Very different keyword list results by AntConc 3.5.9 & AntConc 4.2.0
48 views
Skip to first unread message

何燕
Apr 20, 2023, 12:53:12 AM4/20/23
to AntConc-Discussion
Hi professor Laurence, we had two small corpuses of students reflection report, each around 10000 tokens. We wanted to compare the keyword list of the two corpuses, with the 2nd as the target corpus to see which words are used significantly more or less than the first report. While doing this we found the following two problems:
1) We first used AntConc 3.5.9. We used your latest 'antbnc_lemmas_ver_004' to lemmatize both corpuses. It was weird that the lemmas for the reference corpuse was perfectly ok. But when this lemma list was used as reference word list for the target corpus, the target corpus was not lemmatized at all, "be" verbs were all shown seperately, e.g am/is/are and also "me" "my" were also seperated.
2) When we tried to use the latest 4.2.0 version to compare directly the two corpuses to get a keyword, the results were completely different from that generated from version 3.5.9.
We were a bit lost. Thanks very much in advance for any clarification.
Yan

Laurence Anthony
Apr 20, 2023, 10:08:23 PM4/20/23
to ant...@googlegroups.com
Hi Yan,
You seem to be creating a mismatched target and reference corpus.
>But when this lemma list was used as reference word list for the target corpus, the target corpus was not lemmatized at all, "be" verbs were all shown seperately, e.g am/is/are and also "me" "my" were also seperated.
Lemmatizing a reference corpus does not automatically result in a lemmatized target corpus. You need to lemmatize both corpora in exactly the same way to make sure that the results are meaningful. Because the two corpora are out of sync, this would explain why the keyword results are not matching previous results. Instead of trying to apply a lemma list to plain text files, I would suggest you simply tag your target and reference corpus with a tagging tool like my TagAnt tool. Then, you can load both corpora (making sure to choose the "simple_word_tag_headword" indexer, and everything will be aligned and work correctly.
I hope that helps.
Laurence.
###############################################################
Laurence ANTHONY, Ph.D.
Professor of Applied Linguistics
Faculty of Science and Engineering
Waseda University
3-4-1 Okubo, Shinjuku-ku, Tokyo 169-8555, Japan
E-mail: antho...@gmail.com
WWW: http://www.laurenceanthony.net/
###############################################################
Laurence ANTHONY, Ph.D.
Professor of Applied Linguistics
Faculty of Science and Engineering
Waseda University
3-4-1 Okubo, Shinjuku-ku, Tokyo 169-8555, Japan
E-mail: antho...@gmail.com
WWW: http://www.laurenceanthony.net/
###############################################################
--
You received this message because you are subscribed to the Google Groups "AntConc-Discussion" group.
To unsubscribe from this group and stop receiving emails from it, send an email to antconc+u...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/antconc/4da814ed-056b-436e-8584-a5b9a0e68fb6n%40googlegroups.com.
何燕
Apr 25, 2023, 12:17:32 AM4/25/23
to AntConc-Discussion
Thank you so very very much for your reply. I will try it this afternoon and see if it works.
Many thanks again Professor.
Yan
何燕
Apr 25, 2023, 11:41:01 PM4/25/23
to AntConc-Discussion
Dear Professor Laurence,
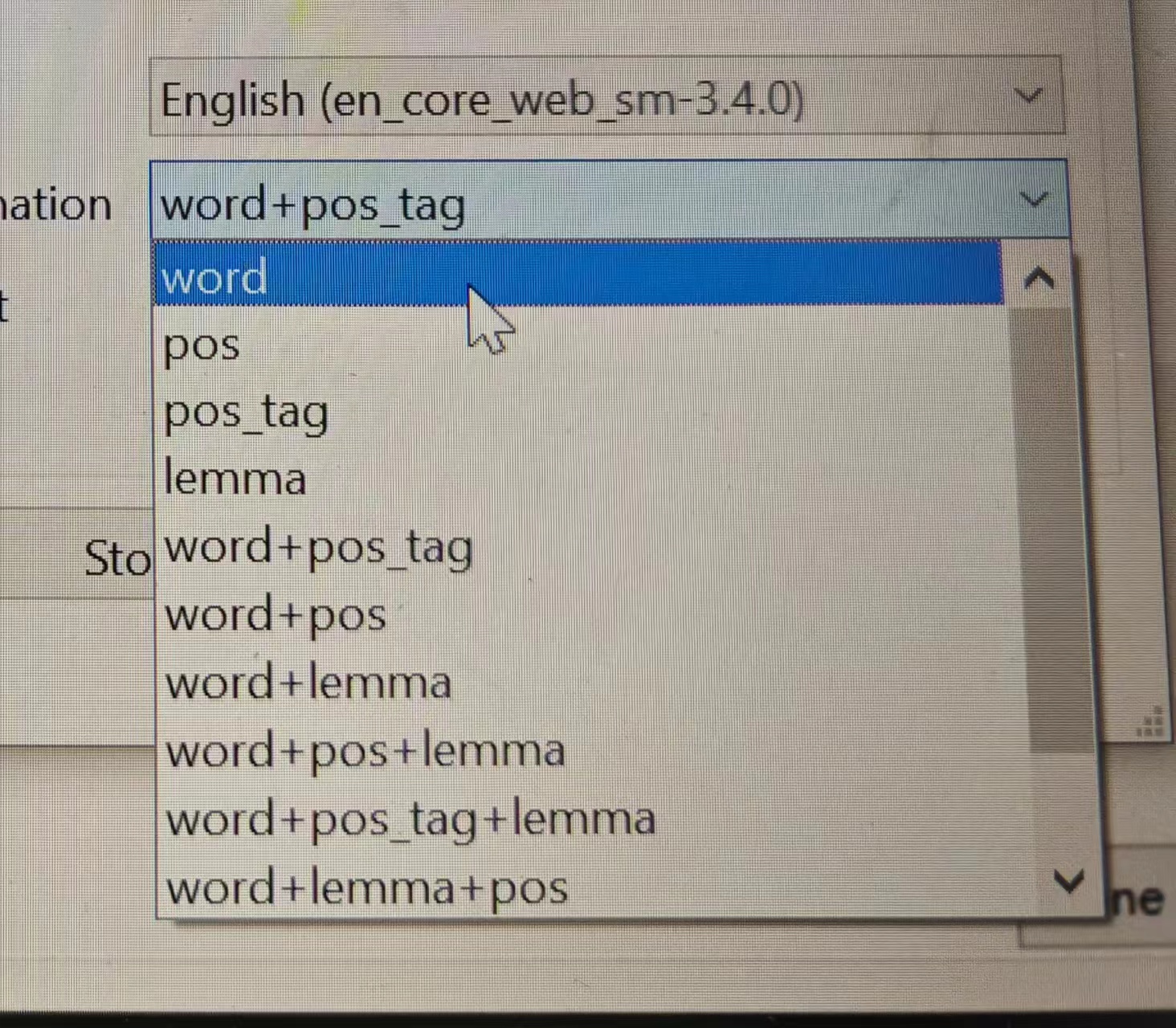
It's me again.
I followed your advice and downloaded TagAnt 2.0.5.
I tagged both the reference and target corpuses. But I didn't find the "simple_word_tag_headword" indexer you mentioned. So I tried first "word" and then "lemma" in the "display information" part as shown in the screen shot below:
After this tagging, I proceeded on with AntConc 3.5.9 and use the 'antbnc_lemmas_ver_004' as reference to lemmatize both the tagged corpuses and aim to generate a key wordlist.
The results I got when tagging "word" is still the same as before, meaning not showing the lemmatized results with "me/my" and "is/are" still shown seperately.
The results when tagging "lemma" is different, for example, there is only "my" in the results and not "I/me" any more. Does this mean I have succeeded? And that "my" is the word that has a higher frequency than "I or me"?
Many thanks again for the help in advance.
PS. I found out yesterday that you're coming to Xian, China for the Advances in Corpus-based Interdisciplinary Research and are the first keynote speaker! Welcome to China in advance and I am actually working on this paper and hopefully my abstract would be accepted and if so, I could be honored to listen to your talk and get some inspiration about corpus-based second language research!
Yan
在2023年4月21日星期五 UTC+8 10:08:23<Laurence Anthony> 写道:
Reply all
Reply to author
Forward
0 new messages