Optimal block size

nichol...@gmail.com
1. Given a program P and a block size B, is it possible to say definitively whether or not B is the "optimal" block size for P? In other words, is it always clear that B is optimal for P if indeed it really is, and always clear that B isn't optimal if indeed it really isn't? (If there are multiple "optimal" sizes, we'll take the least such to be "the" optimal one.) My feeling is that the answer is yes, and the function `optimal : Program -> Nat -> Bool` is computable.
2. Given a program P, is there a computable method for determining its optimal block size? That is, can we always find a number B such that B is optimal for P? My feeling is that this is not possible, because if it were it could be used to solve the halting problem. It feels awfully close to dynamic analysis on arbitrary programs, and that generally can't be done. That's not a proof, just a hunch.
3. Among programs with N states and K colors, what is the greatest optimal block size?
Now, if the answers to questions 1 and 2 really are yes and no, then question 3 should give rise to a Busy Beaver-like sequence. Call it the Blocking Beaver problem, or BLOB. What can be said about BLOB? What are its early values? How do its values for N-state/2-color compare to its values for 2-color/N-state?
One way to understand blocks is that they are a program's way of implementing a more expressive color palette. A program can manage cells in blocks of size B in order to bootstrap its way from K colors to K^B colors, and then implement its logic in that higher order language. From this perspective, BLOB asks: what is the most expressive higher order language that can be implemented in some program class?

Tristan Stérin
1. m < n (meaning that P is good abstraction of M)
2. p > k (bigger block size)
3. p < k*n (we don't want to cheat with an alphabet of size k*n and m = 1)
4. P "simulates" M with a tight definition of simulation (for example, Definition 8 in https://arxiv.org/pdf/2107.12475.pdf)
In our work https://arxiv.org/pdf/2107.12475.pdf, we did something similar in the other direction where we found a conceptually simple 5-state 4-symbol machines that we simulated with a 15-state 2-symbol machines. Now, the issue that I have is that in that constructive approach already, we used encoding tricks where sometimes the 2-symbol machine uses a block size of 2 but sometimes switches to a block size of 1 in order to reduce the number of states it is using (without these tricks the 2-symbol machine would have had ~20 states).
Tristan Stérin

Shawn Ligocki
- For tape compress: We run the machine some number of steps (maybe 1k), find the step at which the tape was least compressed with block-size 1, and find the block size that would compress the tape the most. As long as we run for enough steps, this seems to work well.
- For chain step optimization: We try running using different multiples of the block size identified in phase (1) to see which multiple performs the most chain steps. This also tends to work pretty well, although you sometimes need to run it for a while to notice things.
- F(a, b, c) = 0^inf 110^a 1^b 1010^c A> 0^inf
--
You received this message because you are subscribed to the Google Groups "Busy Beaver Discuss" group.
To unsubscribe from this group and stop receiving emails from it, send an email to busy-beaver-dis...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/busy-beaver-discuss/fba7e936-7906-4d71-a1a8-8a86bf07766dn%40googlegroups.com.
Shawn Ligocki
3. Among programs with N states and K colors, what is the greatest optimal block size?
Tristan Stérin
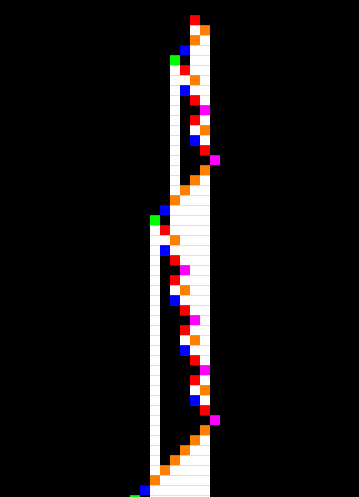
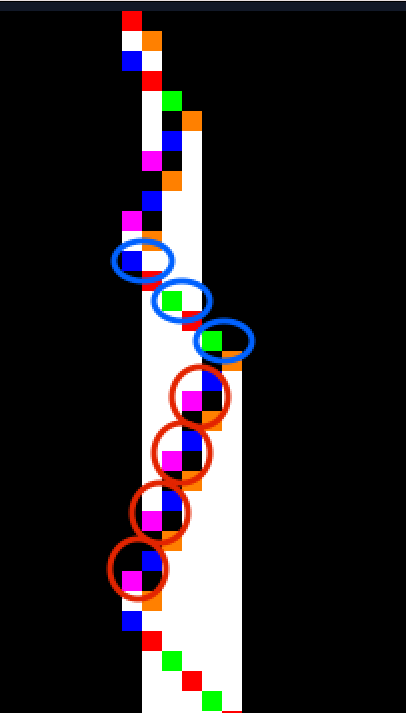
- Blue ovals are the "optimal" size-2 blocks to consider when the machine is going right and they start on even tape positions
- Red ovals are the "optimal" size-2 blocks to consider when the machine is going left but they are just shifted by 1 and not by 2 compared to blue ovals, making them overlap and changing the relevant block partition of the tape (temporarily).
Tristan Stérin
I believe that it is only within that model that you can, with satisfaction, reduce the behavior of the machine of my last email to its simplest essence: "Go right while you read x, extend the tape, then go left while you read y, extend the tape, and restart".

{kind=link}
{kind=link}
uni...@fu-solution.com
> Pavel: I noticed you mentioned something about dynamic tape
> compression before. Have you found a way to apply different block
> sizes to different sections of the tape? I have thought about this,
> but it is non-trivial, opening up a whole new can of worms of when to
> compress at different block sizes and when to re-compress, etc.
just... look at examples:
* `10{10}^n...` -> `{10}^(n+1)...`
* `1010...` -> `{10}^2...`
* repeat while you can compress something
the hard part is that macro machines handle trivial tape
transitions/proofs for you and then you can get far with a simple
proving system on top of them.
once you can't use macro machines, you need nested proofs (rules) from
the beginning.
nichol...@gmail.com
1RB_0RC__1LB_1LD__0RA_0LD__1LA_1RC
This one enters into Lin recurrence after 158,491 steps with a period of 17,620 steps. Its behavior is impossible to tell just from looking at it.
Well, I did some searching and apparently its optimal block size is 708. With that number, a simple prover can show that it will loop forever. As far as I can tell, this is the least number that "makes sense" out of Boyd's program.
Can anyone verify this? Or come up with a better (i.e. lower) block size?
uni...@fu-solution.com
"closed position set"
https://discord.com/channels/960643023006490684/1028747034066427904
> You received this message because you are subscribed to the Google
> Groups "Busy Beaver Discuss" group.
> To unsubscribe from this group and stop receiving emails from it,
> send an email to busy-beaver-dis...@googlegroups.com.
> To view this discussion on the web visit
> [1].
>
>
> Links:
> ------
> [1]
> https://groups.google.com/d/msgid/busy-beaver-discuss/b215a8dc-f1c4-4a21-b64a-cf8ff28a1694n%40googlegroups.com?utm_medium=email&utm_source=footer
Shawn Ligocki
$ python Code/Lin_Recur_Detect.py <(echo 1RB0RC_1LB1LD_0RA0LD_1LA1RC)
parameters {
find_min_start_step: true
}
result {
success: true
start_step: 158491
period: 17620
offset: 118
elapsed_time_us: 4248145
}
halt_status {
is_decided: true
inf_reason: INF_LIN_RECUR
}
$ python Code/Quick_Sim.py <(echo 1RB0RC_1LB1LD_0RA0LD_1LA1RC) -n118
...
Steps: Times Applied:
Total: 10^5.2 20
Macro: 10^5.2 19
Chain: 0
Rule: 0
Rules proven: 0
Failed proofs: 0
Prover num past configs: 20
Tape copies: 0
Elapsed time: 0.14205193519592285
0000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000^inf 0000000000000000000000000000000000000000000000000000000000000000000000000000000000000000001011101101011010110101101011^1 0101101011011011011010100101010110101101101101101101101010110110100101101101011011011011011011010010110110101101101010^1 1101010101101010101101010010100101010110101101011011011011011011010010101011010110110101001011011011011011011011011010^1 1101101101101011011010010110101101101010101101010010110110110110110110100101010110101101101101101101101101101011011011^1 0101001010101101101101011010110101101101010110110100101001011011010110110110110101001011011010100101101011011011011010^1 1101010010110110101010110101101101011011011010010101011010101011010110110110100101010110101010110101101101101010110101^1 1011011011011010110110101101101101101101101101101011010100101001010101101011011010110110110101011010100101010110110110^1 (1101011011010010110110110101011010100101101101011010101011010110110101101011011010110110110100101001010101101101101000) A> 0000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000^inf
Num Nonzeros: 10^2.7 500
Turing Machine proven Infinite
Reason: INF_CHAIN_STEP
Quasihalt:
is_decided: true
--
You received this message because you are subscribed to the Google Groups "Busy Beaver Discuss" group.
To unsubscribe from this group and stop receiving emails from it, send an email to busy-beaver-dis...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/busy-beaver-discuss/b215a8dc-f1c4-4a21-b64a-cf8ff28a1694n%40googlegroups.com.
nichol...@gmail.com
How about for the really long LR that you (Shawn) found?
1RB_0LC__1RD_1LC__0LA_1LB__1LC_0RD
Enters into a recurrence period of 7,129,704 steps after 309,086,174 steps. Your LR detector shows an offset of 512.
Maybe it comes down to some implementation detail, but I can only get it to run by taking the base program, then 5-cell macro on top of that, then 2-cell macro on top of that. That gives a total block size of (2^5)^2 = 1,024.
Regarding Discord, does anyone have a fresh invite? Pavel's link didn't work for me and neither does the one on the BB challenge site.
Tristan Stérin
--
You received this message because you are subscribed to a topic in the Google Groups "Busy Beaver Discuss" group.
To unsubscribe from this topic, visit https://groups.google.com/d/topic/busy-beaver-discuss/al-Ima3rfX8/unsubscribe.
To unsubscribe from this group and all its topics, send an email to busy-beaver-dis...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/busy-beaver-discuss/b1ed595c-bd48-44e8-8618-21bb492fceb8n%40googlegroups.com.
Tristan Stérin
Shawn Ligocki
Maybe it comes down to some implementation detail, but I can only get it to run by taking the base program, then 5-cell macro on top of that, then 2-cell macro on top of that. That gives a total block size of (2^5)^2 = 1,024.
--
You received this message because you are subscribed to the Google Groups "Busy Beaver Discuss" group.
To unsubscribe from this group and stop receiving emails from it, send an email to busy-beaver-dis...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/busy-beaver-discuss/b1ed595c-bd48-44e8-8618-21bb492fceb8n%40googlegroups.com.
nichol...@gmail.com
Here are the facts: I can run that long LR program with a 5-block macro stacked with a 2-block macro (that is: base -> 5-block -> 2-block). The [5, 2] sequence works for me, but not similar sequences; not [2, 5], not [10], not [32], not [10, 2], not [5, 4]. [5, 2, 2] does work -- base -> 5-cell -> 2-cell -> 2-cell.
Clearly powers of 2 are swirling around. What's going on here?