Multiplicative or Additive STDP by default?
49 views
Skip to first unread message

Henry Miller
Aug 12, 2020, 11:37:29 PM8/12/20
to Brian
I refer to the tutorial on https://brian2.readthedocs.io/en/stable/examples/standalone.STDP_standalone.html. Is the rule here additive STDP or multiplicative by default? If it is additive then how to I make it multiplicative since I know it only is possible by using STDP class on brian1 which has deprecated? Thank you guys!

Felix Kern
Aug 13, 2020, 12:45:33 AM8/13/20
to Brian
The example is additive. I'm not entirely clear on what you mean by multiplicative - the way you're asking makes me think it's something more complicated than simply the weight change being proportional to the existing weight. The latter would be straightforward to implement based on the example (see also https://brian2.readthedocs.io/en/stable/resources/tutorials/2-intro-to-brian-synapses.html for a worked example of additive STDP). If it's not that, could you share a little more detail on what your learning rule is supposed to look like?
Best, Felix
Henry Miller
Aug 13, 2020, 1:34:00 AM8/13/20
to Brian
Hey thanks for the reply!
I have attached the png showing the STDP function.
Additive STDP means we set mu_minus and mu_plus = 0, in particular, such behaviour results in a bimodal distribution which is shown in the link in provided, but multiplicative means the second term (w / wmax ) or (1 - w/wmax) is raised to some power in order to adjust the weights (Self-adaptive) , ultimately to generate a unimodal distribution of the final weights. What I am trying to do is to implement the multiplicative rule, but I am not sure if it is possible to do this on Brian or how I can modify the default example to illustrate this behaviour? Thanks!
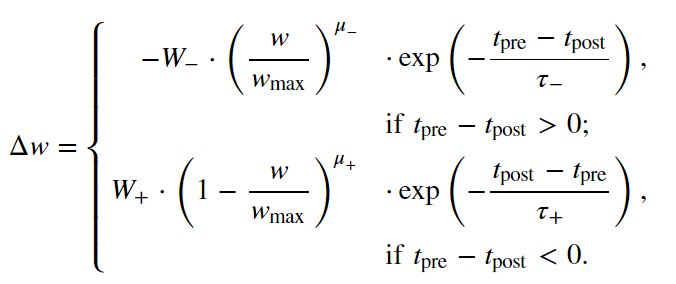{kind=link}
{kind=link}
Felix Kern
Aug 13, 2020, 4:25:15 AM8/13/20
to Brian
I think you'll want to keep the activity traces (Apre, Apost) unchanged from the example, and instead multiply the weight-dependent factor directly into the weight update, e.g. like so:
on_post = '''
Apost += dApost
w = clip(w + Apre * (1-w/gmax), 0, gmax)
'''
Like this, the activity trace remains a faithful representation of past spiking activity, and the weight dependence doesn't propagate through time. I'm fairly confident (though only by intuition, not by derivation; I'll leave that one up to you) that this makes the model equivalent to your formal description.
Hope that helps!
Henry Miller
Aug 13, 2020, 7:07:24 AM8/13/20
to Brian
Hey thanks a lot!
By the way, just 1 last question. From many STDP I have seen, mostly are on the order of milliseconds. Suppose I have a STDP on the order of microsecond (STDP window function happens on the order of microsecond), then does my LIF neuron time constant need to be on the order of microsecond as well? Or it can remain as millisecond? Thanks!
By the way, just 1 last question. From many STDP I have seen, mostly are on the order of milliseconds. Suppose I have a STDP on the order of microsecond (STDP window function happens on the order of microsecond), then does my LIF neuron time constant need to be on the order of microsecond as well? Or it can remain as millisecond? Thanks!
Felix Kern
Aug 13, 2020, 7:15:33 AM8/13/20
to Brian
The two time scales don't interact, so there's no a priori problem with them being vastly different. On the technical side, though, you'll want to make sure your simulation time step is small enough, since spikes are only emitted at that resolution.
Henry Miller
Aug 13, 2020, 7:23:49 AM8/13/20
to Brian
Thank you very much! You are a life saver!!!!! :)
Reply all
Reply to author
Forward
0 new messages