Returning Text within deep in HTML
54 views
Skip to first unread message

Aaron Moore
Nov 7, 2022, 5:15:45 AM11/7/22
to beautifulsoup
Hi all,
I am looking to return "Bookmaker Real-Time" in the HTML below. This HTML is the container I plan to iterate over on the webpage. I am having trouble with the title attribute. I greatly appreciate your support.
<div aria-colindex="5" class="ag-header-cell ag-focus-managed" col-id="8" role="columnheader" style="width: 115px; left: 0px;" tabindex="-1" unselectable="on">
<div class="ag-header-cell-resize" ref="eResize" role="presentation">
</div>
<!--AG-CHECKBOX-->
<div class="ag-header-select-all ag-labeled ag-label-align-right ag-checkbox ag-input-field ag-hidden" ref="cbSelectAll" role="presentation">
<div class="ag-input-field-label ag-label ag-hidden ag-checkbox-label" ref="eLabel" role="presentation">
</div>
<div class="ag-wrapper ag-input-wrapper ag-checkbox-input-wrapper" ref="eWrapper" role="presentation">
<input aria-label="Press Space to toggle all rows selection (unchecked)" class="ag-input-field-input ag-checkbox-input" id="ag-22-input" ref="eInput" tabindex="-1" type="checkbox"/>
</div>
</div>
<div class="ag-react-container">
<div class="text-success" style="background-color: rgba(0, 0, 0, 0.2); padding: 6px 6px 6px 14px; border-radius: 6px; display: flex; flex-direction: row; justify-content: space-between; align-items: center; height: 100%; margin-top: 10px; cursor: pointer;">
<div style='background-image: url("https://assets.unabated.com/sportsbooks/logos/bookmaker.svg"); background-repeat: no-repeat; height: 30px; width: 80px; min-width: 80px; background-size: contain; background-position: center center;' title="Bookmaker
Real-Time">
</div>
<div style="display: flex; align-items: center; justify-content: center;">
<i class="border-0 fa fa-circle text-success" style="font-size: 6px; padding: 3px; position: absolute; top: 10px; left: 6px;" title="Real-Time">
</i>
</div>
</div>
</div>
</div>
<div class="ag-header-cell-resize" ref="eResize" role="presentation">
</div>
<!--AG-CHECKBOX-->
<div class="ag-header-select-all ag-labeled ag-label-align-right ag-checkbox ag-input-field ag-hidden" ref="cbSelectAll" role="presentation">
<div class="ag-input-field-label ag-label ag-hidden ag-checkbox-label" ref="eLabel" role="presentation">
</div>
<div class="ag-wrapper ag-input-wrapper ag-checkbox-input-wrapper" ref="eWrapper" role="presentation">
<input aria-label="Press Space to toggle all rows selection (unchecked)" class="ag-input-field-input ag-checkbox-input" id="ag-22-input" ref="eInput" tabindex="-1" type="checkbox"/>
</div>
</div>
<div class="ag-react-container">
<div class="text-success" style="background-color: rgba(0, 0, 0, 0.2); padding: 6px 6px 6px 14px; border-radius: 6px; display: flex; flex-direction: row; justify-content: space-between; align-items: center; height: 100%; margin-top: 10px; cursor: pointer;">
<div style='background-image: url("https://assets.unabated.com/sportsbooks/logos/bookmaker.svg"); background-repeat: no-repeat; height: 30px; width: 80px; min-width: 80px; background-size: contain; background-position: center center;' title="Bookmaker
Real-Time">
</div>
<div style="display: flex; align-items: center; justify-content: center;">
<i class="border-0 fa fa-circle text-success" style="font-size: 6px; padding: 3px; position: absolute; top: 10px; left: 6px;" title="Real-Time">
</i>
</div>
</div>
</div>
</div>
I

Isaac Muse
Nov 7, 2022, 12:22:02 PM11/7/22
to beautifulsoup
When asking questions, it is always best to post what code you’ve already tried so people can help you to understand where you are going wrong as opposed to providing solutions for you.
With that said, titles can be accessed as shown below. All of this and more is mentioned in the docs: https://www.crummy.com/software/BeautifulSoup/bs4/doc/#attributes
from bs4 import BeautifulSoup
HTML = b"""
<html>
<head>
<title>Problem with BeautifulSoup</title>
</head>
<body>
<div title="A title">Content</div>
</body>
</html>
"""
soup = BeautifulSoup(HTML, 'html.parser')
print(soup.select_one('div')["title"])
Aaron Moore
Nov 7, 2022, 8:47:11 PM11/7/22
to beautifulsoup
Understood. Thank you for your helpful insight.
It seems I was reading the html incorrectly & used the wrong container. This is my first html project. This is great library.
Aaron Moore
Nov 10, 2022, 8:50:44 PM11/10/22
to beautifulsoup
Perhaps you can help me to the finish line here.
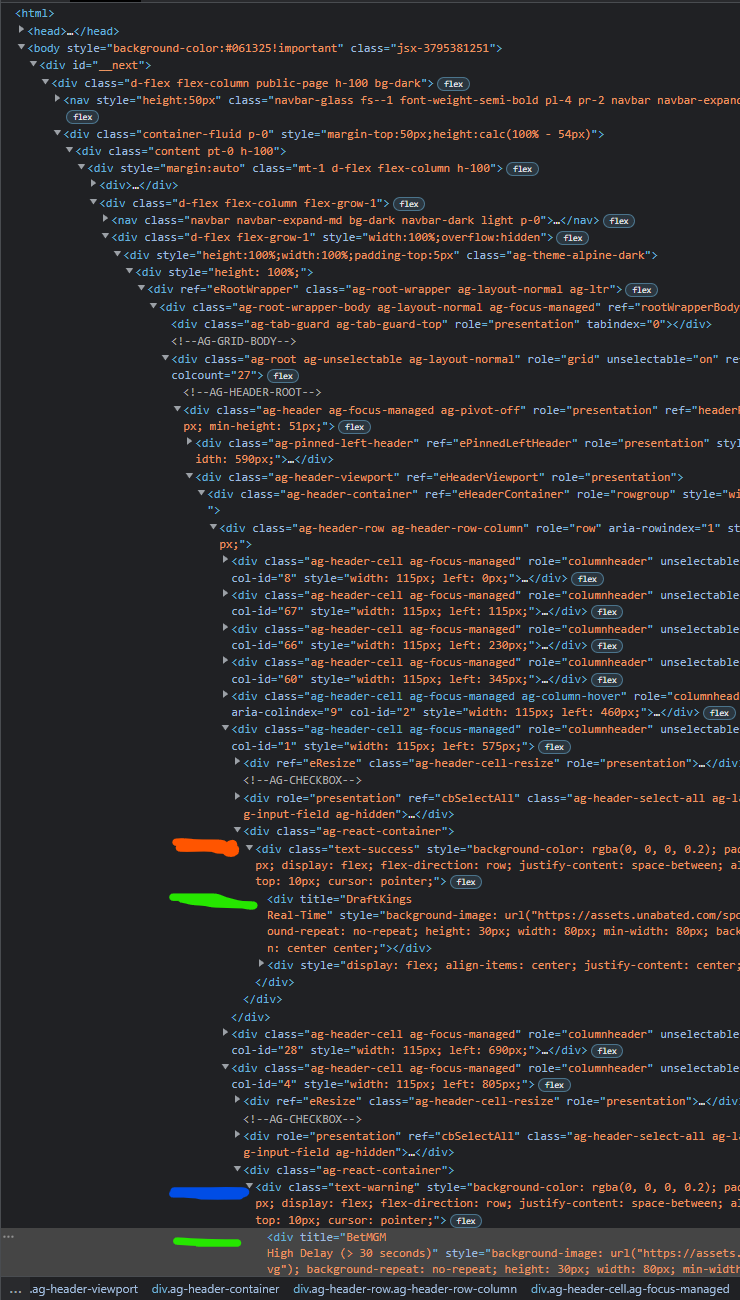
I need to collect a list of titles for the columns of a webpage. I am having trouble reaching each of the title attributes in the code. The green lines indicate the targeted text. The red and blue lines are examples of the class formats which hold the targets. I have had some success with the following:
soup= soup.find_all("div",class_="text-success")
books_list = [ ]
for x in range(len(soup)):
books_list.apppend(soup[x].select_one('div')['title']) #The output does not accurately execute everytime, and it misses the title cards held under different classes. Similar code does not work when applied to the blue line class.
I'm sure I am missing something. Your support is greatly appreciated.
Isaac Muse
Nov 11, 2022, 1:59:54 AM11/11/22
to beautifulsoup
I’m not sure I 100% understand what you are asking, but maybe this helps. My approach is to usually use CSS selectors. I have an obvious bias for using CSS selectors as I am the author of the CSS selector library that Beautiful Soup uses. You can learn more about all the support CSS pseudo-classes etc. by checking out the documentation here.
from bs4 import BeautifulSoup
HTML = """
<div class="text-success">
<div title="Pick me 1"></div>
<div title="not me 1"></div>
</div>
<div class="text-warning">
<div title="Pick me 2"></div>
<div title="not me 2"></div>
</div>
"""
soup = BeautifulSoup(HTML, 'html.parser')
books_list = [el['title'] for el in soup.select("div:is(.text-success, .text-warning) > div:first-child")]
print(books_list)
Output:
['Pick me 1', 'Pick me 2']
Reply all
Reply to author
Forward
0 new messages