Natural language Entity Extraction for HOCR and Webarchive Text extraction preview
59 views
Skip to first unread message

dp...@metro.org
May 28, 2021, 3:42:11 PM5/28/21
to archipelago commons
Hello,
Yes, it is Friday. And yes you may all be tired, weeks are getting longer and zoom calls, too many, coffee is not so strong anymore, sigh*. So I will be brief (as brief is I can) in awareness you may all be already in weekend mode.
Recently we started to implement Natural Language processing (and actually give a concrete use to our NLP64 container) for Full text index and search across Strawberry Flavor (SBF) Solr Documents. If you do not know what those are its also OK: SBFlavors, not to be confused with Strawberry Fields. are special Data Sources and Solr documents that are stored in your Solr index to make possible page by page (or sequence by sequence) HOCR highlight and full text search inside PDFs, Tiff sequences and WACZ files (and more to come). They are generated by Strawberry Runners Post processors that do HOCR or WARC/WACZ HTML text extraction and are not really Drupal Content Entities (do not live in DB) but a different type of Data Source. Why? Because a single Digital Object (ADO) may have attached hundreds of those and its impractical to keep that relationship (many many to one) in DB. (imagine a PDF of a book).
Ok, so where does Natural Language Entity Extraction comes in place here? The HOCR or HTML extraction of a WACZ file gets send now during processing into the Polyglot NLP64 processor to "deduce" which parts of the text are referencing Agents (people and institutions) and which are Places/Locations/sources. During that process we also calculate (WOW!) the sentiment of the text corpus. 1 for super positive, 0 neutral,. negative, well not so positive. And you can facet by a range there too.
This data gets attached now to each Page/HTML/Website extraction and can be used to facet/discover inside a book.
Is this the future of Subject extraction/Robotic metadata professionals? No! Absolutely not a human replacement. NLP as any trained AI/Model base processing is statistically/approximate and many times not accurate! Still, for discovery and context it's a good hint of what exists and allows a good citizen to make connections you could not do by just looking at text. These new "dimensions" are now stored inside Solr for this special Data Source as "who", "when", "where" and also "sentiment" properties that can be faceted, ranged, searched against, etc.
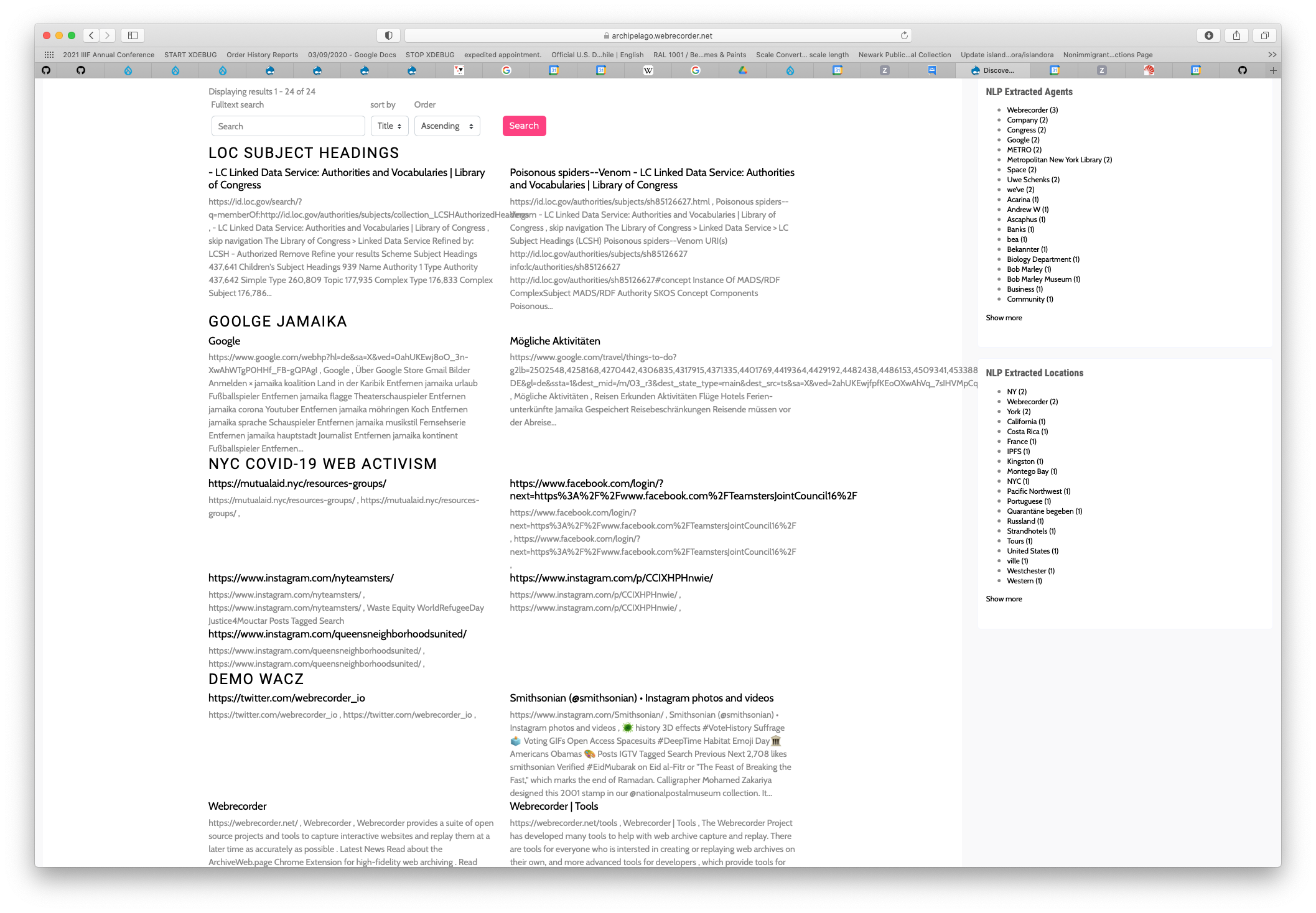
So how does this look like? This is the Webarchive Text Discovery page: You can see how all internal Sites (URLs with Text) are grouped under its holding ADO. On the right The Who and Where dimensions faceted. Full text search is possible and also facet based.
This one is with a search term enabled (Instagram). You can also see how "Emojis!" are preserved too and the found text highlighted + the facets reducing themselves quite a bit.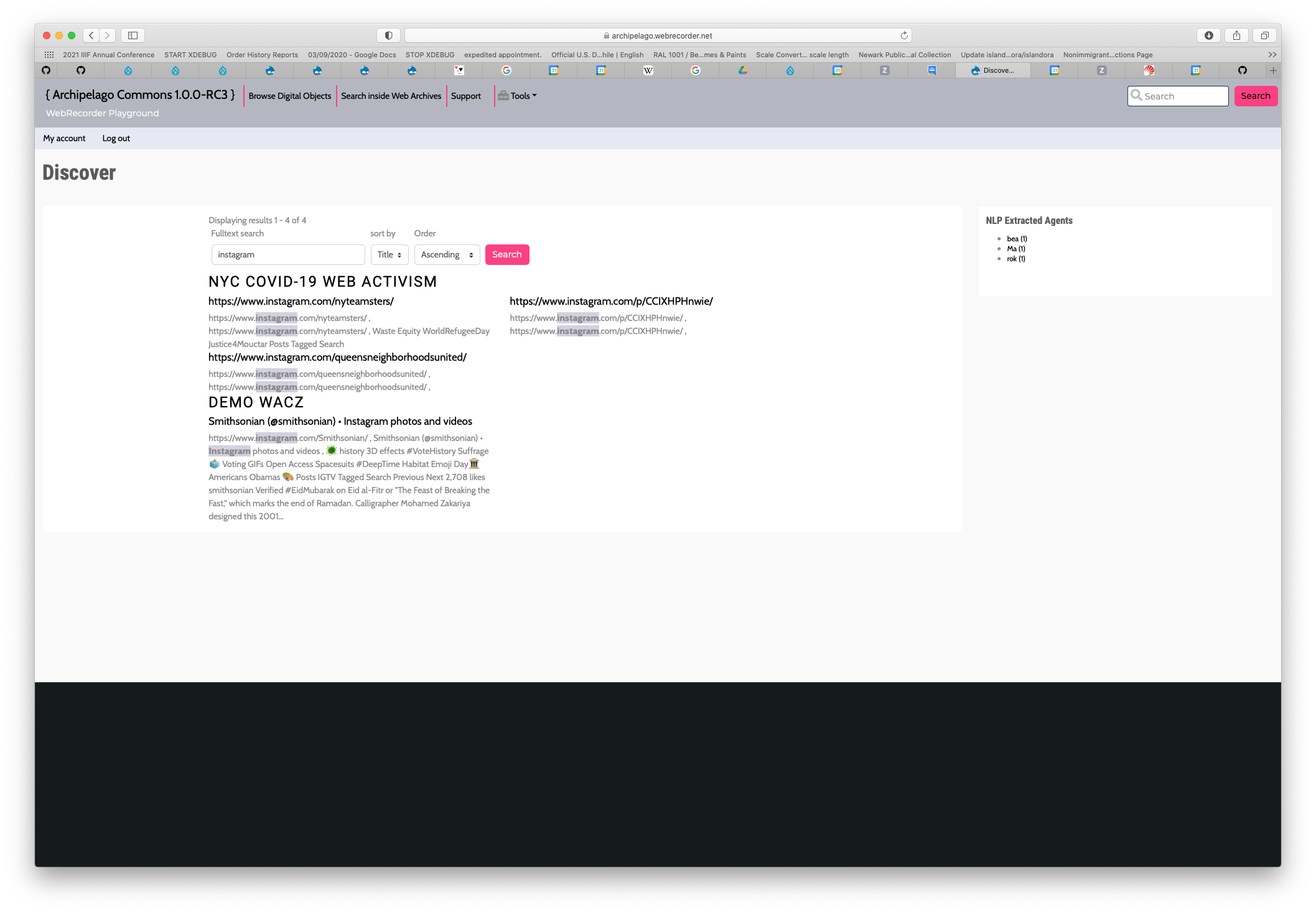
An extra neat feature is that each internal Page (or HOCR, working on the site building for that now) links directly to the actual context, on Books to the page when using the IAbookreader and on WACZ files to the internal Website viewable in the replay.web embedded plugin.
Just wanted to share this with you because we are not aware of any other Repository (you know archipelago is special right?) going this route and its a good conversation starter to discuss to what extend (and shape) Human/curated and highly valuable Metadata should be complemented (and stating so that it does not provide from your expertise but by a service) with NLP or AI based one.
If you can think of other uses please let us know. There are more features behind our NLP64 container (ever tried http://localhostL:6400 in your archipelago? not, do it!) and you can go from "abstract" generation from a large text to Language Detection and Spacy Instead of Polyglot to also get "time" based extractions if that is something you feel is nice (like "last century", years, dates, epochs). Currently we support a few languages but not all is being used like that so will work on making sure your translations are handled correctly coming from either your ADO language or metadata that states your chosen language, but someone (or we all) could also work on more languages support too so we can make this better and fair.
Thanks a lot and have a nice weekend!
PS: this is a RC3 feature so ... sadly (yet) you won't find in the RC2 but will be available to play with in play.archipelago.nyc and archipelago.nyc in the next 2 weeks. OR2021 Workshop (full registration, 100 wonderful people from all other the world!) will keep us from doing too much in the next 15 days but once that is over you will see a lot of more new features appearing in the Archipelago Horizon.
Diego Pino

Nate Hill
May 28, 2021, 5:30:02 PM5/28/21
to dp...@metro.org, archipelago commons
This is awesome, Diego! How would you apply this to digitized newspapers? Seems like a similar opportunity?
--
You received this message because you are subscribed to the Google Groups "archipelago commons" group.
To unsubscribe from this group and stop receiving emails from it, send an email to archipelago-com...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/archipelago-commons/b3d8f6d2-fbe6-47ce-aca0-ae724e0bd170n%40googlegroups.com.
dp...@metro.org
May 30, 2021, 4:37:31 PM5/30/21
to archipelago commons
Hi Nate, thanks. Yes, same as with books or any document that is a sequence. If configured to be HOCRed it will get NLP Entity Extraction
Reply all
Reply to author
Forward
0 new messages