
self.labels_400 = [label.replace(' ','') for idx, label in np.genfromtxt(self.context_dir + '/labels.txt', delimiter=':', dtype=None)]
#TODO: check
# two tops: data and label
if len(top) != 2:
raise Exception("Need to define two tops: data and label.")
# data layers have no bottoms
if len(bottom) != 0:
raise Exception("Do not define a bottom.")
# load indices for images and labels
split_f = '{}/ImageSets/Main/{}.txt'.format(self.voc_dir,
self.split)
self.indices = open(split_f, 'r').read().splitlines()
self.idx = 0
# make eval deterministic
if 'train' not in self.split:
self.random = False
# randomization: seed and pick
if self.random:
random.seed(self.seed)
self.idx = random.randint(0, len(self.indices)-1)
print 'Setup done'
def reshape(self, bottom, top):
# load image + label image pair
self.data = self.load_image(self.indices[self.idx])
self.label = self.load_label(self.indices[self.idx])
# reshape tops to fit (leading 1 is for batch dimension)
print 'Chuj'
top[0].reshape(1, *self.data.shape)
top[1].reshape(1, *self.label.shape)
def forward(self, bottom, top):
# assign output
top[0].data[...] = self.data
top[1].data[...] = self.label
# pick next input
if self.random:
self.idx = random.randint(0, len(self.indices)-1)
else:
self.idx += 1
if self.idx == len(self.indices):
self.idx = 0
def backward(self, top, propagate_down, bottom):
pass
def load_image(self, idx):
"""
Load input image and preprocess for Caffe:
- cast to float
- switch channels RGB -> BGR
- subtract mean
- transpose to channel x height x width order
"""
im = Image.open('{}/JPEGImages/{}.jpg'.format(self.voc_dir, idx))
in_ = np.array(im, dtype=np.float32)
in_ = in_[:,:,::-1]
in_ -= self.mean
in_ = in_.transpose((2,0,1))
return in_
def load_label(self, idx):
"""
Load label image as 1 x height x width integer array of label indices.
"""
label_400 = scipy.io.loadmat('{}/trainval/{}.mat'.format(self.context_dir, idx))['LabelMap']
return label_400ERROR 1:
This is the thing that I am getting when I launch my network:
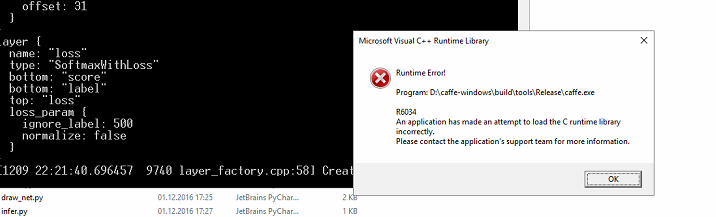
However, when I press OK the code is still running, so not sure what is wrong there.
ERROR 2:
Anyway, my thing is crashing on this:
ERROR 2:
Anyway, my thing is crashing on this:
F1209 22:24:30.634634 9740 syncedmem.cpp:56] Check failed: error == cudaSuccess (2 vs. 0) out of memory
Possible solution that I need help on:
So I was trying to browse for possible solutions, and I found this:
http://stackoverflow.com/questions/33790366/caffe-check-failed-error-cudasuccess-2-vs-0-out-of-memory
and that person resized his image and label to smaller dimensions. Could someone tell me how could I do it in my code ( pascalcontext-layers.py)? Should I do it in my reshape ( actually my load functions) function?
and that person resized his image and label to smaller dimensions. Could someone tell me how could I do it in my code ( pascalcontext-layers.py)? Should I do it in my reshape ( actually my load functions) function?
I appreciate any help. Thank You!
Reply all
Reply to author
Forward
0 new messages