German National Library launched its “cataloguing machine”

Claudia Grote
In April 2022, the German National Library (DNB) put a new system for automatic subject cataloguing into operation. The so-called "cataloguing machine" is used to automatically allocate search entries initially for German-language e-books, electronic journal articles and printed university theses. In addition to intellectual cataloguing, automatic subject cataloguing has been practice in the DNB for many years[1]. This enables structured access to the library holdings, in particular to make it possible to search for and find the continuously growing number[2] of digital publications by topic.
A new automatic-cataloguing system was set up during an internal project called "cataloguing machine" (in German, „Erschließungsmaschine“, EMa for short), carried out from April 2019 to March 2022. Based on the experience with the processes for automatic subject cataloguing that have been in use since 2012[3], the aim of the project was to evaluate current technologies and new processes and make them applicable for the DNB. A modular and flexibly adaptable system architecture was designed to support new usage scenarios in the future. This goes hand in hand with the continuous improvement of the results and better maintainability of the automatic-subject-cataloguing system.
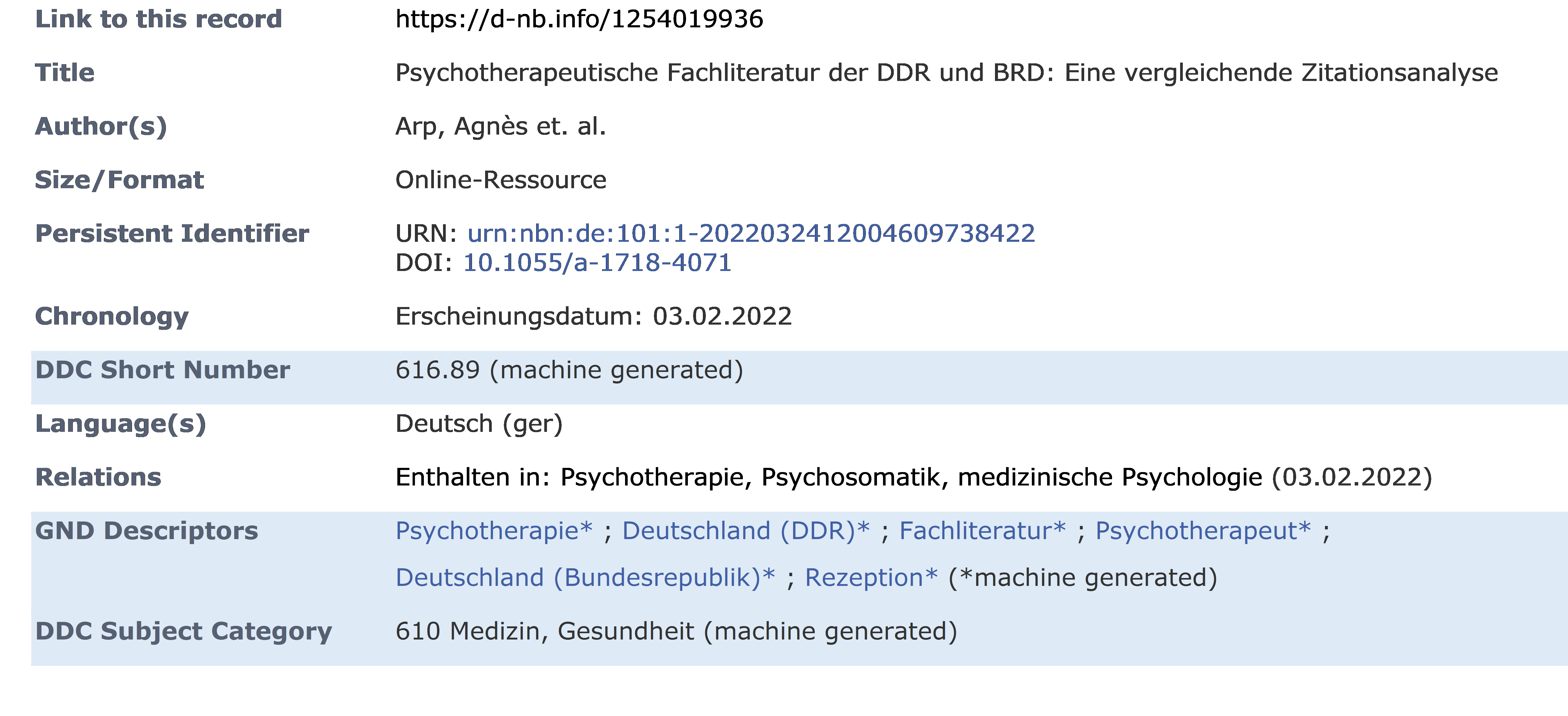
With the new system, DDC subject categories[4], descriptors from the common authority file (GND)[5] for German-language publications and DDC short numbers[6] of medicine (for German and English-language publications) are currently assigned.
Example of a bibliographic record with automatically assigned DDC short numbers, GND descriptors and DDC subject categories, https://d-nb.info/1254019936
The cataloguing machine is operated by the DNB and has a modular architecture that integrates all functional components as services.
At its core is Annif[7]: Omikuji is used for the models of the DDC subject categories and the DDC short numbers. For automatic indexing with GND, we use an ensemble of MLLM and Omikuji. In this ensemble, from a set of approx. 1.3 million GND descriptors - selected subject terms, geographical information, people, works, congresses or corporations - can be automatically assigned.
In addition, the following services developed in the project run in the productive environment: A service for providing text (1) fetches the textual representation of a digital media work that had arrived in the DNB the day before from the text storage as well as the associated metadata from the catalogue system. A service for text language recognition (2) assigns the text language, a service for classification & indexing for communication with Annif (3) transfers German or English texts and metadata to Annif (4) and receives the results of the automatic processing back from Annif. A cataloguing service (5) converts the results into the format of the catalogue system (Pica+ format), and the EMa control (6) writes them to the bibliographic record of the digital publications in the catalogue system, making them immediately available for retrieval. The process flow is initialised, controlled and monitored via the EMa control.
Schematic representation of the automatic-cataloguing system
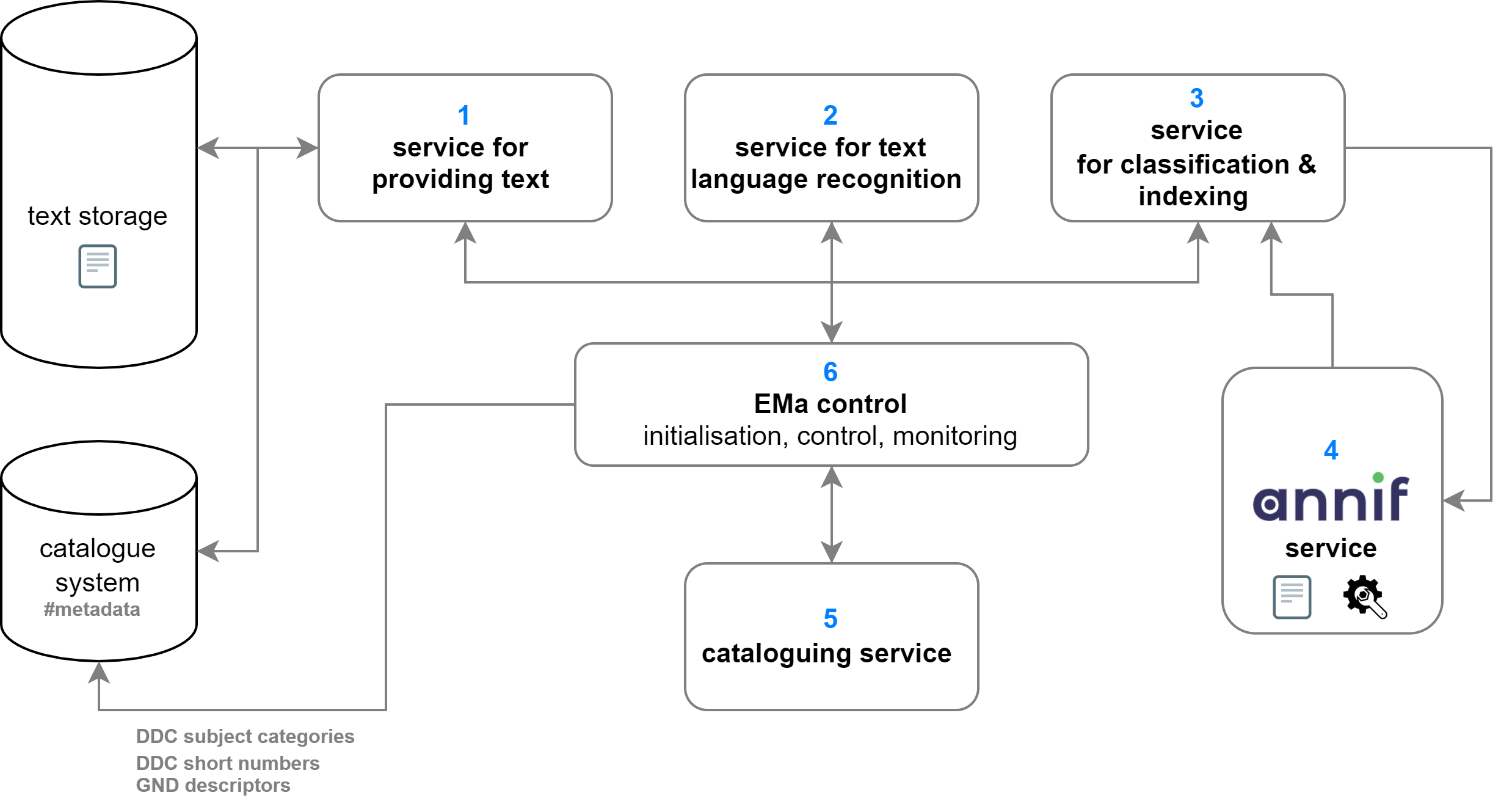
With the implementation of the individual new processes as services, further functionalities and processes can also be flexibly combined, exchanged and supplemented in the future. The constant and active participation in the discourse and the current developments in the field of artificial intelligence[8] form an essential basis for enabling the continuous improvement of the automatic-subject-cataloguing results for the DNB collections.
[1] Junger, Ulrike; Scholze, Frank: Neue Wege und Qualitäten – Die Inhaltserschließungspolitik der Deutschen Nationalbibliothek. In: Qualität in der Inhaltserschließung, herausgegeben von Michael Franke-Maier, Anna Kasprzik, Andreas Ledl und Hans Schürmann, Berlin, Boston: De Gruyter Saur, 2021, S. 55-70. https://doi.org/10.1515/9783110691597-004
[2] In 2021 alone, almost 2.3 million media works were added to the collection, of which around 797,000 are printed publications (monographs, journals/newspapers or university theses) and around 1,363,000 are digital publications (monographs, e-papers or electronic journal articles). The amount of access is at the level of previous years. The total stock has grown to around 43.6 million media works.
[3] Mödden, Elisabeth; Schöning-Walter, Christa; Uhlmann, Sandro: Maschinelle Inhaltserschließung in der Deutschen Nationalbibliothek. In: BuB : Forum Buch und Bibliothek. – 70 (2018), 1, S. 30-35. https://nbn-resolving.org/urn:nbn:de:0290-opus4-160844
[7] https://annif.org, and Suominen, Osma; Inkinen, Juho; Lehtinen, Mona: Annif and Finto AI: Developing and Implementing Automated Subject Indexing. JLIS.It, 13(1), 265–282. https://doi.org/10.4403/jlis.it-12740
[8] The DNB also started a research project on this in 2021, funded by the Federal Government Commissioner for Culture and the Media as part of the Federal Government's artificial intelligence strategy: "Automatic cataloguing system - subject cataloguing with AI methods"
https://www.dnb.de/EN/Professionell/ProjekteKooperationen/Projekte/KI/ki_node.html

Osma Suominen
warm congratulations for launching the new Cataloguing Machine! It's a
great honour for our team that you've chosen Annif as the core of the
new system.
I had already seen the German language blog announcement [1] but I noted
that this new post adds some more details about the algorithms you use
(Omikuji and MLLM).
Best,
Osma
[1] https://blog.dnb.de/erschliessungsmaschine-gestartet/
Claudia Grote kirjoitti 11.5.2022 klo 16.39:
> Dear all,
>
> In April 2022, the German National Library (DNB) put a new system for
> automatic subject cataloguing into operation. The so-called "cataloguing
> machine" is used to automatically allocate search entries initially for
> German-language e-books, electronic journal articles and printed
> university theses. In addition to intellectual cataloguing, automatic
> subject cataloguing has been practice in the DNB for many years[1]
> A new automatic-cataloguing system was set up during an internal project
> called "cataloguing machine" (in German, „Erschließungsmaschine“, EMa
> for short), carried out from April 2019 to March 2022. Based on the
> experience with the processes for automatic subject cataloguing that
> for the DNB. A modular and flexibly adaptable system architecture was
> designed to support new usage scenarios in the future. This goes hand in
> hand with the continuous improvement of the results and better
> maintainability of the automatic-subject-cataloguing system.
>
> from the common authority file (GND)[5] <#_ftn5> for German-language
> publications and DDC short numbers[6] <#_ftn6> of medicine (for German
>
>
>
> Example of a bibliographic record with automatically assigned DDC short
> numbers, GND descriptors and DDC subject categories,
>
> _
> _
>
> __
> Example_IDN1254019936.png
>
>
> The cataloguing machine is operated by the DNB and has a modular
> architecture that integrates all functional components as services.
>
> with GND, we use an ensemble of MLLM and Omikuji. In this ensemble, from
> a set of approx. 1.3 million GND descriptors - selected subject terms,
> geographical information, people, works, congresses or corporations -
> can be automatically assigned.
>
> In addition, the following services developed in the project run in the
> productive environment: A service for providing text (1) fetches the
> textual representation of a digital media work that had arrived in the
> DNB the day before from the text storage as well as the associated
> metadata from the catalogue system. A service for text language
> recognition (2) assigns the text language, a service for classification
> & indexing for communication with Annif (3) transfers German or English
> texts and metadata to Annif (4) and receives the results of the
> automatic processing back from Annif. A cataloguing service (5) converts
> the results into the format of the catalogue system (Pica+ format), and
> the EMa control (6) writes them to the bibliographic record of the
> digital publications in the catalogue system, making them immediately
> available for retrieval. The process flow is initialised, controlled and
> monitored via the EMa control.
>
> Schematic representation of the automatic-cataloguing system
>
>
>
>
>
>
>
> With the implementation of the individual new processes as services,
> further functionalities and processes can also be flexibly combined,
> exchanged and supplemented in the future. The constant and active
> participation in the discourse and the current developments in the field
> results for the DNB collections.
>
>
>
> Cheers,
> The EMa team -
> Frank, Claudia, Jan-Helge, Matthias, Christoph, Sandro, Kirsten, Nico
>
>
> [1] <#_ftnref1> Junger, Ulrike; Scholze, Frank: Neue Wege und Qualitäten
> Qualität in der Inhaltserschließung, herausgegeben von Michael
> Franke-Maier, Anna Kasprzik, Andreas Ledl und Hans Schürmann, Berlin,
> Boston: De Gruyter Saur, 2021, S. 55-70.
> https://doi.org/10.1515/9783110691597-004
>
> [2] <#_ftnref2> In 2021 alone, almost 2.3 million media works were added
> (monographs, journals/newspapers or university theses) and around
> 1,363,000 are digital publications (monographs, e-papers or electronic
> journal articles). The amount of access is at the level of previous
> years. The total stock has grown to around 43.6 million media works.
>
> Nationalbibliothek. In: BuB : Forum Buch und Bibliothek. – 70 (2018), 1,
> S. 30-35. https://nbn-resolving.org/urn:nbn:de:0290-opus4-160844
> <https://nbn-resolving.org/urn:nbn:de:0290-opus4-160844>
>
> https://www.dnb.de/EN/Professionell/DDC-Deutsch/DDCinDNB/ddcindnb_node.html#doc266074bodyText1
> <https://www.dnb.de/EN/Professionell/DDC-Deutsch/DDCinDNB/ddcindnb_node.html#doc266074bodyText1>
>
> [5] <#_ftnref5>
> https://www.dnb.de/EN/Professionell/Standardisierung/GND/gnd_node.html
> <https://www.dnb.de/EN/Professionell/Standardisierung/GND/gnd_node.html>
>
> [6] <#_ftnref6>
> https://www.dnb.de/EN/Professionell/DDC-Deutsch/DDCinDNB/ddcindnb_node.html#doc266074bodyText3
> <https://www.dnb.de/EN/Professionell/DDC-Deutsch/DDCinDNB/ddcindnb_node.html#doc266074bodyText3>
>
> [7] <#_ftnref7> https://annif.org <https://annif.org>, and Suominen,
> Implementing Automated Subject Indexing. JLIS.It, 13(1), 265–282.
> https://
> <https://doi.org/10.4403/jlis.it-12740>
>
> [8] <#_ftnref8> The DNB also started a research project on this in 2021, funded by the
> Federal Government's artificial intelligence strategy: "Automatic
> cataloguing system - subject cataloguing with AI methods"
>
> https://www.dnb.de/EN/Professionell/ProjekteKooperationen/Projekte/KI/ki_node.html
>
>
>
> <https://www.dnb.de/EN/Professionell/DDC-Deutsch/DDCinDNB/ddcindnb_node.html#doc266074bodyText3>
>
> --
> You received this message because you are subscribed to the Google
> Groups "Annif Users" group.
> To unsubscribe from this group and stop receiving emails from it, send
> an email to annif-users...@googlegroups.com
> <mailto:annif-users...@googlegroups.com>.
> To view this discussion on the web visit
> https://groups.google.com/d/msgid/annif-users/CADt3EcwEcpzafGhghmX9Pz%3D%2Bs-KTWDmCD%3DN%3D3VKPr38HQrCNmQ%40mail.gmail.com
> <https://groups.google.com/d/msgid/annif-users/CADt3EcwEcpzafGhghmX9Pz%3D%2Bs-KTWDmCD%3DN%3D3VKPr38HQrCNmQ%40mail.gmail.com?utm_medium=email&utm_source=footer>.
--
Osma Suominen
D.Sc. (Tech), Information Systems Specialist
National Library of Finland
P.O. Box 15 (Unioninkatu 36)
00014 HELSINGIN YLIOPISTO
Tel. +358 50 3199529
osma.s...@helsinki.fi
http://www.nationallibrary.fi