BigARTM for semi-supervised learning
201 views
Skip to first unread message

juliaserebr
Jul 4, 2018, 11:13:33 AM7/4/18
to bigartm-users
Hi,
A part of my data is labeled and I am trying to use BigARTM for classification. If I understand correctly, I should use LabelRegularizationPhiRegularizer, but there is no documentation or examples for it. Do you have any tutorials or documentation for python interface?
Thank you,
Julia
A part of my data is labeled and I am trying to use BigARTM for classification. If I understand correctly, I should use LabelRegularizationPhiRegularizer, but there is no documentation or examples for it. Do you have any tutorials or documentation for python interface?
Thank you,
Julia

Oleksandr Frei
Jul 4, 2018, 11:40:21 AM7/4/18
to juliaserebr, bigartm-users
Hi,
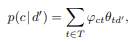
BigARTM classification is fairly simple feature, but unfortunately there is no tutorial.
Basically, you need to set predict_class_id argument in artm.transform:
- predict_class_id (str) – class_id of a target modality to predict. When this option is enabled the resulting columns of theta matrix will correspond to unique labels of a target modality. The values will represent p(c|d), which give the probability of class label c for document d.
More details about classification are here:
http://www.machinelearning.ru/wiki/images/d/da/Voron17fast.pdf (setionc IX.B - Multimodal ARTM / The class modality)
First you need to infer topics for a given document. Later, you use
to find distribution on classification labels. Then for hard classification you take argmax - e.i class with highest p(c|d').
Kind regards,
Alex
--
You received this message because you are subscribed to the Google Groups "bigartm-users" group.
To unsubscribe from this group and stop receiving emails from it, send an email to bigartm-users+unsubscribe@googlegroups.com.
To post to this group, send email to bigart...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/bigartm-users/aeb0cc12-b84d-4efb-9217-11a4bf803a17%40googlegroups.com.
For more options, visit https://groups.google.com/d/optout.

Мурат Апишев
Jul 4, 2018, 11:57:40 AM7/4/18
to juliaserebr, bigartm-users
Hi!
See this tutorial in docs: http://docs.bigartm.org/en/stable/tutorials/python_userguide/m_artm.html
---
С уважением, Мурат Апишев.
Regards, Murat Apishev.
04.07.2018, 18:13, "juliaserebr" <julia...@gmail.com>:
--
You received this message because you are subscribed to the Google Groups "bigartm-users" group.
To unsubscribe from this group and stop receiving emails from it, send an email to bigartm-user...@googlegroups.com.
juliaserebr
Jul 4, 2018, 12:11:44 PM7/4/18
to bigartm-users
Alex, Murat,
Thank you so much!
Kind regards,
Julia
среда, 4 июля 2018 г., 18:13:33 UTC+3 пользователь juliaserebr написал:
среда, 4 июля 2018 г., 18:13:33 UTC+3 пользователь juliaserebr написал:
Reply all
Reply to author
Forward
0 new messages