Intel’s BigDL on Databricks
259 views
Skip to first unread message

Linbo Jin
Feb 9, 2017, 8:32:35 PM2/9/17
to BigDL User Group
Hi guys,
Databricks' tutorial about BigDL: https://databricks.com/blog/2017/02/09/intels-bigdl-databricks.html
Example notebook: https://databricks-prod-cloudfront.cloud.databricks.com/public/4027ec902e239c93eaaa8714f173bcfc/5669198905533692/2626293254583012/3983381308530741/latest.html
Best wishes,
By Linbo

Maurice Nsabimana
Nov 12, 2017, 9:39:49 PM11/12/17
to BigDL User Group
Hi Linbo:
This is a great (scala) tutorial, thank you! Are you aware of similar examples in Python, specifically using BigDL (version 0.2.0) in Python on Databricks?
I am able to import from the PyPi library but get the following error upon calling init_engine() in a databricks notebook with the PyPi version attached:
'JavaPackage' object is not callable
I first tried to manually load a precompiled JAR file, without success. Thank you!
Best wishes,
/Maurice

Yiheng Wang
Nov 12, 2017, 10:01:06 PM11/12/17
to Maurice Nsabimana, BigDL User Group
Hi Maurice
There's a bigdl python tutorial repo on github.
Does it meet your requirement?
Regards,
Yiheng
--
You received this message because you are subscribed to the Google Groups "BigDL User Group" group.
To unsubscribe from this group and stop receiving emails from it, send an email to bigdl-user-group+unsubscribe@googlegroups.com.
To post to this group, send email to bigdl-user-group@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/bigdl-user-group/459509c6-f63b-49c9-bfa4-13559212cb97%40googlegroups.com.
Maurice Nsabimana
Nov 12, 2017, 10:15:58 PM11/12/17
to BigDL User Group
Thank you for your prompt reply, Yiheng.
I am familiar with those tutorials, which were very useful. My main question is about using BigDL on Databricks in Python, hence my question on this particular thread.
Are you aware of similar examples in Python, specifically using BigDL (version 0.2.0) in Python on Databricks? Thank you.
Best,
/Maurice
On Sunday, November 12, 2017 at 10:01:06 PM UTC-5, yihengw wrote:
Hi MauriceThere's a bigdl python tutorial repo on github.Does it meet your requirement?Regards,Yiheng
On Mon, Nov 13, 2017 at 10:39 AM, Maurice Nsabimana <muta...@gmail.com> wrote:
Hi Linbo:This is a great (scala) tutorial, thank you! Are you aware of similar examples in Python, specifically using BigDL (version 0.2.0) in Python on Databricks?I am able to import from the PyPi library but get the following error upon calling init_engine() in a databricks notebook with the PyPi version attached:'JavaPackage' object is not callableI first tried to manually load a precompiled JAR file, without success. Thank you!Best wishes,/Maurice
On Thursday, February 9, 2017 at 8:32:35 PM UTC-5, Linbo Jin wrote:Hi guys,Databricks' tutorial about BigDL: https://databricks.com/blog/2017/02/09/intels-bigdl-databricks.htmlExample notebook: https://databricks-prod-cloudfront.cloud.databricks.com/public/4027ec902e239c93eaaa8714f173bcfc/5669198905533692/2626293254583012/3983381308530741/latest.htmlBest wishes,By Linbo
--
You received this message because you are subscribed to the Google Groups "BigDL User Group" group.
To unsubscribe from this group and stop receiving emails from it, send an email to bigdl-user-gro...@googlegroups.com.
To post to this group, send email to bigdl-us...@googlegroups.com.
Yiheng Wang
Nov 13, 2017, 2:15:01 AM11/13/17
to Maurice Nsabimana, BigDL User Group
Dear Maurice
Unfortunately, I'm not aware.. :-(
Regards,
Yiheng
To unsubscribe from this group and stop receiving emails from it, send an email to bigdl-user-group+unsubscribe@googlegroups.com.
To post to this group, send email to bigdl-user-group@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/bigdl-user-group/5a05a74c-4e92-4ad3-8a9e-cdc0e62d2494%40googlegroups.com.

Mohammed Elhmadany
Aug 30, 2022, 8:22:05 PM8/30/22
to User Group for BigDL
Hi Maurice,
did you solve this error?
I have the same situation when loading openvino model
" est = Estimator.from_openvino(model_path='/databricks/driver/my_model.xml') "
I followed the installation steps provided in the tutorial ( https://bigdl.readthedocs.io/en/latest/doc/UserGuide/databricks.html#installing-bigdl-java-libraries ) and I get this error message related to the java library doesn't import in a correct way as I think
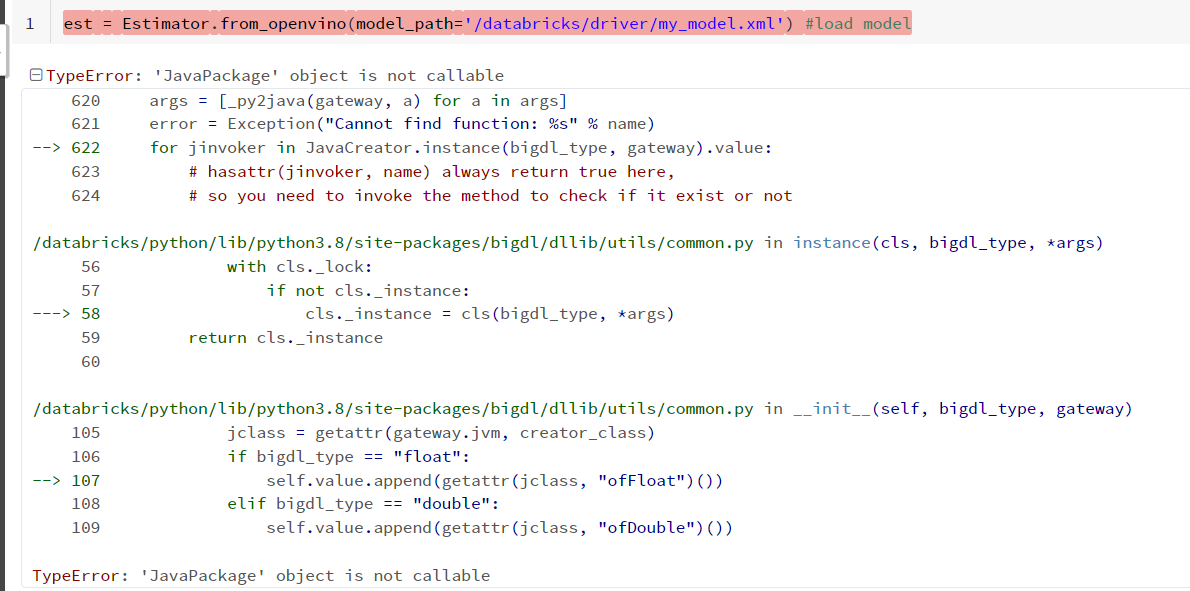
I have the same situation when loading openvino model
" est = Estimator.from_openvino(model_path='/databricks/driver/my_model.xml') "
I followed the installation steps provided in the tutorial ( https://bigdl.readthedocs.io/en/latest/doc/UserGuide/databricks.html#installing-bigdl-java-libraries ) and I get this error message related to the java library doesn't import in a correct way as I think
Installing BigDL Python libraries DLLiB and Orca wheel package and DLLib jar package

so kindly any advice.
To view this discussion on the web visit https://groups.google.com/d/msgid/bigdl-user-group/5a05a74c-4e92-4ad3-8a9e-cdc0e62d2494%40googlegroups.com.

huangka...@gmail.com
Aug 30, 2022, 9:24:15 PM8/30/22
to User Group for BigDL
Hi,
From you screenshots, I suppose you are missing the jar for Orca. Both jars and whls for DLlib and Orca are needed. You can add the jar and the error should be resolved.
Feel free to tell us if you have further questions.
Best,
Kai
Mohammed Elhmadany
Sep 1, 2022, 5:30:22 PM9/1/22
to User Group for BigDL
Hi
Kai
thank you for your guidance and support
yes, now I added the Orca jar file with the same timestamp for the same Spark version, and the java error was resolved as I think but now I have another error message
thank you for your guidance and support
yes, now I added the Orca jar file with the same timestamp for the same Spark version, and the java error was resolved as I think but now I have another error message
"
Py4JJavaError: An error occurred while calling o951.initEngine. :
--> the Installed BigDL package whls & jars

here is my notebook with the error message for your review and suggestions:
com.intel.analytics.bigdl.dllib.utils.InvalidOperationException: Can't parser master local[*, 4]
--> the Installed BigDL package whls & jars
here is my notebook with the error message for your review and suggestions:
huangka...@gmail.com
Sep 2, 2022, 7:22:01 AM9/2/22
to User Group for BigDL
Hi Mohammed,
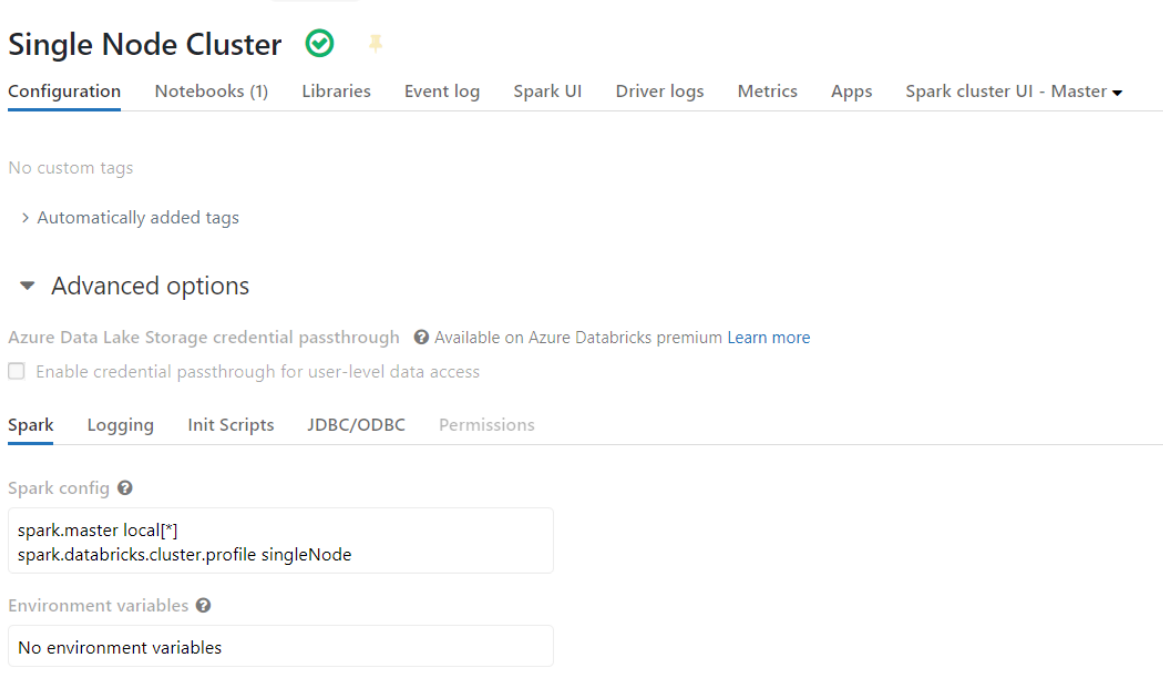
The default master for local on Databricks is local[*, 4], which is not recognized by BigDL.
You can change the master to local[*] or local[4] in advanced options to resolve this issue. See the following figure:
Feel free to tell us if you have further questions.
Thanks,
Kai
Mohammed Elhmadany
Sep 2, 2022, 9:56:10 AM9/2/22
to User Group for BigDL
Hi
Kai
thank you very much now working fine.
regards,
thank you very much now working fine.
regards,
Mohammed Elhmadany
Nov 5, 2022, 7:44:04 PM11/5/22
to User Group for BigDL
Hi
Kai,
now I try to run my model on databricks cluster multiple nodes say 1 worker with 4 cores and my spark cluster configurations are as follows:-
now I try to run my model on databricks cluster multiple nodes say 1 worker with 4 cores and my spark cluster configurations are as follows:-
spark.hadoop.mapred.max.split.size 100 #ref:https://kb.databricks.com/en_US/execution/increase-tasks-per-stage
spark.serializer org.apache.spark.serializer.JavaSerializer
spark.databricks.delta.preview.enabled true
spark.sql.files.openCostInBytes 100
spark.executor.cores 4
spark.driver.maxResultSize 10g
spark.default.parallelis 4
spark.cores.max 8
spark.sql.adaptive.enabled false
spark.sql.files.maxPartitionBytes 200
spark.default.parallelism 4
spark.driver.cores 4
my issue now is one core only is used while applying any action on my spark data frame I read from storage in Azure Data Lake Storage and my container has 320 images with a total size of about 7 MB I tried all possible configurations that I found as mentioned in the above but unfortunately, I am unable to achieve full parallelism or full utilization of my cluster cores only one task is active using only one core and that leading to take more time. on the other hand, while I was working on local mode (only one node cluster) I observed spark use all cores available and the number of tasks =4 when the driver is configured by 4 cores.
so kindly any advice.
best,
mohammed
mohammed

Xin Qiu
Nov 6, 2022, 9:24:05 PM11/6/22
to User Group for BigDL
Hi, mohammed
If you are using 1 worker with 4 cores, the
spark.cores.max 8 should be 4.The active tasks is dynamic number, it dependens on the stages of job. You had better compare the same stage between local and cluster mode, in the Stage page. It will should you how many tasks are running in the same time.
Bests,
-Xin

YASH HASMUKH CHAUHAN
Mar 18, 2024, 7:12:26 PM3/18/24
to User Group for BigDL
Hello Everyone,
I am a Masters student from India, trying to get familiar to BigDL , I am using Databricks Community edition . I am getting same error , that is "TypeError: 'JavaPackage' object is not callable" when I run "init_nncontext()".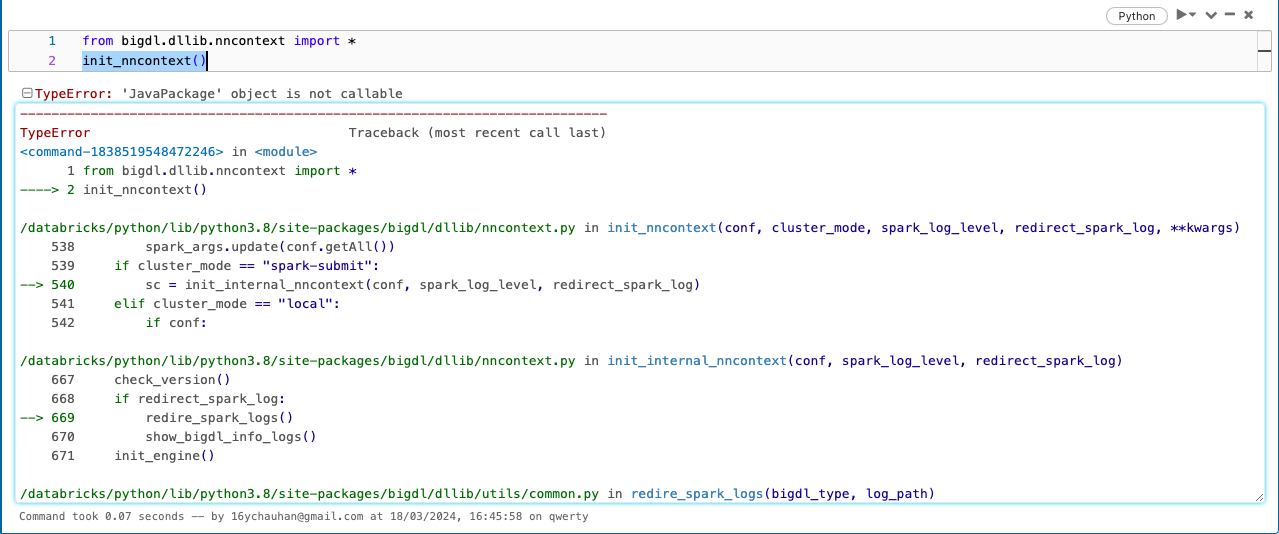 I have tried multiple ways of installing bigDL in databricks , and i am getting same error .
In this scenario I have installed from pypi as i am working in python.
I have tried multiple ways of installing bigDL in databricks , and i am getting same error .
In this scenario I have installed from pypi as i am working in python. 
can you guys please help me out here ?
I am trying to get through this since many days but didnt got lucky!!!!
I am a Masters student from India, trying to get familiar to BigDL , I am using Databricks Community edition . I am getting same error , that is "TypeError: 'JavaPackage' object is not callable" when I run "init_nncontext()".
I have tried multiple ways of installing bigDL in databricks , and i am getting same error .
In this scenario I have installed from pypi as i am working in python.can you guys please help me out here ?
I am trying to get through this since many days but didnt got lucky!!!!
Xin Qiu
Mar 18, 2024, 8:43:03 PM3/18/24
to User Group for BigDL
Hi, you can follow this guide https://bigdl.readthedocs.io/en/latest/doc/UserGuide/databricks.html
Reply all
Reply to author
Forward
0 new messages