Lessons from real data and actual ingest workflows : an IR scenario / late night tests

Diego Pino
Diego Pino
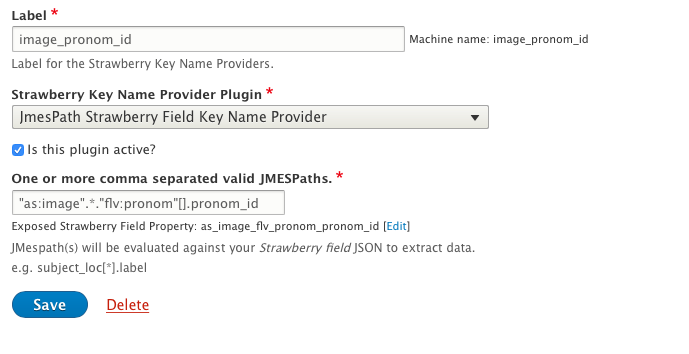
"sequence": 2,
"flv:pronom": {
"label": "JPEG File Interchange Format",
"mimetype": "image\/jpeg",
"pronom_id": "info:pronom\/fmt\/44",
"detection_type": "signature"
},
"dr:mimetype": "image\/jpeg",

cshl.l...@gmail.com
Diego Pino
Drush Commandline Tool 10.1.1
Ok. Enough of context (we can go back to that anytime)
EXAMPLE INGEST (ONE OBJECT, 2 FILES)
Simple examples are shipped in the beta3 release so you want to familiarize yourself with this first. Drush command we added is in the beta3 release so make sure you are actually running webform_strawberryfield, format_strawberryfield and strawberryfield from the 8.x-1.0-beta3 branch and all is updated (recently)
https://github.com/esmero/archipelago-deployment/blob/8.x-1.0-beta3/docs/democontent.md (please read, don't skip)
The gist is that when you follow the instructions there you are cloning inside your d8content folder a repo containing folders, .json files and binary files. and then you call this script i wrote that for every .json file it uses our drush command to in a single step upload files found in a given folder, get the UUIDs, modify the JSON to connect the files to the metadata and upload them
https://github.com/esmero/archipelago-recyclables/blob/edge/deploy_ados.sh
Going deeper there
This is one of the commands called there
drush archipelago:jsonapi-ingest /var/www/html/d8content/archipelago-recyclables/ado/0c2dc01a-7dc2-48a9-b4fd-3f82331ec803.json --uuid=0c2dc01a-7dc2-48a9-b4fd-3f82331ec803 --bundle=digital_object --uri=http://esmero-web --files=/var/www/html/d8content/archipelago-recyclables/ado/0c2dc01a-7dc2-48a9-b4fd-3f82331ec803 --user=jsonapi --password=jsonapi --moderation_state=published;
Let's digest this
drush archipelago:jsonapi-ingest // The command
/var/www/html/d8content/archipelago-recyclables/ado/0c2dc01a-7dc2-48a9-b4fd-3f82331ec803.json // The location inside the docker container (esmero-php) of the json file. That same location from the outside (host computer) is simply the d8content/ folder (do an ls to confirm)
--uuid=0c2dc01a-7dc2-48a9-b4fd-3f82331ec803 // A UUID. I'm passing this to avoid double ingests. If you try to ingest the same object with the same UUID it will not allow you. If you don't you will get twice the same object.
Question: How do i generate a UUID? Good question? So many ways, we are using UUID V4, you can go to an online website (free) or run a drush command.
Try it:
docker exec -ti esmero-php bash -c "drush uuid"
--bundle=digital_object --uri=http://esmero-web // This ones will not change except if you created custom content types or are ingesting collections or have a different name for the docker web container
--files=/var/www/html/d8content/archipelago-recyclables/ado/0c2dc01a-7dc2-48a9-b4fd-3f82331ec803 // The location of a folder with any (for real) type of files you want to attach to the JSON and thus to the Object. Those will be uploaded first by the drush command and then later classified, exif-ied, pronom-ied, checksum-ied and persisted in S3 by strawberryfield. I patched the module recently to allow files with spaces and weird names, if you are running an older version, please use file names without spaces. (please)
--user=jsonapi --password=thepassword // Your default jsonapi pass/credentials API credentials. Secure your JSON API after calling this or protect if behind a firewall, etc.
--moderation_state=published // the moderation state. leave empty to ingest as a draft. If the content model is custom and not moderated then archipelago will just skip this.
So. What is inside one of those JSON files? In other words what you need to ingest your first object via API using ONE row of your CSV? (i will not go into the full CSV here yet, let's start with a single one first)
I will mark in RED for that same file only things that are REALLY required and in green the ones you have in your CSV (means of they are really required/quite recommended and also in your CSV, red wins), please reed the foot note about "ismemberof":
| { | |
| "type": "Panorama", | |
| "label": "Strawberry Field at Thorpes Organic Family Farm", | |
| "owner": "ESIE (Empire State Immersive Experiences)", | |
| "audios": [], | |
| "images": [], | |
| "models": [], | |
| "videos": [], | |
| "warcs": [], | |
| "creator": "Lund, Allison", | |
| "documents": [], | |
| "edm_agent": [], | |
| "ismemberof": null, | |
| "description": "Strawberry field at Thorpes Organic Family Farm in East Aurora, NY. Image depicts late-season strawberry \"u-pick\" fields on a late July evening, 2020.", | |
| "subject_loc": [ | |
| { | |
| "uri": "http:\/\/id.loc.gov\/authorities\/subjects\/sh85128547", | |
| "label": "Strawberries" | |
| }, | |
| { | |
| "uri": "http:\/\/id.loc.gov\/authorities\/subjects\/sh2010104552", | |
| "label": "Organic farming--United States" | |
| } | |
| ], | |
| "website_url": "", | |
| "as:generator": { | |
| "type": "Update", | |
| "actor": { | |
| "url": "https:\/\/play.archipelago.nyc\/form\/descriptive-metadata", | |
| "name": "descriptive_metadata", | |
| "type": "Service" | |
| }, | |
| "endTime": "2020-07-10T14:01:08-04:00", | |
| "summary": "Generator", | |
| "@context": "https:\/\/www.w3.org\/ns\/activitystreams" | |
| }, | |
| "date_published": "2020-07-02", | |
| "term_aat_getty": null, | |
| "ap:entitymapping": { | |
| "entity:file": [ | |
| "images", | |
| "documents", | |
| "audios", | |
| "videos", | |
| "models", | |
| "warcs" | |
| ] | |
| }, | |
| "local_identifier": "", | |
| "subject_wikidata": [ | |
| { | |
| "uri": "http:\/\/www.wikidata.org\/entity\/Q745", | |
| "label": "Fragaria" | |
| }, | |
| { | |
| "uri": "http:\/\/www.wikidata.org\/entity\/Q165647", | |
| "label": "organic agriculture" | |
| } | |
| ], | |
| "geographic_location": { | |
| "lat": "42.755309521944", | |
| "lng": "-78.509831946323", | |
| "city": "Wales Town", | |
| "state": "New York", | |
| "value": "12866, Strykersville Road, Wales Hollow, Wales Town, Erie, New York, 14052, United States of America", | |
| "county": "Erie", | |
| "osm_id": "337075304", | |
| "country": "United States of America", | |
| "category": "place", | |
| "locality": "Wales Hollow", | |
| "osm_type": "way", | |
| "postcode": "14052", | |
| "country_code": "us", | |
| "display_name": "12866, Strykersville Road, Wales Hollow, Wales Town, Erie, New York, 14052, United States of America", | |
| "neighbourhood": "", | |
| "state_district": "" | |
| }, | |
| "strawberry_field_widget_id": "descriptive_metadata" | |
| } |
Gist:
- basically create a valid JSON file (you can use atom, a script, python, php, textmate, Oxygen XML editor, Apple Property editor, etc. all those validate JSON).
You want to have the
- "type" key which triggers different view modes in your archipelago, but if you omit it i "think" all can be also fine (crossing fingers)
- "label" is more than important, its the title of your object. If you omit it archipelago will give you one quite silly one.
- "keywords". You can use the structure used by LoC and omit the URIS if you don't know them. Or the one by WIKIDATA, etc. or even put them as a simple list on some other key, lets name it keywords like this
"keywords": [
"super", "duper","keyword"],
I feel that is one of the MANY beautiful things of archipelago. Put your data where it makes more sense to you, be consistent, modify webforms so they can read from there or experiment with the "Edit content as Raw JSON Metadata" (another tut but really intuitive) and then make sure you make them appear later via the twig templates in your MODS, Dublin core, schema.org, etc. Iterate, refine, move forward. Disclaimer. I KNOW we don't have all the intuitive tools around yet to make this the best ever metadata editing platform. But we will, i'm working hard and we will.
- lastly the audios, images, etc empty keys and the special "ap:entitymapping": { "entity:file": [ structure which includes the same list of audios, images, etc. That is an Archipelagism. Actually, all that is as: or ap: or flv: basically a key that is prefixed is either created by us during ingest or used as a hint for something else. In this case this one is important, why? Archipelago when uploading the files you will provide in your drush command as a folder, will calculate the mime type and will put each file (like a media router) in a key named like the first part of the mimetype (with a little bit of imagination because i do renamed application for document) pluralized. So an image/jp2 will end in images. but that is actually a first pass, then "ap:entitymapping": { "entity:file": structure tells strawberryfield to resolve all those keys as being files (you can add a key named ""entity:node" and it will deal with it as a connection to another d.o) and by doing so will trigger checksum, exif extractions, persistence etc. etc.
Sorry for the long explanation but i feel this is needed. The background behind this all and why things happen. So, next step is:
- Please create a JSON and add a folder with your files inside the docker container (i will also allow external files eventually no worries)
- Try an ingest yourself first. Come back here and let's share what you did/ the JSON.
Once that happened, let's move to what is to come soon (code started, quite advanced already) a full UI driven ingest mechanism, following the popularity of our Islandora Multi Importer. but this one is an important first step. Know your data, love your archipelago (old proverb, from negative unix timestamp times)
Does this help in anyway? Please let me know (other than writing docs for this, starting now) how could i make this easier for you?
Best
Diego
cshl.l...@gmail.com
Just as long as I was able to assign a new UUID, for each ingest, everything went smoothly. I was surprised that the json did not explicitly reference any .jpg/.pdf/.mp4 file, but automatically processes all of the files in the media directory for that UUID. At least for the book, the system sorts the pages by the filename (which is reasonable). Not sure if I have a full video and a trailer, how the json would distinguish between the two .mp4 files.
Diego Pino
Diego Pino
Dear Diego,
Your reply was very useful. I was able to make a copy of d8content, renaming the directory to mycontent, slightly manipulate the json files. I then copied the new mycontent directory to the docker container and started up ingest process, using the following commands:docker cp mycontent esmero-php:/var/www/htmldocker exec -ti esmero-php bash -c 'mycontent/archipelago-recyclables/deploy_ados.sh'
Just as long as I was able to assign a new UUID, for each ingest, everything went smoothly. I was surprised that the json did not explicitly reference any .jpg/.pdf/.mp4 file, but automatically processes all of the files in the media directory for that UUID. At least for the book, the system sorts the pages by the filename (which is reasonable).
Not sure if I have a full video and a trailer, how the json would distinguish between the two .mp4 files.
Before any of the digital objects are uploaded, need to create a hierarchy of Digital Objects Collections, where the ADO are able to be placed. How does one use "ismemberof"? Since I am just running a remote script, I am not getting the collection ID, back from the script. Do I use the UUID for the ADO Collection, in the "ismemberof" field of the item? You referenced a footnote to the "ismemberof" above in your answer which might answer the question, but I have not been able to track that footnote down.
Now for a more interesting question. Let's say I have collections from a number of different Archival systems, that I want all imported into Archipelago.
Let's say the first one is Digitool.
Do I try to recreate all of the Metadata that is in Digitool, and have a digitool-tiff, digitool-pdf, digitool-jpg and a digitool-ead json formats, so that all of the metadata is captured. Then would I have to create twigs templates for each digitool json formats.
I would then also do the same for some collections in Omeka, so there might be a omeka-pdf, omeka-jpg and omeka-jp2k, which have more of a Dublin Core set of metadata. And finally, I would want to upload the structure of some collections contained within ArchivesSpace, so that I can then subsequently upload actual digitized content to Archipelago. So I might also have an archivesspace-element json format.
Should I try to keep the metadata between all of these formats/sources as close to the original as possible using the above approach
, or should I be trying to normalize the metadata into a "native ADO" json, which will work with the original twigs templates. A third approach, might be to OAI-PMH to extract and import the metadata. Any and all insights appreciated.
Thanks
-Tom