Re: Very long suggest time with MLLM in some cases

Osma Suominen
Thank you for your observations and detailed investigation. It's indeed
strange that a single document can take so much more time to process
than normal.
Since you are using GND, an extremely large vocabulary (1.4M subjects
IIRC), my first suspicion is that this could be related to that. The way
MLLM works is that internally, it will first try to match words in the
text to terms in the vocabulary; then it will rank those matches using a
machine learning classifier and return only the top K ones (typically
10). It is possible that this document happens to produce a very large
number of GND matches; that would explain why it takes so long to process.
I looked at the document and there were a couple of features that stood
out - there was some mathematical notation with terms like "dx". Also
the acronym "CAS" was used a lot. Either of these might match a large
number of GND concepts; typically short words produce more matches than
long ones, as they can have different meanings.
To find out more, let me propose a couple of tests that you could try:
1. Try to make Annif/MLLM produce as many suggestions as possible for
this document. Set the "limit" parameter to a large number such as 1000
or more in projects.cfg (you don't have to retrain), and run the suggest
command (or corresponding REST API call) with a similarly high limit
parameter (e.g. "annif suggest --limit 1000 gnd-mllm-de-0.54-2
<1155862600.txt"). Examine the list of suggestions - do you get a lot of
them? Is there some repeating pattern?
2. Split the document into smaller parts, for example first in half,
then each half in two etc. Avoid breaking up sentences if possible. Try
to identify the piece of the document that is slow to process. Is there
a specific sentence or section that is slow? What suggestions do you get
for that part (again increasing the limit)?
Trying these could give more clarity, for example revealing if this is
primarily a data issue (e.g. many similar terms in GND) or a problem
within the MLLM algorithm - or it could be a combination of both.
Best,
Osma
Christoph Poley kirjoitti 17.1.2022 klo 18.00:
> Hallo Osma,
>
> I hope you and your team are having a healthy and happy new year.
>
> Regarding our annif installation we are going to build our productive
> stages using docker-compose and Portainer.io . One part of our bucket
> list are mass functionality tests. There we found a curious behaviour in
> MLLM. Nearly everything works fine, but we have some statistical
> outliers according to the time we need to suggest GND descriptors.
>
> At first, when we work through a batch we get results like that:
> [INFO ] 2022/01/14 14:54:58: 1190022184
> [INFO ] 2022/01/14 14:55:00: 1167161270
> [INFO ] 2022/01/14 14:55:01: 1161299009
> [INFO ] 2022/01/14 14:55:01: 1181178142
> [INFO ] 2022/01/14 14:55:03: 115995903X
> [INFO ] 2022/01/14 14:55:04: 375 datasets done!
> [INFO ] 2022/01/14 14:55:04: 1155862600
> [INFO ] 2022/01/14 14:57:35: 116301527X
> [INFO ] 2022/01/14 14:57:36: 1156833876
> [INFO ] 2022/01/14 14:57:37: 1161313680
> [INFO ] 2022/01/14 14:57:38: 1158635109
>
> Please have a look at the dataset: 1155862600 . Here we need a very long
> time to suggest our GND descriptors. Normally MLLM needs 1-3 seconds.
> Note that all documents in the test set have the same text length and
> contain 30,000 characters.
>
> Furthermore I did a little research to pick out the suspicious component
> of our installation and to prove our surrounding environment.
>
> I did 2 annif console tests:
>
> (annif.0_55_0) christoph@evalema0:~$ date; time annif suggest
> gnd-mllm-de-0.54-2 < 1173851534.txt; date
> Fr 14. Jan 14:06:31 CET 2022
> <http://d-nb.info/gnd/040528235> Schmerz 0.07974059134721756
> <http://d-nb.info/gnd/04026453X> Ich 0.031183071434497833
> <http://d-nb.info/gnd/040348318> Leben 0.029522238299250603
> <http://d-nb.info/gnd/040305503> Kind 0.02435591258108616
> <http://d-nb.info/gnd/040145166> Eltern 0.024058617651462555
> <http://d-nb.info/gnd/040327868> Krankenhaus 0.023913905024528503
> <http://d-nb.info/gnd/041218183> Unterbewusstsein
> 0.02158760465681553
> <http://d-nb.info/gnd/04113379X> Ehekonflikt 0.018532557412981987
> <http://d-nb.info/gnd/040349330> Leber 0.017362546175718307
> <http://d-nb.info/gnd/040216624> Gott 0.01605933904647827
>
> real 5m19,540s
> user 5m9,665s
> sys 0m9,104s
>
> In one more test we need approximately two minutes more:
>
> (annif.0_55_0) christoph@evalema0:~$ date; time annif suggest
> gnd-mllm-de-0.54-2 < 1155862600.txt; date
> Fr 14. Jan 14:12:56 CET 2022
> <http://d-nb.info/gnd/040379493> Mathematikunterricht
> 0.5090849995613098
> <http://d-nb.info/gnd/041231767> Fachdidaktik 0.34427228569984436
> <http://d-nb.info/gnd/944368581> Galliumnitrid 0.16114728152751923
> <http://d-nb.info/gnd/040011569> Algebra 0.13362091779708862
> <http://d-nb.info/gnd/041535200> Fächerübergreifender Unterricht
> 0.09257388114929199
> <http://d-nb.info/gnd/964789736> Computerassistierte Chirurgie
> 0.08844500035047531
> <http://d-nb.info/gnd/040763587> Problemlösen 0.08220452815294266
> <http://d-nb.info/gnd/040379442> Mathematik 0.059969693422317505
> <http://d-nb.info/gnd/041645219> Kohlenmonoxid 0.05897841602563858
> <http://d-nb.info/gnd/041470524> Butadien 0.05897841602563858
>
> real 7m6,132s
> user 6m59,784s
> sys 0m9,390s
> Fr 14. Jan 14:20:02 CET 2022
>
> This is nearly the same extra time that we need in our batch run. We
> conclude, that there may be an error in the MLLM algorithm or the
> pre-processing pipeline. So we need some support from you.
>
> In the attachment you find the input texts of our two examples. Let me
> know when you need the corresponding model and vocabulary for further tests.
>
> Regards,
> Christoph
>
> *** Suchen. Finden. Entdecken. Deutsche Nationalbibliothek ***
>
> Christoph Poley
> Deutsche Nationalbibliothek
> Automatische Erschließungsverfahren, Netzpublikationen
> Deutscher Platz 1
> D-04103 Leipzig
> Telefon: +49-341-2271-427
> mailto:c.p...@dnb.de
> http://www.dnb.de
>
>
> --
> You received this message because you are subscribed to the Google
> Groups "Annif Users" group.
> To unsubscribe from this group and stop receiving emails from it, send
> an email to annif-users...@googlegroups.com
> <mailto:annif-users...@googlegroups.com>.
> To view this discussion on the web visit
> https://groups.google.com/d/msgid/annif-users/fcc8100f-058c-4802-8adc-47467c7b4d0fn%40googlegroups.com
> <https://groups.google.com/d/msgid/annif-users/fcc8100f-058c-4802-8adc-47467c7b4d0fn%40googlegroups.com?utm_medium=email&utm_source=footer>.
--
Osma Suominen
D.Sc. (Tech), Information Systems Specialist
National Library of Finland
P.O. Box 15 (Unioninkatu 36)
00014 HELSINGIN YLIOPISTO
Tel. +358 50 3199529
osma.s...@helsinki.fi
http://www.nationallibrary.fi

Christoph Poley
Hi Osma, hi all,
in January, we provided a brief report on the processing time of MLLM. We found out, that in some cases MLLM backend of Annif needs a very long time to suggest GND terms. In your answer you gave us some homework, and we did some investigations to find out ideas for solutions how to get a better performance.
1. Analysis of MLLM suggestions
We tried to find out what happens when MLLM produces as many GND descriptors as possible for the document with the very long processing time (limit=100000): MLLM suggested 5,029 GND descriptors (see file res_1155862600.txt).
_Are there repeating patterns?_
Yes, there are very many.
Examples
MLLM suggested GND descriptors:
Bernhard (2. H. 15. Jh.)
Bernhard, B. (20./21. Jh.)
Bernhard,
Ferdinand (1873-1968)
Bernhard,
Johann Adam (1688-1771)
Bernhard,
Lucian (1883-1972)
Bernhard,
Maria Ludwika (1908-1998)
Bernhard,
Oskar (1861-1939)
- The text
contains "Bernhard Kutzler" three times, but no other Bernhards
appears. Therefore, it is obvious that all Bernhards are found on the basis of
these three text passages "Bernhard Kutzler".
Blum,
Carl (1786-1844)
Blum,
Erhard
Blum,
Harry (1944-2000)
Blum,
Joachim Christian (1739-1790)
Blum,
Thierry (20./21, Jh.)
Blum, Ulrich
Blum, Walter (1937-2013)
Blume, Bernhard (1937-2011)
Blume, Gernot
Blume, Heinrich (1788-1856)
Blume, Helmut (1920-2008)
Blumer,
Johann Jakob (1819-1875)
Blumer-Ris,
Hans (1855-1916)
Blūms, Elmārs
- "Blum" appears five times in the text, each time as a citation "Leiß & Blum 2008". A GND descriptor (Blum, Erhard) has the alternative label Blum, E. and could possibly also be found due to this synonym.
Braun
Braun Aktiengesellschaft
Braun von Fernwald, Carl (1822-1891)
Braun, Adam (1748-1827)
Braun, Adolf (1862-1929)
Braun, Alexander (1805-1877)
Braun, Alexander Karl Hermann (1807-1868)
Braun, Andrzej (1923-2008)
Braun, Christina von
Braun, Edmund Wilhelm (1870-1957)
Braun, Ferdinand (1850-1918)
Braun, Friedrich Eberhard (1774-1848)
Braun, Georg Christian (1785-1834)
Braun, Günter (1928-2008)
Braun, Heinrich (1862-1934)
Braun, Herbert (1903-1991)
Braun, Heribert (1921-2005)
Braun, Hermann (1862-1908)
Braun, Jean Daniel (1728-1740)
Braun, Johann W. J. (1801-1863)
Braun, Johanna (1929-2008)
Braun, Karl Friedrich Wilhelm (1800-1864)
Braun, Karl Guido (1841-1909)
Braun, Karlheinz
Braun, M. (1772-1844)
Braun, Otto (1900-1974)
Braun, P. (19. Jh./20. Jh.)
Braun, Placidus (1756-1829)
Braun, Theodor (1833-1911)
Braun, Wilhelm von (1813-1860)
Braunfels,
Walter (1882-1954)
Brauns,
Josef
- The text contains once (!) Braun. Further candidates with this word stem do not exist. There are many more examples.
Many more examples can be seen in the file res_1155862600.txt (and the comparison with the text in document 1155862600.txt).
However, it can also be noted that other result files whose processing time is in the "normal" range between 1 - 3 seconds also contain a similarly high number of GND descriptors that have the same word stem. See for example the files res_1190087464.txt or res_1173699678.txt. The presence of a large number of matching candidates _on the terminology side_ does not necessarily slow down the processing time, since none of these documents has a processing time as long as 1155862600.txt.
The many short words (keywords: formulas or abbreviations like "dx" or acronyms like "CAS") are obviously another cause for the long processing time, as you have already suspected: They (obviously) lead to a much higher number of candidates for matching _on the text side_. In an experiment we left out all short words up to 3 characters - the processing time reduced down to 9 seconds.
Both together (many candidates on the text side plus many candidates on the terminology side) possibly lead to the high amount of GND candidates for the relevance list of the best.
2. Identification of the piece of the document that is slow to process
Concerning your second proposed test: We did as you suggested and repeatedly splitted the text in half, compared the processing speed for both halves and went on splitting always the half with longer processing time. Indeed, the part with the math expressions was the most problematic one concerning processing time.
We constructed a text containing the same number of characters, i.e. 30000, by doubling the first half of the original text, and MLLM processing took 50% longer than with the original text. The doubled second half of the original text took only 45% of the time for the original text, but nonetheless longer than expected.
We also replicated the most problematic 1875 characters up to 30000, and this text took more than twice as long with MLLM as the original text.
The problematic words contain indeed the variable names of the math expressions (cp. 1155862600_AABA.txt). And the found subjects denote in part wrong chemical substances, besides correct mathematical expressions.
3. Further investigations
In another experiment, we completely removed all short terms up to 3 characters from the text and saw a remarkably better performance.
We also found out, that we can speed up MLLM, when we delete the dots in the underlying text. In our example this manipulation reduced the processing time from 100 seconds to 14 seconds.
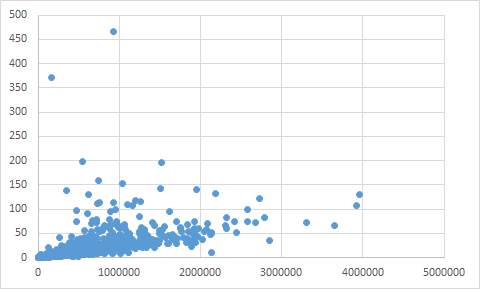
Last but not least we did some mass experiments with another text corpus to get more information about the expected processing time. Each of the texts has a length of approx. 80000 characters. For 80 to 90 percent of the suggestions MLLM needs not more than 7 seconds - fig 1.
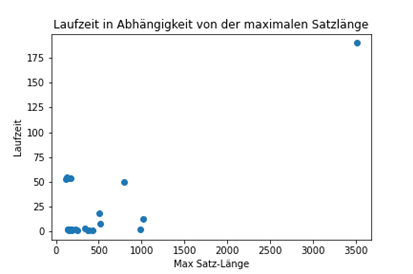
We assume, that the needed processing time depends on the length of the given text string with a couple of exceptions - fig 2.
4. Finally we made a short summary some observations and corresponding processing times
1. text
with the very long processing time:
- original text: 110 s
- text
without dots: 14 s
- text
without formulas and dots: 14 s
- text
without words up to 3 chars: 9 s
2. another
text with a long processing time:
- original text: 126 s
- text
without dots: 12 s
To track the data and analysis we will pack the data of our test cases and send it to you via e-mail.
So long and best regards,
Claudia
Grote
Jan-Helge
Jacobs
Christoph
Poley
Sandro
Uhlmann
Attachments:
- fig 1
(mllm_fig1.png): processing time of texts with approx. 80000 characters
(x-axis: text length in characters, y-axis: processing time in sec.)
- fig 2
(mllm_fig2.png): processing time of uncutted full text strings (x-axis: text
length in characters, y-axis: processing time in secs.)
Osma Suominen
Thank you for the extensive report. Well done on your homework ;)
I will respond inline.
Christoph Poley kirjoitti 22.3.2022 klo 14.03:
> *1. Analysis of MLLM suggestions*
issues. For many of these persons in GND, there is just one full surname
and the remainder consists of initials and possibly years. This is
important, because MLLM - like most other Annif backends - performs
tokenization on the text, first splitting it into sentences and then the
sentences into words. The words then undergo normalization (stemming or
lemmatization, depending on the analyzer) and filtering of bad or
uninteresting tokens. The remaining normalized, filtered tokens are then
used in MLLM as the basis for comparing document text to labels in the
vocabulary.
Now what I think will happen here is that when a subject entity (person
in this case) has a label like "Braun, M. (1772-1844)", that will first
be tokenized into ['Braun', ',', 'M.', '(', '1772-1844', ')'] and this
will further be normalized (stemmed and lowercased) and filtered. The
filtering will drop tokens consisting of only punctuation or numbers, as
well as very short tokens (by default, tokens must be at least 3
characters). That leaves only the token "braun".
The same happens with persons like "Braun, Karlheinz". Although the
preferred label has the full first name and turns into ['braun',
'karlheinz'], I can see from GND that the person also has an altLabel
with just the initial, "Braun, K.". That will again be turned into the
single token 'braun'.
This means that whenever the text contains the name Braun, all persons
with the surname Braun in GND, at least those which have an altLabel
with only the initial of the first name(s), will be considered potential
matches by MLLM. This can give an awful lot of candidates that all need
to be processed, which apparently takes a long time!
I can see a few ways of fixing this.
The first is to set a lower token_min_length for the analyzer, like this:
analyzer=snowball(german,token_min_length=2)
or even
analyzer=snowball(german,token_min_length=1)
(You will need to retrain MLLM after this change)
This will relax the filtering, permitting also tokens like "k." which
should reduce the number of matched candidates a lot, at least in the
case of personal names.
The other solution would be to reduce the amount of potentially
ambiguous labels in GND, but that would probably be more difficult for you.
> However, it can also be noted that other result files whose processing
> time is in the "normal" range between 1 - 3 seconds also contain a
> similarly high number of GND descriptors that have the same word stem.
> See for example the files res_1190087464.txt or res_1173699678.txt. The
> presence of a large number of matching candidates _on the terminology
> side_ does not necessarily slow down the processing time, since none of
> these documents has a processing time as long as 1155862600.txt.
problem of too wide matching is likely at least to be an important
factor in the slowdown, if not the only one.
> The many short words (keywords: formulas or abbreviations like "dx" or
> acronyms like "CAS") are obviously another cause for the long processing
> time, as you have already suspected: They (obviously) lead to a much
> higher number of candidates for matching _on the text side_. In an
> experiment we left out all short words up to 3 characters - the
> processing time reduced down to 9 seconds.
that very short words should be included in the matching to make it more
specific, while you eliminated the short words :)
> Both together (many candidates on the text side plus many candidates on
> the terminology side) possibly lead to the high amount of GND candidates
> for the relevance list of the best.
> *2. Identification of the piece of the document that is slow to process*
> Concerning your second proposed test: We did as you suggested and
> repeatedly splitted the text in half, compared the processing speed for
> both halves and went on splitting always the half with longer processing
> time. Indeed, the part with the math expressions was the most
> problematic one concerning processing time.
>
> We constructed a text containing the same number of characters, i.e.
> 30000, by doubling the first half of the original text, and MLLM
> processing took 50% longer than with the original text. The doubled
> second half of the original text took only 45% of the time for the
> original text, but nonetheless longer than expected.
>
> We also replicated the most problematic 1875 characters up to 30000, and
> this text took more than twice as long with MLLM as the original text.
>
> The problematic words contain indeed the variable names of the math
> expressions (cp. 1155862600_AABA.txt). And the found subjects denote in
> part wrong chemical substances, besides correct mathematical expressions.
the unnecessary matches by the means I suggested above. The same fix may
also help here.
> We also found out, that we can speed up MLLM, when we delete the dots in
> the underlying text. In our example this manipulation reduced the
> processing time from 100 seconds to 14 seconds.
a time. Splitting into sentences is done using the punkt algorithm
included in NLTK, and is done mainly using full stops but also other
characters that denote sentence boundaries such as exclamation marks and
question marks. If you eliminate some or all of these, NLTK/punkt and
thus MLLM will consider the whole text as a very long sentence. It is
probably faster to perform matching only once for a long sentence than
to perform many matches for individual short sentences.
But the precision will likely be lower - there are reasons why MLLM
looks at a sentence at a time! In particular, it requires that all words
in multi-word terms must be present within the same sentence. If you
eliminate sentence boundaries, multi-word terms may be matched even if
the individual words are widely separated in the document.
Also some of the heuristics used by MLLM (first occurrence, last
occurrence, spread) rely on knowing the position where the term appears
in the document, expressed as the sentence number. If there is only one
sentence, these heuristics cannot work.
So I wouldn't do this if it can be avoided, as the quality of
suggestions will suffer.
> Last but not least we did some mass experiments with another text corpus
> to get more information about the expected processing time. Each of the
> texts has a length of approx. 80000 characters. For 80 to 90 percent of
> the suggestions MLLM needs not more than 7 seconds - fig 1.
>
> We assume, that the needed processing time depends on the length of the
> given text string with a couple of exceptions - fig 2.
>
>
>
> corresponding processing times*
>
>
> 1. text with the very long processing time:
> - original text: 110 s
> - text without dots: 14 s
> - text without formulas and dots: 14 s
> - text without words up to 3 chars: 9 s
>
> 2. another text with a long processing time:
> - original text: 126 s
> - text without dots: 12 s
> To track the data and analysis we will pack the data of our test cases
> and send it to you via e-mail.
Best,
Osma
Christoph Poley
Christoph Poley
Hi Osma,
finally we wo want to give you and the Annif users some final results of our MLLM test suite. An intern student (thanks to Katja Konermann) had a closer look to our MLLM problem and the underlying Annif code.
At first we made a few assumptions:
( 1 ) The processing time depends on the number of candidates that MLLM finds in a text - Corelation: 0.81
Have a look at assumption_1.png
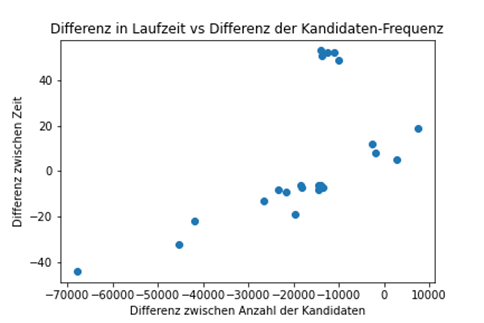
( 2 ) If the processing time for a document depends on different minimum token lengths, then the number of matches for a candidate also changes – Corelation: 0.6
Have a look at assumption_2.png
( 3 ) The extracted candidates of MLLM correspond to a sentence. Documents with a very long sentence have a longer processing time – Corelation: 0.79
Have a look at assumption_3.png
Last but not least we have two more remarks:
( 1 ) For our purpose we only want to process German documents. But a lot of the suspicious documents have English parts inside. Perhaps it can have effects according to the processing time.
( 2 ) The part of not valid tokens (numbers, special characters) has no significant effect regarding to the processing time.
Conclusions:
In our opinion it isn’t easy to find a simple reason according to the very long MLLM processing time for some of our full texts. There will happen rather a bunch of factors, e.g. terminology, minimal token size, type of labels than a single dependency. We think, it is important to know, that in some cases we have an unpredictable processing time there. We have to monitor the effects in our productive Erschließungsmaschine to make further decisions. And we are working on ways to get rid of problematic labels of our terminology that we use with MLLM.
Regards
Christoph
Christoph Poley
long time ago we did some investigations concerning the processing time of MLLM (usecase: suggestion of GND descriptors). Finally, we wrote a little tool to analyse the processing time of our Erschließungsmaschine.
We monitored all MLLM (Ensemble Omikuji with MLLM)-suggestions with a processing time of more then 5 seconds (the input text lenght is about 50000 chars). Last but not least the sum of these processing times is round about half an hour. One request produced a time out after 120 seconds.
So we conclude that we can use MLLM in a productive way to suggest GND descriptors.
Regards
Christoph

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
juho.i...@helsinki.fi
Just want to give a quick info that is related to this discussion.
We also encountered this slow processing due to dots with MLLM as you:
> We also found out, that we can speed up MLLM, when we delete the dots in the underlying text. In our example this manipulation reduced the processing time from 100 seconds to 14 seconds.
The issue was very quickly fixed in NLTK, but unfortunately there has not yet been a release with the fix included.
-Juho
Christoph Poley
Hi Osma,
We did the same investigations as you did.
And surprise, surprise: we also had a processing time of about 14 seconds, when
we leave out the dots. Hoverever, can we hope to get a new release of MLLM with a sentence tokenizer fix inside?
Regards,
Christoph
juho.i...@helsinki.fi
As soon as NLTK makes a new release with the fix, it can be straightaway put in use by MLLM even without a new Annif release, _if_ you are using Annif installed with pip (then you need to just run "pip install --upgrade nltk"). But if you are using the ready-built Docker image of Annif from quay.io, then you need to wait for the next Annif release, which will have the new NLTK release in the Docker image.
It's a bit surprising that there has been only one NLTK release this year (v3.7), because in 2021 there were 8 releases.
Actually if you want to experiment whether the NLTK fix will improve performance in your cases, you can already now install the development version of NLTK: "pip install git+https://github.com/nltk/nltk.git". In some our test documents using the development version cuts the processing time in half (~30 s -> ~15 s).
(Osma is on vacation this week).
-Juho
Christoph Poley
Hi Juho,
at the moment we include the MLLM backend as a part of our productive EMa service. For this we use the docker images. So I think it makes sense to wait a little bit for the nltk fix. It doesn’t preserve our operations.
And thank you for the detailed answers.
Christoph