Re: [AntConc:3396] QueryPattern for last word before specific Pattern
17 views
Skip to first unread message

Laurence Anthony
Apr 20, 2023, 10:19:05 PM4/20/23
to ant...@googlegroups.com
Hi Yuria,
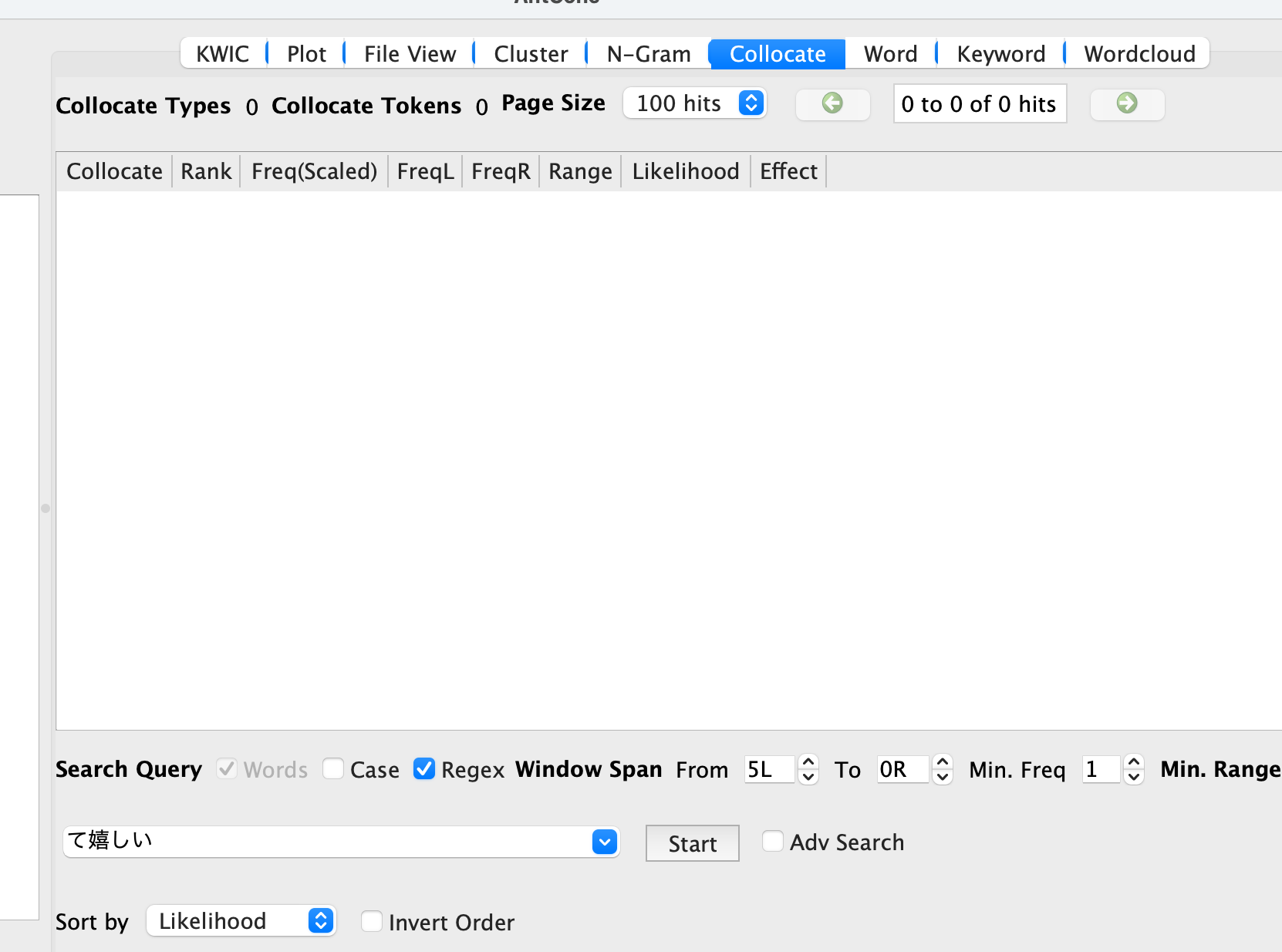
As you seem to have properly segmented your Japanese text (which is the correct thing to do), you can now search for patterns just as you do for English. So, if you want to search for a two-word pattern that ends in て, you can use the Cluster Tool to generate all two word clusters ending in て, and the results should be exactly what you want.
Please try that and let me know if you get the results you want.
I hope this helps!
Laurence.
###############################################################
Laurence ANTHONY, Ph.D.
Professor of Applied Linguistics
Faculty of Science and Engineering
Waseda University
3-4-1 Okubo, Shinjuku-ku, Tokyo 169-8555, Japan
E-mail: antho...@gmail.com
WWW: http://www.laurenceanthony.net/
###############################################################
Laurence ANTHONY, Ph.D.
Professor of Applied Linguistics
Faculty of Science and Engineering
Waseda University
3-4-1 Okubo, Shinjuku-ku, Tokyo 169-8555, Japan
E-mail: antho...@gmail.com
WWW: http://www.laurenceanthony.net/
###############################################################
On Wed, 19 Apr 2023 at 12:59, ユリア <yinn...@gmail.com> wrote:
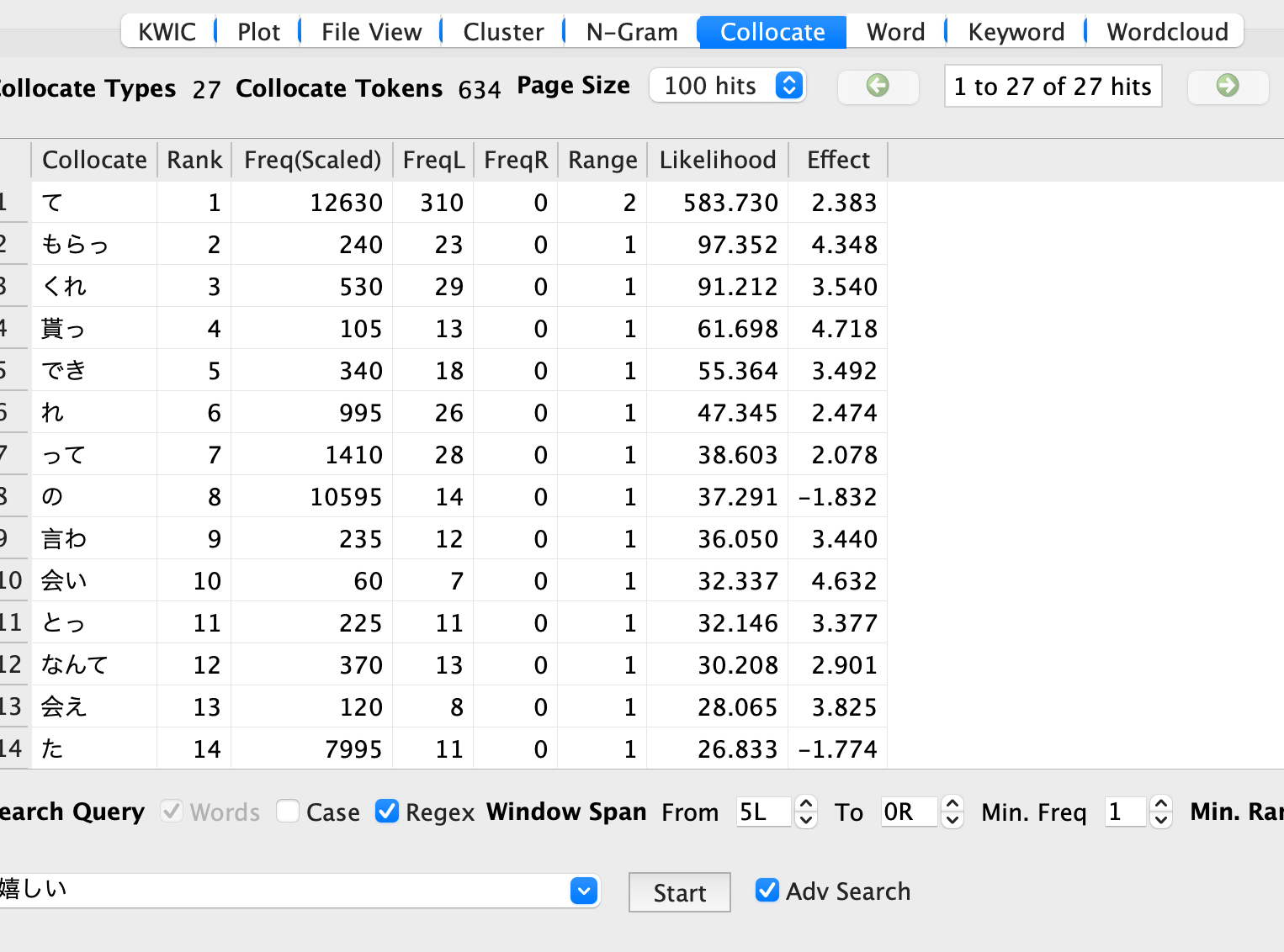
Hello all,I have a corpus that I want to analyze concerning a specific pattern, illustrated as follows:"て嬉しい"the て is usually a connector, connecting the previous word and the adjective 嬉しい.I want to create a frequency word list of the word that is preceded and thus connected by て (e.g. 会えて嬉しい). In this case I would be interested in 会え[て], or its plain form.The corpus does hold complete sentences however, so it would be important it does not regard the complete string before て嬉しい but only the word right before て, which could consist of one or multiple letters.Is there a way to create a query for that?Something that might give me a list similar to this (I don't mind, whether it shows the word including て, without て / the word stem or if it would even show the whole part 会えて嬉しい):Token Count会え(て嬉しい) 25見れ(て嬉しい) 16I tried to query simply like that (although this is not ideal, as it does not really select for words), but if I include て it will not give me results, as I have tagged the corpus with TagAnt in Japanese and I guess I would need to include that somehow in my query.If I just search for 嬉しい and set the span to 5L I will get a list, that could help me somehow, but would require a lot of manual checking.Thank you so much.Best--
You received this message because you are subscribed to the Google Groups "AntConc-Discussion" group.
To unsubscribe from this group and stop receiving emails from it, send an email to antconc+u...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/antconc/017cc460-a2fc-4282-8939-80571080e02an%40googlegroups.com.

ユリア
Apr 26, 2023, 2:31:26 AM4/26/23
to AntConc-Discussion
Thank you very much!
Is it also possible to define multiple OR conditions? as in て OR で AND 嬉しい?
Laurence Anthony
Aug 19, 2023, 2:33:40 AM8/19/23
to AntConc-Discussion
Sorry for the very slow reply. Yes, you can use the || wildcard, which simply means OR.
Laurence.
Reply all
Reply to author
Forward
0 new messages