Unable to get a html document that i can parse from requests module
23 views
Skip to first unread message

Et
Nov 9, 2022, 4:46:18 PM11/9/22
to beautifulsoup
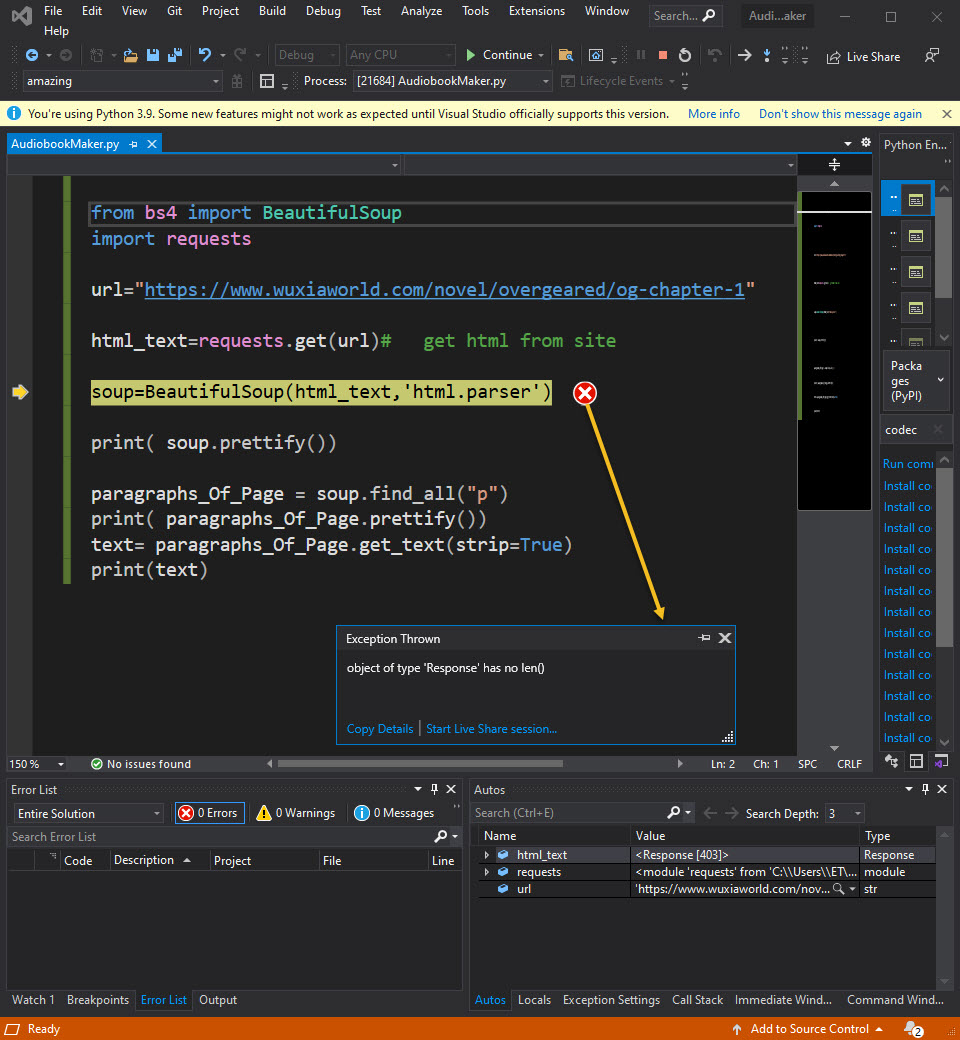
from bs4 import BeautifulSoup
import requests
url="https://www.wuxiaworld.com/novel/overgeared/og-chapter-1"
html_text=requests.get(url)# get html from site
soup=BeautifulSoup(html_text,'html.parser')
import requests
url="https://www.wuxiaworld.com/novel/overgeared/og-chapter-1"
html_text=requests.get(url)# get html from site
soup=BeautifulSoup(html_text,'html.parser')

Jim Tittsler
Nov 10, 2022, 12:49:02 AM11/10/22
to beauti...@googlegroups.com
On Thu, Nov 10, 2022 at 6:46 AM Et <itay...@gmail.com> wrote:>
> html_text=requests.get(url)# get html from site
As the error shown in your IDE suggests, the requests.get() method
> html_text=requests.get(url)# get html from site
returns a Response object that contains several useful fields,
including status_code (which you may want to check for errors/success)
and text (which on success, you can then make soup out of).
https://requests.readthedocs.io/en/latest/api/#requests.Response
Reply all
Reply to author
Forward
0 new messages