Make a prediction from spark image data frame on Openvino Estimator

Mohammed Elhmadany
I want to do inference for the images from the spark data frame after applying preprocessing steps that are required but I am stuck in the prediction step and I do not how to deal with it so kindly any advice.
My model takes a 3d array with shape(3,550,550) and I am able to make a prediction successfully by converting the output tensor from the preprocessing with its length (907500) into a 3d array using the NumPy package does not spark task and the result was fine but I want to infer from the data frame because I have a large scale of images and I want to do preprocessing in a distributed manner. At the same time, I can not do prediction using a data frame as mentioned, in addition, I tried to convert to a 3d array in a data frame but also failed to obtain the result. so is this the correct way to do inference from the spark data frame?



Chen Yita
Chen Yita


return convert_predict_rdd_to_dataframe(data, result_rdd)
../../../../../src/bigdl/orca/learn/utils.py:198: in convert_predict_rdd_to_dataframe
type = combined_rdd.map(lambda data: data[1]).first()
from bigdl.orca.data import SparkXShards
from bigdl.orca.learn.openvino import Estimator
from bigdl.orca import init_orca_context, OrcaContext
sc = init_orca_context(cores=10, memory="16g", conf={"spark.driver.maxResultSize": "5g"})
spark = OrcaContext.get_spark_session()
model_path = "/d1/model/openvino2020_resnet50/resnet_v1_50.xml"
est = Estimator.from_openvino(model_path=model_path)
rdd = sc.range(0, 2048, numSlices=10)
df = rdd.map(lambda x: [x, np.random.rand(150528).tolist()]).toDF(["index", "input"])
batch_size = 200
def to_shards(iter):
cnt = 0
index_list = []
input_list = []
for row in iter:
index_list.append(row["index"])
input_list.append(np.array(row["input"]).reshape([3, 224, 224]))
cnt += 1
if cnt == 200:
yield {"index": index_list, "x": np.array(input_list)}
cnt = 0
index_list = []
input_list = []
if len(index_list) > 0:
yield {"index": index_list, "x": np.array(input_list)}
shards = SparkXShards(df.rdd.mapPartitions(lambda iter: to_shards(iter)))
result_shards = est.predict(shards, batch_size=batch_size)
result_c = result_shards.collect()
Mohammed Elhmadany
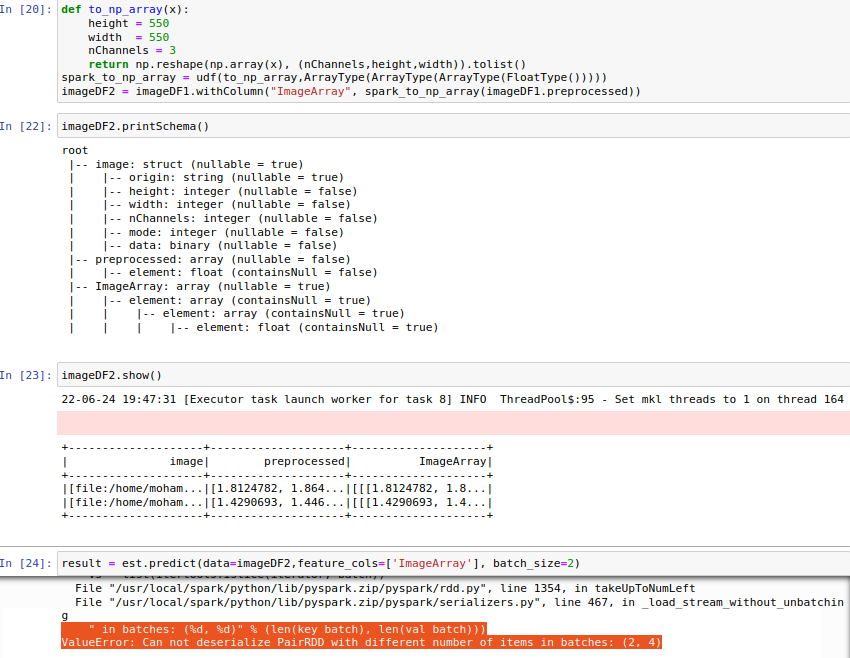
I followed your provided example method and applied that on prediction using two different input formats one is a spark data frame and the other is a NumPy array of images when I test my model in prediction on spark data frame input I get this error message and I don't understand how to solve or which parameter should I need to pay attention here is the error


regards,
Chen Yita
print("infer_result_len", len(infer_request.output_blobs[outputs[0]].buffer))
print("output_len", len(infer_request.output_blobs[outputs[0]].buffer[:elem_num]))

Mohammed Elhmadany
I apologize for taking so long to reply. I have just noted your suggestion about testing my model in your spark cluster, in addition, as I mentioned before about the batch size in the prediction function for spark data frame input now it is working fine with me but currently, I am stuck, I have an issue in applying any action methods like (collect, show, count ) on the output result data frame from prediction function as demonstrated on the following image I face I get this error message related the datatype as I understand and I don't know how to solve or deal with, On the other hand, it's working fine and gives me the desired output result parameter when using the NumPy array as input.
so I attached here the link to the compressed file containing my notebook describing my steps and the openvino model file on google driver. for your review and testing
https://drive.google.com/file/d/1uPLLVlb73Ja0NDjb-w_20yT81wGAhF70/view?usp=sharing

Chen Yita
shards, _ = dataframe_to_xshards(df,
validation_data=None,
feature_cols=["input"],
label_cols=None,
mode="predict")
result_rdd = est.predict(shards, batch_size=4)
result_c = result_rdd.collect()
Mohammed Elhmadany
Best Regards,
Chen Yita
+-----+--------------------+--------------------+--------------------+--------------------+--------------------+
|index| input| tf.identity| tf.identity_1| tf.identity_2| tf.identity_3|
+-----+--------------------+--------------------+--------------------+--------------------+--------------------+
| 0|[[[0.524009594978...|[[[0.7539101, 1.1...|[[[-0.8792659, 0....|[[[[3.1407502, 0....|[[[0.97345, 0.002...|
| 1|[[[0.410070298834...|[[[0.7540849, 1.1...|[[[-0.87942857, 0...|[[[[3.149644, 0.2...|[[[0.97356623, 0....|
| 2|[[[0.855045850696...|[[[0.7491907, 1.1...|[[[-0.8787027, 0....|[[[[3.1266716, 0....|[[[0.97360265, 0....|
| 3|[[[0.005269990329...|[[[0.74902785, 1....|[[[-0.87985, 0.14...|[[[[3.1379035, 0....|[[[0.9735233, 0.0...|
| 4|[[[0.524009594978...|[[[0.7539101, 1.1...|[[[-0.8792659, 0....|[[[[3.1407502, 0....|[[[0.97345, 0.002...|
| 5|[[[0.410070298834...|[[[0.7540849, 1.1...|[[[-0.87942857, 0...|[[[[3.149644, 0.2...|[[[0.97356623, 0....|
| 6|[[[0.855045850696...|[[[0.7491907, 1.1...|[[[-0.8787027, 0....|[[[[3.1266716, 0....|[[[0.97360265, 0....|
| 7|[[[0.005269990329...|[[[0.74902785, 1....|[[[-0.87985, 0.14...|[[[[3.1379035, 0....|[[[0.9735233, 0.0...|
+-----+--------------------+--------------------+--------------------+--------------------+--------------------+
However, the dataframe implementation takes more time and consumes more memory than the xShards implementation. Because the spark dataframe only supports Array[Array[...]] and the performance of ndarray.tolist() is not satisfying. And we are trying to optimize it.
I recommend you to use xShards for OpenVINO inference. You can follow the steps below:
1. Create the SparkXShards (https://bigdl.readthedocs.io/en/latest/doc/Orca/Overview/data-parallel-processing.html#xshards-distributed-data-parallel-python-processing)
You can read the image files using spark dataframe and convert it to xShards of pandas dataframe using orca.utils.to_pandas. Or you can create a spark rdd with image file paths in each partition, and create an xShards using SparkXShards(rdd), then you can use shards.transform_shard(your_func) to do file reading, preprocessing, etc.
2. Prepare xShards for the estimator.predict
Transform the xShards to each partition is a dictionary of {'x': batched input ndarray} using shards.transform_shard(your_func) , then feed into the estimator predict function.
The Memory Issue you mentioned before "usage memory is only 342 MB after that value my spark session being crashed":
The storage memory in spark ui is used for storing all of the cached data, broadcast variables are also stored here. Any persist option which includes MEMORY in it, spark will store that data in this segment. Because the estimator only broadcasts the openvino models, and this 342MB is the memory used to store the broadcasted OV model, so it is always 342MB when your spark session crashed.
I tested on local with 5g driver memory, 48 images when the input is ndarray, 34 images xshards, and 54 images spark dataframe (partition number: 2, batch size 4). And on yarn cluster mode, 190 images xshards (num_nodes:2, executor_memory: 10g, driver_memory: 10g).
I have observed the excessive memory usage issue, and I'm trying to locate and solve it.
Best Regards,Mohammed Elhmadany
Thank you for your response and assistance much appreciated
I tested the inference prediction using a spark data frame and it worked fine. in addition, as you mentioned the same situation here, the data frame implementation takes more time and consumes more memory than the xShards.
My problem now is:-
I want to need to create a big data cluster with multiple nodes for processing my data about one million images and the expected size of about 20 GB just to store the images data. After running and testing the code on my local machine (by using VMware ) the storage memory utilized on spark cluster local mode to process 56 images as mentioned at the top is founded at 1.1 GB (as the image attached from spark UI).
I intend to create the cluster on Azure Databricks where I tested and install all the required libraries and tested on a single node and the performance monitor the storage memory utilized on spark cluster local mode to process 16 images is founded 397 MB (as attached image spark UI on Databricks )
So my question is How do estimate and configure my cluster on Databricks by the required capacity needed for RAM Memory and the number of cores for each node and for sure the number of cluster nodes needed to decrease the total time of execution to less than 1 second per image as an average time.
So in this situation, as I understand the total cluster memory should be more than 25000 GB is that make sense!? but I’ve tried and I can’t figure out what I’m missing.so I appreciate any advice or guidance on how to get out.
.


--
You received this message because you are subscribed to a topic in the Google Groups "User Group for BigDL" group.
To unsubscribe from this topic, visit https://groups.google.com/d/topic/bigdl-user-group/WQjdzfHs9Qg/unsubscribe.
To unsubscribe from this group and all its topics, send an email to bigdl-user-gro...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/bigdl-user-group/81bf465a-19e9-4eab-b68e-05f8f3aea1fan%40googlegroups.com.
Chen Yita
The storage memory changed because the xshards will be computed and cached once it was created. It means every intermediate shards will be cached in the storage memory. You can switch off the eager mode using OrcaContext._eager_mode=False
Mohammed Elhmadany
hope you are doing well,
Are there any updates about this issue (the excessive memory usage issue that you mentioned above) or any solution I can try where in my situation on the Azure Databrics cluster I am not able to process more than 2000 images (only 50 megabytes total size and my model is openvino with the size 100 megabyte ) on the configured cluster of 6 executors with 128GB Memory and 32 cores for each node! and I did not know exactly why is that the massive memory required in my case so I appreciate any advice or guidance on how to get out.
best regards,
Chen Yita

Chen Yita


ge song
Good day!
This SONG Ge, a software engineer from BigDL team. Based on our communication before, we sincerely want to invite you to join our user partnership program! Would you like to have a conversation with us to discuss in detail the application of BigDL in your project? Our team will always provide the most efficient support with BigDL Orca (an excellent distributed machine learning library) and work with you to complete your project!
Best Regards,
SONG Ge