Skip to first unread message

SYLVAIN COULANGE
May 19, 2020, 5:38:50 PM5/19/20
to Apprentissage des Langues Et Multimodalité, ALEM
Salut !
Je redirige ce message de Yoann dans le forum, et j'y fais suite, enfin.
Merci encore Yoann d'avoir relevé le problème, comme quoi on a pas fini de trouver des bugs d'alignement.
Il semblerait que ce soit un problématique plus importante que prévue, je la soumets donc à notre petite communauté :
Je récapitule : le problème actuel est que le 'h' de synthétique, esthétique, théâtre, apathie... est aligné à la voyelle qui suit, au lieu du 't' qui précède.
Synthétique, Esthétique, Sympathique, Théocratique, Apathie, théâtre thé rhinocéros rhétorique abhorrer
Sauf dans certains cas :
Thym rhum
Ceci est dû au fait que l'algorithme d'alignement part de la fin du mot (pour des raisons qui s'expliquent ailleurs) et qu'il aligne chaque phonème à la plus longue graphie possible dans le mot, tant qu'il arrive à tout aligner. Dans les premiers cas ci-dessus, il aligne les sons /e/ à 'hé', /i/ à 'hi' ou 'hie' parce qu'il arrive à aligner le reste des phonèmes aux graphèmes suivants (ici 't', 'r' ou 'b'). Comme les graphies 'hym' pour /ɛ̃/ et 'hu' pour /ɔ/ n'existent pas dans le Fidel, il aligne le 'h' au phonème suivant (/t/ et /r/).
J'ai proposé de forcer l'alignement 'th' lorsqu'il se présente. J'ai fait pareil pour les consonnes suivantes "c s p t w g r" qui peuvent être suivies d'un 'h' dans le Fidel d'Alexandre. Ce n'est pas le cas de 'b', 'k' ou 'x' par exemple. En faisant comme ça, voilà comment se comporte l'aligneur : (êtes-vous choqué⋅e par certains alignements ?)
Synthétique, Esthétique, Sympathique, Théocratique, Thym, Apathie, théâtre thé rhum rhinocéros rhétorique abhorrer sahara horrible hack souhait
ahaner, enhardir, brouhaha, behaviorisme, souhaiter, bréhaigne, mohair, déhancher, ahan, ahans, brouhahas, exhaure, exhausser, blockhaus, tomahawk, alzheimer, philhellène, désherber, géhenne, adhésif, cohérent, véhément, bohème, adhère, boghead, jonkheer, boghei, préhension, malheureux, bonheur, highlander, inhiber, envahissant, ébahi, cahier, hébahîmes, trahîtes, ébahie, envahies, cahin, caha, spahis,, trahit, trahît, envahît, dehors, cohorte, sorgho, khôl, éhonté, cahot, cahots, silhouette, ouache, cacahouète, racahout, racahouts, cacahuète, chihuahua, huche, ahuri, cahute, dahu, cohue, cohues, dahus, bahut, chahut, bahuts, chahuts, déshydrater, isohyète
ahaner, enhardir, brouhaha, behaviorisme, souhaiter, bréhaigne, mohair, déhancher, ahan, ahans, brouhahas, exhaure, exhausser, blockhaus, tomahawk, alzheimer, philhellène, désherber, géhenne, adhésif, cohérent, véhément, bohème, adhère, boghead, jonkheer, boghei, préhension, malheureux, bonheur, highlander, inhiber, envahissant, ébahi, cahier, hébahîmes, trahîtes, ébahie, envahies, cahin, caha, spahis,, trahit, trahît, envahît, dehors, cohorte, sorgho, khôl, éhonté, cahot, cahots, silhouette, ouache, cacahouète, racahout, racahouts, cacahuète, chihuahua, huche, ahuri, cahute, dahu, cohue, cohues, dahus, bahut, chahut, bahuts, chahuts, déshydrater, isohyète
À propos des mots en gris :
- Le Fidel actuel ne permet pas d'aligner :
- Alzheimer (/ai/ sur 'ei')
- Exhaure [ɛɡzɔʁ] (/ɔ/ sur 'hau')
- Brouhahas (/a/ sur 'has')
- Boghead [bɔɡɛd] (/ɛ/ sur 'hea')
- Tomahawk [tɔmaok] (/o/ sur 'haw')
- Désherber déshydrater ou déshabiller sont bloqués par l'alignement forcé 'sh' de la règle mentionnée ci-dessus (/z/→'sh' n'existant pas dans le Fidel, et c'est pas ce qu'on veut dans tous les cas);
- Chihuahua [ʃiwawa] plante sur l'alignement des /wa/ (pas de graphie 'hua' / 'huas' dans le Fidel ; et le bigraphe wa est toujours considéré comme un seul phonème);
Les autres mots ne sont pas dans le dico.
Perso je trouve que c'est mieux, mais c'est embêtant pour les désherber et compagnie. Sinon j'aurais plutôt aligné khôl comme ça : kh ô l ; et ahans comme ahan (a hans).
Vous avez une idée de ce qu'on peut faire ? (au pire on fait une vieille liste de mots exceptions... mais c'est un peu simple).
sylvain
De: "SYLVAIN COULANGE" <sylvain....@univ-grenoble-alpes.fr>
À: "yoanngoudin" <yoann...@yahoo.fr>
Cc: "Emilie Magnat" <emilie...@gmail.com>, "Alexandre DO" <do.alex...@gmail.com>
Envoyé: Mercredi 6 Mai 2020 21:24:01
Objet: Re: joli problème
À: "yoanngoudin" <yoann...@yahoo.fr>
Cc: "Emilie Magnat" <emilie...@gmail.com>, "Alexandre DO" <do.alex...@gmail.com>
Envoyé: Mercredi 6 Mai 2020 21:24:01
Objet: Re: joli problème
mmh voilà un truc qu'on avait pas encore vu !
Comme il y a les sons hé hi hie dans le fidel il aligne au plus long oui, et il peut aligner la suite sans problème.
C'est pas le cas de hym ou hum par contre.
Je devrais pouvoir forcer l'alignement sur th quand le h est précédé d'un t.
Pour la fonte et la taille de police, ça dépend des navigateurs oui. Il vaut mieux essayer de le fixer ? ça doit pouvoir se faire aussi.
sylvain
De: "yoanngoudin" <yoann...@yahoo.fr>
À: "SYLVAIN COULANGE" <sylvain....@univ-grenoble-alpes.fr>
Cc: "Emilie Magnat" <emilie...@gmail.com>, "Alexandre DO" <do.alex...@gmail.com>
Envoyé: Mercredi 6 Mai 2020 18:56:00
Objet: joli problème
À: "SYLVAIN COULANGE" <sylvain....@univ-grenoble-alpes.fr>
Cc: "Emilie Magnat" <emilie...@gmail.com>, "Alexandre DO" <do.alex...@gmail.com>
Envoyé: Mercredi 6 Mai 2020 18:56:00
Objet: joli problème
re re
Emilie s'évertuant à magnifier notre agitprop polychromatique,
elle a relevé un joli bug avec les h étymologiques
Synthétique
Esthétique
Sympathique
Théocratique
Thym
Esthétique
Sympathique
Théocratique
Thym
Apathie
théâtre thé
rhum rhinocéros
rhétorique
abhorrer
rhum rhinocéros
rhétorique
abhorrer
(nous remarquons au passage que rhum et thym sont bien phonographiés ;op)
vu que l'algo part de la fin du mot, est-ce que c'est possible de rajouter une règle pour les étymons à la con du genre? (e viva l'italiano e el castillano!)
mais on a le phonographe pour finir le papier : on pense à tout ;op
Merci d'avance et toujours bravo
Yo
PS : j'arrête là sinon on va dire que je procrastine (mes dossiers!)
PPS : quitte à procrastiner je rapporte un autre souci : on ne distingue décidément pas les phonochromies de /i/ et /m/
( hymne immigré )
PPS : en fonction de l'appareil dans wikicolor, je n'ai pas la même police dans mes collés :-)

Alexandre DO
May 20, 2020, 7:14:41 AM5/20/20
to alem...@googlegroups.com
Bravo pour cette recherche de mots à débugger.
Tu as mis le nouvel algo sur wikicolor ou sur wikicolor.preprod. Envoie-moi en privéle lien pour que je fasse d'autres tests. Est-ce que ça ne met pas en l'air la colorisation de son /f/ transcrit avec "ph" ?
J'essaie de réagir point par point :
- À propos des mots en gris :
- Le Fidel actuel ne permet pas d'aligner :
- Alzheimer (/ai/ sur 'ei')
- Le Fidel actuel ne permet pas d'aligner :
Recherche sur Wikipédia : La maladie d'Alzheimer (en allemand [alt͡shaɪ̯mɐ]). La lettre h a une valeur phonétique en allemand.
Le Wiktionnaire de wikicolor donne 2 transcriptions : al.zaj.mœʁ, al.zaj.mɛʁ
On va devoir forcément créer une nouvelle graphie (il faudra ouvrir une discussion spécifique à cette problématique que le numérique permet de traiter). La question est de savoir si on met le h avec le /z/ transcrit avec "zh" ou avec le /aj/ qu'on pourrait coder en deux temps, "he" qui fait /a/ et "i" qui fait /j/. Mois je préfère la solution du "zh". Une image sera plus parlante.

- Exhaure [ɛɡzɔʁ] (/ɔ/ sur 'hau')
- Brouhahas (/a/ sur 'has')
- Boghead [bɔɡɛd] (/ɛ/ sur 'hea')
- Tomahawk [tɔmaok] (/o/ sur 'haw')
- Exhaure [ɛɡzɔʁ] (/ɔ/ sur 'hau')
Dans tous ces cas, il s'agit de nouvelles graphies à rajouter au fidel. Le fidel en arrière plan du wikicolor pour la colorisation
peut être immense puisqu'il n'est jamais affiché. Le problème demeure si on veut faire paraître ces nouvelles graphies dans le fidel du phonographe de par les contraintes spatiales. Ces contraintes, encore plus grandes avec les outils papier, ont fait que, dans l'histoire des différentes versions de Fidel d'une langue, il y a eu des choix différents des graphies retenues.
Avec le numérique, dans le phonographe, on pourrait avoir des sous listes de graphies rares (appelées par un bouton dans la première liste de graphies) dès lors qu'il n'y a pas la place de tout mettre. Ou même, simplement pour un problème de lisibilité pour de jeunes élèves qui ont des problèmes d'exploration visuelle ou par rapport à des critères d'acceptabilité pour des néophytes qui seraient "effrayés" par toutes ces graphies.
L'idée de listes de plus en plus complexes des graphies transcrivant un son, comme des poupées russes, reprend un peu ma progression des claviers du panneau phonologique sur le phonographe. Ceci pourrait permettre de reprendre la réflexion du fidel sans les terminaisons grammaticales. Tout un chantier à soi tout seul.
- Désherber déshydrater ou déshabiller sont bloqués par l'alignement forcé 'sh' de la règle mentionnée ci-dessus (/z/→'sh' n'existant pas dans le Fidel, et c'est pas ce qu'on veut dans tous les cas);
l'enchainement "sh" n'existe pas pour le son /z/ mais pour le son /ch/. Du coup, forcément, tu forces une prise en compte de la lettre s qui n'existe pas.
Il me semble que le problème vient du fait que tu fait passer une règle orthographique avant la phonologie. (
J'ai proposé de forcer l'alignement 'th' lorsqu'il se présente. J'ai fait pareil pour les consonnes suivantes "c s p t w g r" qui peuvent être suivies d'un 'h' dans le Fidel d'Alexandre. )
Peut-être qu'il vaudrait mieux recenser les sons consonnes qui contiennent qui peuvent se terminer par la lettre "h". ("ph" pour /f/, "th" pour /t/, "ddh" chez Roslyn pour /d/, "sth" pour /s/, "zh" pour /z/ dans alzheimer, "ch" pour /tch/ et /ch/, "sh" et "sch" pour /ch/, "gh" pour /g/ et "rh" pour /r/)
- Chihuahua [ʃiwawa] plante sur l'alignement des /wa/ (pas de graphie 'hua' / 'huas' dans le Fidel ; et le bigraphe wa est toujours considéré comme un seul phonème);
Pour chihuahua, je ne suis d'accord avec ta généralisation. Voir les 2 exemples écrits avec le phonographe qui prévoit "hu" dans /w/.

Cela a l'avantage de distinguer les deux syllabes successives.
Quand tu dis "Perso je trouve que c'est mieux", il faudrait voir les 2 versions avec les mêmes listes de mots. Ici, c'est bizarre que dahu et dahus ne soient pas traités de la même manière comme le"hî" de hébahîmes, trahîtes
Il y a peut-être d'autres choses à régler dans ton algo avant de partir sur des listes d'exceptions. Je n'ai pas encore cherché à comprendre pourquoi certains enchainement de sons voyelles avec la lettre h au milieu marchent et d'autres non.

Robert JEANNARD
May 20, 2020, 8:17:53 AM5/20/20
to alem...@googlegroups.com
Bonjour.
Avec les emprunts, la liste des graphies s'allonge...
Je ne ferai de remarque que sur "Alzheimer".
En allemand, le z et le h font partie de 2 syllabes différentes: Alz-hei-mer et la lettre h (qui se prononce) est associée au digramme ei qui suit.
Je préférerais donc, pour ma part, la 2e solution, pour respecter la langue d'origine.
Un point de terminologie dans nos échanges: tu écris, Alexandre "le bigraphe wa" là où il faudrait, je pense, écrire "le digramme wa" (Google ne connaît pas le nom "bigraphe" sauf comme nom propre).
A+
Robert
SYLVAIN COULANGE
May 20, 2020, 11:08:34 AM5/20/20
to Apprentissage des Langues Et Multimodalité, ALEM
Hello,
Merci pour vos retours.
Tout d'abord je suis d'accord avec Robert pour Alzheimer. Même si ça fait bizarre d'aligner 'he' au son /a/ !
On reste dans la phono du français certes, mais je serais curieux de voir comment c'est transcrit dans le Fidel d'allemand. Intuitivement j'aurais mis une bicolore /aj/ sur hei. Mais pour la phono allemande bien sûr. Pour le français... he→/a/ est peut-être le moins inadéquat effectivement.
Pour tes remarques Alexandre :
- par rapport au fait de compléter le Fidel, on peut partir (comme on s'était dit rapidement) sur un Fidel plus exhaustif inspiré du Robert2004 (sans les oi et compagnie). Pour le Phonographe, on garde un objectif péda en priorité. J'aime l'idée de proposer les graphies d'emprunt dans un menu complémentaire, fermé par défaut, mais qu'on peut ouvrir pour allonger la liste des graphies avec les emprunts en petite taille.
- pour chihuahua, ton Fidel permet effecivement de pointer 'hu' sur /w/, mais l'aligneur considère le bigraphe wa comme un seul phonème, pour les besoins du Silent Way. Je crois qu'on touche là à la limite de ce système phonétiquement contre-intuitif (mais pédagogiquement pertinent, je le conçois).
- les mots qui restent gris (hébahîmes, cohérent etc.) le restent parce qu'ils ne sont pas dans le dictionnaire (j'ai listé toutes les raisons de non alignement dans le premier message).
Une fois que j'aurais terminé la documentation du code, tu pourras éventuellement proposer des alternatives de traitement.
- pour désherber,la règle actuelle part du recensement des graphies consonnes qui se terminent par un 'h', comme tu proposes : (mais basé seulement sur ton Fidel)
FidelDo : "ah","ach","euh","ah","oh","wh","ph","th","ch","sth","ch","sh","sch","cch","ch","gh","rrh","rh"
J'en sors les lettres : c w p t s g r auxquelles je force l'alignement avec 'h' pour éviter T HÉ O R IE par exemple.
mais c'est tout le problème avec "désherber" : la règle actuelle dit que même si la graphie 'he' est plus longue, comme il y a un 's' après (dans le sens d'alignement), il laisse le 'h' pour le phonème suivant. Comme /z/ ne peut pas s'aligner sur 'sh', il plante. On peut envisager une règle supplémentaire, qui force l'alignement sur 'sh' SAUF si le phonème suivant dans la transcription est /z/. Ça ajoute encore une règle... mais comment faire plus simplement ?
Pour info voilà la gueule des 200 lignes du code actuel juste pour l'alignement :
Le principe de base est simple (aligner chaque phonème à la graphie la plus longue) mais c'est bourré d'exceptions.
De: "Robert jeannard" <robert....@wanadoo.fr>
À: "Apprentissage des Langues Et Multimodalité, ALEM" <alem...@googlegroups.com>
Envoyé: Mercredi 20 Mai 2020 14:17:13
Objet: Re: [ALEM] WikiColor : alignement du 'h'
À: "Apprentissage des Langues Et Multimodalité, ALEM" <alem...@googlegroups.com>
Envoyé: Mercredi 20 Mai 2020 14:17:13
Objet: Re: [ALEM] WikiColor : alignement du 'h'
--
Pour répondre à ce message, vous pouvez utiliser le bouton "Répondre" de votre messagerie.
Pour écrire sur un nouveau sujet, rendez-vous sur le forum : https://groups.google.com/d/forum/alem-app
---
Vous recevez ce message, car vous êtes abonné au groupe Google Groupes "Apprentissage des Langues Et Multimodalité (ALEM)".
Pour vous désabonner de ce groupe et ne plus recevoir d'e-mails le concernant, envoyez un e-mail à l'adresse alem-app+u...@googlegroups.com.
Cette discussion peut être lue sur le Web à l'adresse https://groups.google.com/d/msgid/alem-app/CAEO1s85acP0oW1fm_dBdG1T9SSot0n1v%2BGpsxq6ada44RVapTQ%40mail.gmail.com.
Pour répondre à ce message, vous pouvez utiliser le bouton "Répondre" de votre messagerie.
Pour écrire sur un nouveau sujet, rendez-vous sur le forum : https://groups.google.com/d/forum/alem-app
---
Vous recevez ce message, car vous êtes abonné au groupe Google Groupes "Apprentissage des Langues Et Multimodalité (ALEM)".
Pour vous désabonner de ce groupe et ne plus recevoir d'e-mails le concernant, envoyez un e-mail à l'adresse alem-app+u...@googlegroups.com.
Cette discussion peut être lue sur le Web à l'adresse https://groups.google.com/d/msgid/alem-app/CAN6_WqbNf2_4P0643e%2By%3DrvzU%2BW_2xqT%3Du%2BjUSzN10hKEqx8bg%40mail.gmail.com.
SYLVAIN COULANGE
May 20, 2020, 5:55:09 PM5/20/20
to Apprentissage des Langues Et Multimodalité, ALEM
Salut !
Voilà un premier jet de l'explication du fonctionnement de l'aligneur phonographémique (phon2graph).
J'ai essayé de faire au plus simple. N'hésitez pas à me dire si des choses ne sont pas claires.
À l'occasion j'essaierai de trouver une solution pour les "désherbages" et "bouddhisme", "kolkhoze" etc.
Je crois pas que ce soit tellement une priorité pour l'instant.
J'ai très envie de lancer une expérimentation à large échelle sur le corpus ORFEO (10 millions de mots) et établir des statistiques de phonie/graphie.
J'ai encore mes accès aux serveurs du laboratoire d'informatique, on a de quoi faire tourner du lourd.
Yoann, si ça te tante, on se lance dedans, et on écrit dessus.
J'ai mis à jour le script sur le serveur. Je vous laisse me rapporter tous les bugs d'alignement que vous trouvez. Pensez à vérifier le dictionnaire aussi, il y a quelques entrées qui ne s'y trouvent pas. Je ferai bientôt en sorte qu'on puisse ajouter des entrées dans le dictionnaire.
N'hésitez pas à modifier le dictionnaire en tout cas, pour ajouter des transcriptions possibles à un mot, ou changer leur ordre d'apparition. Tout est enregistré, ça ne risque rien. Plus le dico sera modifié, plus il prendra de la valeur. N'hésitez pas à me suggérer des choses pour faciliter son édition.
Sylvain
De: "SYLVAIN COULANGE" <sylvain....@univ-grenoble-alpes.fr>
Envoyé: Mercredi 20 Mai 2020 17:08:32
Cette discussion peut être lue sur le Web à l'adresse https://groups.google.com/d/msgid/alem-app/798291730.11959683.1589987312694.JavaMail.zimbra%40univ-grenoble-alpes.fr.
Alexandre DO
May 21, 2020, 2:53:33 PM5/21/20
to alem...@googlegroups.com
Salut Sylvain,

j'ai lu la description du fonctionnement et j'ai relevé des choses à reformuler et d'autres sources de dysfonctionnement.
- Dans le premier paragraphe "Phon2graph", tu dis : les sons /wa/ ou /ks/ sont donc considérés comme des phonèmes uniques.
Pour /ks/, cela ne semble pas poser problème mais pour /wa/, ce n'est pas toujours vrai.
J'ai testé le wikicolor avec les mots suivants (à mettre dans les phrases de débuggage) :
un accident, le tocsin, le wapiti, de la ouate, des watts, une kawasaki, la langue ajawa, jouer à l'awalé, le Botswana, manger des chawarmas, des chihuahuas, une équation, un aquarium, un voyage
J'ai obtenu ceci :
un accident, le tocsin, le apiti, de la ouate, des atts, une kawasaki, la langue ajawa, jouer à l’ awalé, le Botswana, manger des chawarmas, des chihuahuas, une équation, un aquarium, un voyage
Pour les mots contenant l'enchainement de lettres 'wa', il faudrait clairement que chaque phonème soit considéré séparément : 2 sons pour 2 lettres, chacune existant dans le fidel dans le bon phonème. Lorsque ces lettres sont à l'intérieur de mots, l'algo ne peut pas coloriser puisqu'il n'existe pas le digramme wa dans la colonne du son /wa/. Mais lorsque ces 2 lettres sont en début de mot, l'algo supprime tout simplement la première lettre comme dans "wapiti" ou "watt". Ce n'est pas possible.
Cette unification des sons /w/ et /a/ ne peut pas être imposée a priori mais seulement si ce traitement séparé ne peut pas aboutir. Ceci est le cas lorsque /wa/ correspond à un enchainement de lettres commençant avec oi, puisque le i ne peut décemment pas se trouver dans la liste des graphies du son /a/.
Voilà comment je verrai le pointage de quelques uns de ces mots avec mon fidel :
wapiti, watt, ouate, awalé, équation ou équation ou équation
Je préfère la ouate colorisée comme ceci que comme dans le wikicolor actuel. Pour équation, je préfère la première solution. Ce qui pourrait permettre d'enlever dans la case /wa/ du fidel, les graphies ua, oua, a et at. Dans le doc "comparaisonFidels" qu'il faudrait mettre dans le dossier partagé avec la version la plus à jour, il serait peut-être bien de rajouter une colonne avec les graphies du fidel de l'UEPD de 1998 d'où je suis parti pour voir les modifications faites par moi et Roslyn. Dans ce dossier partagé, il faudrait aussi mettre le document de travail élaboré par Ben (je crois) et mis en forme par Robert lors du travail de refonte initié par Roslyn.
A noter que dans mon fidel issu de UEPD, dans le son /w/ figure la graphie 'o' qui pourrait permettre de pointer le glissement possible de valeur de la lettre 'o' si on répète très vite la phrase : Do Alice a les doigts lisses. (Il a fallu batailler pour trouver un prénom sans jeu de mot avec mon nom. La je suis tranquille, ma femme ne l'a pas vu !!!)
Do Alice a les
doigts lisses.
doigts lisses.
Do Alice a les
doigts lisses.
doigts lisses.
Ce 'o' dans le son /w/ pourrait aussi servir pour coloriser "o.in" en /w.ɛ̃/ en deux couleurs séparées plutôt que de faire
"oin" en /wɛ̃/ en un trigramme
bicolore.
J'ai donc poussé plus loin la recherche sur la colorisation des sons /w/, /wɛ̃/ et /wa/.
Je viens de voir des différences de pointage avec le fidel de Roslyn :
Dans le son /w/, elle a supprimé le 'o'. On ne pourrait plus écrire, comme avec mon fidel :
Soazic
Est-ce une raison suffisante pour que je garde ce 'o' dans /w/ dans mon fidel ? Notre breton de service nous dira. C'est la région de France où il y a le plus de Soazic.
Dans le son
/wɛ̃/
, aucune différence.
Dans le son /wa/, elle a enlevé les graphies 'oua', 'ua', 'a', 'at' comme je m’apprête à le faire (cf plus haut). Elle a aussi enlevé 'oye' et 'oyes' qu'on trouve dans le wiktionnaire mais pas dans des mots courants. Le plus surprenant, c'est la suppression du 'o' dont nous avons besoin pour coder les mots "voyage" ou encore "soyons, soyez". Cette suppression est compensée par le rajout de la graphie 'oy'. Je pense, et il faudra vérifier auprès de Roslyn et Piers, que cela vient de leur fameuse trouvaille de la liaison interne. C'est pour cela qu'ils n'ont pas besoin du 'u' bicolore pour "tuyau" par exemple ou des graphies bicolores 'i', 'y' et 'hi' pour transcrire /ij/ dans "client, hier ou cryothérapie". Je pense que Roslyn pointerait sur sa version du phonographe comme ceci :
tuy͜au, cli͜ent, hi͜er, cry͜othérapie
alors que moi, je pointerais :
Je ne sais pas comment wikicolor pourrait marquer les liaisons internes comme Roslyn et Piers. Faudra déjà se pencher sur le traitement des liaisons entre les mots.
- Dans le paragraphe "Alignement" tu dis : " À chaque alignement, le phonème aligné et la graphie choisie sont supprimées."
- Dans le paragraphe "Cas des phonèmes bigraphes"
- dans le paragraphe " Identification de la graphie cible"
Ta description du travail de l'algorithme ne me semble pas correspondre au fonctionnement que j'ai compris sur la description du traitement du mot "essentiel".
J'ose proposer quelque chose pour corriger les étapes 5, 6 et 7. Je remets aussi les phonèmes entre //. Mais tu connais mieux ton algo que moi.
- "essentiel" /esɑ̃sjɛl/ : /l/ → 'l'
- "essentie" /esɑ̃sjɛ/ : /ɛ/ → 'e'
- "essenti" /esɑ̃sj/ : /j/ → 'i'
- "essent" /esɑ̃s/ : /s/ → 'ssent' (ou sent ou t,comme on le verra par la suite)
- "e" /esɑ̃/ : /ɑ̃/ → 'e'
- "" /es/ : alignement impossible puisqu'il n'y a plus de lettres : on revient au phonème précédent (cf étape 5)
- "e" /esɑ̃/ : /pas d'autres solutions que celle prise en 5 puisque le "e" est la dernière lettre. On revient donc au phonème précédent (cf étape 4)
- essent" /esɑ̃s/ : /s/ il reste 'sent' et 't'. On prend la plus longue
- "es" /esɑ̃/ : /ɑ̃/ → alignement impossible : 'es' n'existe pas dans la liste des graphies du son /ɑ̃/ : on revient au phonème précédent
- "essent" /esɑ̃s/ : /s/ → il reste 't'. On le prend.
- "essen" /esɑ̃/ : /ɑ̃/ → 'en'
- "ess" /es/ : /s/ → 'ss' (ou 's')
- "e" /e/ : /e/ → 'e'
Résultat : /e/→e, /s/→ss, /ɑ̃/→en, /s/→j, /ɛ/→e, /l/→l
Ouf, ça m'a fait travailler 7 heures de faire tous ces tests et toutes ces comparaisons !!!
SYLVAIN COULANGE
May 22, 2020, 8:36:54 AM5/22/20
to Apprentissage des Langues Et Multimodalité, ALEM
7h ??? c'est pas vrai ?!
OK pour la reformulation pour les caractères "supprimés".
Pour le wa et le ouin, merci d'avoir pris le temps de faire tous ces tests. Ça a fait ressortir de nouveaux problèmes (mais liés aux chihuahuas de l'autre jour).
Pour le Fidel, les comparaison etc. je vous laisse voir comment on procède. Les collègues qui nous lisent auront sans doute leur avis à donner également.
Perso, je suis d'accord pour éviter au maximum le bicolore pour wa et ouin, comme tu proposes. À voir de quelle manière je peux dire à l'algo de tenter un alignement sur /w/ et /a/ puis sur /wa/ seulement si il n'a pas réussi.
Ça résoudra le problème de colorisation de kawasaki ajawa awalé Botswana chawarmas chihuahuas, qui sont tous dans le dico.
Très juste pour l'exemple d'essentiel ! Tu as l'œil ;) c'est bien ce que je voulais dire mais je me suis planté en écrivant.
sylvain
De: "Alexandre DO" <do.alex...@gmail.com>
Envoyé: Jeudi 21 Mai 2020 20:52:52
Objet: Re: [ALEM] WikiColor : alignement du 'h'
--
Pour répondre à ce message, vous pouvez utiliser le bouton "Répondre" de votre messagerie.
Pour écrire sur un nouveau sujet, rendez-vous sur le forum : https://groups.google.com/d/forum/alem-app
---
Vous recevez ce message, car vous êtes abonné au groupe Google Groupes "Apprentissage des Langues Et Multimodalité (ALEM)".
Pour vous désabonner de ce groupe et ne plus recevoir d'e-mails le concernant, envoyez un e-mail à l'adresse alem-app+u...@googlegroups.com.
Pour répondre à ce message, vous pouvez utiliser le bouton "Répondre" de votre messagerie.
Pour écrire sur un nouveau sujet, rendez-vous sur le forum : https://groups.google.com/d/forum/alem-app
---
Vous recevez ce message, car vous êtes abonné au groupe Google Groupes "Apprentissage des Langues Et Multimodalité (ALEM)".
Pour vous désabonner de ce groupe et ne plus recevoir d'e-mails le concernant, envoyez un e-mail à l'adresse alem-app+u...@googlegroups.com.
Cette discussion peut être lue sur le Web à l'adresse https://groups.google.com/d/msgid/alem-app/CAEO1s85uRCNu6qHgjRv2aX2HpU-wFU%2BMBHRi-PvwPZ4%2BQJQXhQ%40mail.gmail.com.
SYLVAIN COULANGE
May 22, 2020, 11:11:04 AM5/22/20
to Apprentissage des Langues Et Multimodalité, ALEM
un accident, le tocsin, le wapiti, de la ouate, des watts, une kawasaki, la langue ajawa, jouer à l’ awalé, le Botswana, manger des chawarmas, des chihuahuas, une équation, un aquarium, un voyage
Est-ce que ça vous convient ?
Maintenant /wa/ n'est considéré comme un seul phonème que si le mot finit par une des graphies suivantes :
oi,oî,oe,oê,o,oie,oix,oid,oig,hoi,oye,ois,oîs,oît,oit,oits,oies,oient,oids,oigt,oigts,oyes
De même pour /wɛ̃/, considéré comme un seul phonème que si le mot finit par On pourrait ajouter aussi [^o]oing et [^o]oings (=toute lettre sauf 'o') pour coloriser shampooing : /w/→'oo', /ɛ̃/→'ing'
oin,oint,oins,oints,oing,oings
J'ai généré un Fidel "se voulant exhaustif" pour WikiColor, comme convenu, en combinant les Fidels d'Alexandre, de PronSci et du Robert 2004.
À l'avenir faudrait que j'ajoute un petit symbol sur WikiColor qui indique quand le mot n'est pas dans le dictionnaire. Comme ça on pourra plus vite identifier les bugs de coloration.
J'en ai profité pour corriger un bug de ponctuation qui passait en noir lors du copier/coller.
Alexandre je t'ajoute dans les contributeurs de l'algo, je l'avais pas fait.
sylvain
De: "SYLVAIN COULANGE" <sylvain....@univ-grenoble-alpes.fr>
Envoyé: Vendredi 22 Mai 2020 14:36:52
Cette discussion peut être lue sur le Web à l'adresse https://groups.google.com/d/msgid/alem-app/1270055162.12377443.1590151012760.JavaMail.zimbra%40univ-grenoble-alpes.fr.
Robert JEANNARD
May 22, 2020, 3:46:15 PM5/22/20
to alem...@googlegroups.com
Waouh ! Quel beau travail !
Quelques remarques.
- Pour "voyage", dans le message de Sylvain, je vois

alors qu'en utilisant le coloriseur, j'obtiens correctement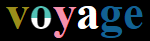
par contre avec le phonographe, faute de "o" bicolore, il est impossible de transcrire ce mot. - Je ne comprends pas pourquoi on se complique la vie pour le "ts" de "Botswana":
 ne convient-il pas?
ne convient-il pas? - J'apprends enfin, à travers ce que dit Alexandre, ce concept de "liaison interne" qui permet au fidel de Rosyn Young de se passer du i et du y bicolores. J'avoue être séduit, il y a une vraie analogie de fonctionnement avec la liaison externe: 1) le 2e phonème (le yod) est une dérivation du premier 2) il fait partie de la syllabe suivante.
A+
Robert
SYLVAIN COULANGE
May 22, 2020, 4:50:12 PM5/22/20
to Apprentissage des Langues Et Multimodalité, ALEM
Robert, il y a une fonctionnalité pour copier coller le texte directement depuis WikiColor ou PhonoGraphe,
c'est le petit bouton  à droite de la zone de texte.
à droite de la zone de texte.
Ça permet d'écrire en couleur directement dans le mail par exemple.
Mais comme on ne peut pas écrire avec des lettres bicolores, on a opté pour le fond dans une couleur et la lettre dans l'autre.
C'est pas ouf mais ça permet de garder les deux couleurs.
( Ça marche aussi en bicolore )
Et effectivement, je me demande d'où il sort ce /ts/, ça dit quelque chose à quelqu'un ?
Pour l'instant je l'enlève, je trouve pas de mot qui aurait besoin d'un bicolore /ts/ en français!
Tsigane Botswana tsunami kilohertz
Si cela chagrine quelqu'un, qu'il se manifeste.
sylvain
De: "Robert jeannard" <robert....@wanadoo.fr>
Envoyé: Vendredi 22 Mai 2020 21:45:35
Objet: Re: [ALEM] WikiColor : alignement du 'h'
--
Pour répondre à ce message, vous pouvez utiliser le bouton "Répondre" de votre messagerie.
Pour écrire sur un nouveau sujet, rendez-vous sur le forum : https://groups.google.com/d/forum/alem-app
---
Vous recevez ce message, car vous êtes abonné au groupe Google Groupes "Apprentissage des Langues Et Multimodalité (ALEM)".
Pour vous désabonner de ce groupe et ne plus recevoir d'e-mails le concernant, envoyez un e-mail à l'adresse alem-app+u...@googlegroups.com.
Pour répondre à ce message, vous pouvez utiliser le bouton "Répondre" de votre messagerie.
Pour écrire sur un nouveau sujet, rendez-vous sur le forum : https://groups.google.com/d/forum/alem-app
---
Vous recevez ce message, car vous êtes abonné au groupe Google Groupes "Apprentissage des Langues Et Multimodalité (ALEM)".
Pour vous désabonner de ce groupe et ne plus recevoir d'e-mails le concernant, envoyez un e-mail à l'adresse alem-app+u...@googlegroups.com.
Cette discussion peut être lue sur le Web à l'adresse https://groups.google.com/d/msgid/alem-app/CAN6_WqbUgFdDLn3SoXz%3DsgqEJ2FOpVLepTdjH7%2BuopW%3D03ztDA%40mail.gmail.com.
Alexandre DO
May 22, 2020, 5:40:50 PM5/22/20
to alem...@googlegroups.com
Bonsoir Robert,
concernant la transcription de voyage, comme je le disais dans mon message, le 'o' a disparu chez Roslyn certainement sous l'effet de la liaison interne.
Je viens de le remarquer à l'occasion de ce travail de programmation du wikicolor. Roslyn nous avait fait une rapide présentation de ce concept en novembre à Lyon quand elle est venue nous présenter son fidel et ses panneaux de mots. On ne parlait pas encore du wikicolor et du phonographe à cette époque.
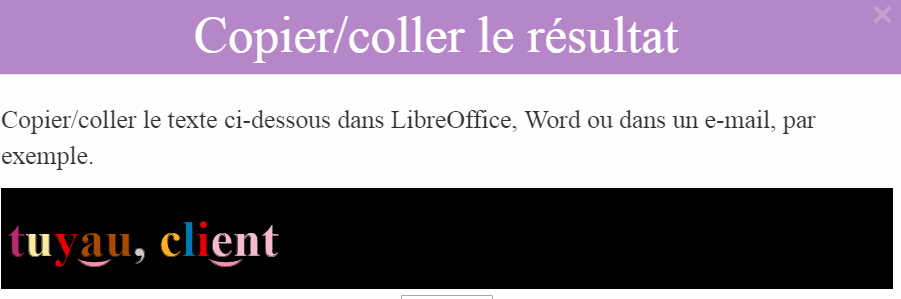
Je viens de refaire le pointage au phonographe de plusieurs mots transcrits avec la liaison interne. Je l'ai déjà fait hier mais je viens de m'apercevoir que l'export en copier-coller ne garde pas la bonne couleurs de la liaison interne.(Sylvain, c'est à toi de jouer) alors que à l'écran tout est correct dans le phonographe.
Voici ce que je vois et que j'ai pointé, exporté en image :

Voici la même chose exporté de la même page du phonographe, ouverte dans firefox, au format texte via la fonction copier-coller décrite par Sylvain :
tuy͜au, cli͜ent, hi͜er, cry͜othérapie, voy͜age, soy͜ons
Cette fois, la couleur de la liaison interne à l'air correcte. Le seul problème c'est qu'on ne sait pas à quel moment prononcer le /j/.
Alors qu'à l'écran, c'est mieux.
Je refais donc l'essai avec chrome. C'est étrange et ce qui suit soulève encore une autre question pour Sylvain.
Je commence à taper la même chose et la liaison interne s'affiche dans la couleur du dernier son pointé, ici le /i/ :

Si j'ouvre la fonction de saisie manuelle et que je la referme,
 la liaison interne reprend la bonne couleur, y compris pour les mots suivants :
la liaison interne reprend la bonne couleur, y compris pour les mots suivants :
Par contre, au moment de l'export du texte de la page chrome via la fonction copier-coller,
la couleur de la liaison interne n'est plus bonne :
tuy͜au, cli͜ent
Elle est bonne au moment où je colle le texte mais une fois le message envoyé, c'est la couleur du /i/ qui revient. ????
Pour preuve, voici une image de ce que je vois avant l'envoi :

C'est vraiment fou ????
Alexandre DO
May 22, 2020, 5:51:20 PM5/22/20
to alem...@googlegroups.com
En fait, la couleur de la liaison interne a changé après envoi de la même façon, que je fasse du copier-coller depuis une page firefox ou depuis une page chrome.
Mais
la couleur ne se perd pas
si je colle
sur un document word,
le texte extrait :

C'est peut-être parce que je colle ces mots dans la messagerie ouverte sous chrome ????
SYLVAIN COULANGE
May 22, 2020, 6:13:51 PM5/22/20
to Apprentissage des Langues Et Multimodalité, ALEM
Salut Alexandre,
oui ce bug que tu m'avais déjà rapporté est lié à Chrome.
J'ai aucune idée de comment le gérer, à part changer la façon d'écrire la liaison interne.
Il est possible que le bug de Chrome soit corrigé dans les prochains mois. Ça évolue vite.
sylvain
De: "Alexandre DO" <do.alex...@gmail.com>
À: "Apprentissage des Langues Et Multimodalité, ALEM" <alem...@googlegroups.com>
À: "Apprentissage des Langues Et Multimodalité, ALEM" <alem...@googlegroups.com>
Envoyé: Vendredi 22 Mai 2020 23:50:42
Objet: Re: [ALEM] WikiColor : alignement du 'h'
--
Pour répondre à ce message, vous pouvez utiliser le bouton "Répondre" de votre messagerie.
Pour écrire sur un nouveau sujet, rendez-vous sur le forum : https://groups.google.com/d/forum/alem-app
---
Vous recevez ce message, car vous êtes abonné au groupe Google Groupes "Apprentissage des Langues Et Multimodalité (ALEM)".
Pour vous désabonner de ce groupe et ne plus recevoir d'e-mails le concernant, envoyez un e-mail à l'adresse alem-app+u...@googlegroups.com.
Pour répondre à ce message, vous pouvez utiliser le bouton "Répondre" de votre messagerie.
Pour écrire sur un nouveau sujet, rendez-vous sur le forum : https://groups.google.com/d/forum/alem-app
---
Vous recevez ce message, car vous êtes abonné au groupe Google Groupes "Apprentissage des Langues Et Multimodalité (ALEM)".
Pour vous désabonner de ce groupe et ne plus recevoir d'e-mails le concernant, envoyez un e-mail à l'adresse alem-app+u...@googlegroups.com.
Cette discussion peut être lue sur le Web à l'adresse https://groups.google.com/d/msgid/alem-app/CAEO1s87qi92_5UghDFfydeQUjNBM6KkjguOjXmeHNzOtzdgxtA%40mail.gmail.com.
Alexandre DO
May 23, 2020, 2:02:20 AM5/23/20
to alem...@googlegroups.com
Ok. Du coup ne perds pas de temps avec ça.
Le tout, c'est de le savoir pour pouvoir l'expliquer si ce bug nous remonte.
Alexandre DO
May 24, 2020, 4:57:19 PM5/24/20
to alem...@googlegroups.com
Bonsoir,
il me semble que j'avais réagi à ce message mais je ne retrouve pas ce que je suis pourtant certain d'avoir écrit. Peut-être l'ai-je fait dans un autre fil de discussion ou alors je l'ai effacé par erreur.
Oui, cette nouvelle façon de considérer le son /wa/ me convient bien mieux.
Par contre, quand tu dis que tu as unifié tous les dictionnaires, j'espère que tu n'as pas intégré toutes les graphies qui commencent par la lettre 'i' dans le phonème /a/ et /a/.
J'avais donc immédiatement vérifié une série de mots avec les sons /wɛ̃/ et /wa/.
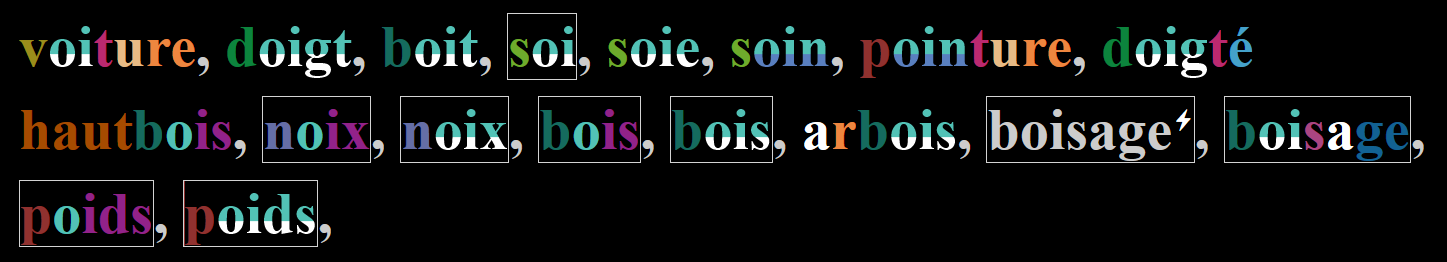
J'ai compris qu'il n'y a pas de problème pour les sons /wa/ mais uniquement pour les sons /wa/.
Soit tu avais nettoyé de la liste des graphies du Robert 2004 les 'i' dans le /a/ mais pas dans le /a/,
soit tu as trouvé une façon de programmer le traitement de son /wa/ mais tu as oublié d'appliquer le même traitement pour le sons /wa/.
Cependant, je continue à penser qu'il ne faut pas mettre les graphies en 'i' dans les sons /a/.
Ensuite, j'avais dû écrire à propos des mots en "désh...".
Dans ta description du phon2graph, tu dis : "Dans "château", aligner /a/ à "hâ" ne permettrait pas de terminer l'alignement, une règle permet donc d'éviter les graphies commençant par un 'h' si le caractère précédent ce 'h' fait partie des caractères suivants : "c s p t w g r". Dans ces cas précis, la probabilité que le 'h' fasse partie de la graphie suivante est plus grande ("wh","ph","th","ch","sth","ch","sh","sch","cch","ch","gh","rrh","rh"). La majorité des alignements convient, mais il reste quelques problèmes : "désherber" ou "déshydrater", pour lesquels l'alignement plante (/z/→'sh' impossible) "
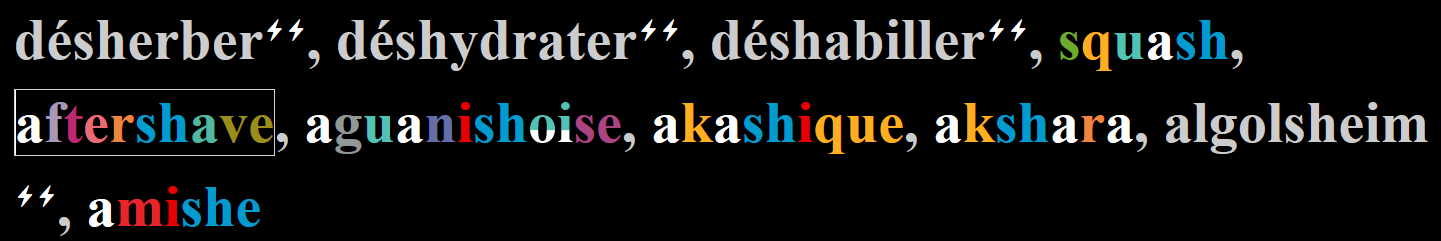
Il me semble que tu pourrais essayer d'enlever la lettre 's' dans la liste des exceptions.
Il faudrait vérifier si cela n'empêche pas le fonctionnement de l'algo pour les mots où 'sh' transcrit /ʃ/.
Sinon, pour la lettre 's', il faudra mettre une double condition : si la lettre 's' est précédée de la lettre 'h' pour transcrire le son
/ʃ/, alors le h n'est pas considéré dans le son voyelle suivant.
Tu me diras si c'est compréhensible.
Alexandre
Robert Jeannard
May 25, 2020, 6:46:14 AM5/25/20
to Apprentissage des Langues Et Multimodalité (ALEM)
Bonjour.
Relevé ce matin au cours d'essais dans Wikiclor: "oeil" est transcrit "eil".
A+
Robert
SYLVAIN COULANGE
May 25, 2020, 7:59:35 AM5/25/20
to Apprentissage des Langues Et Multimodalité, ALEM
Bonjour Robert,
c'est parce que le Fidel ne permet pas d'aligner "oe" à /œ/. (on peut l'ajouter éventuellement)
Ça marche que si on écrit "œil".
De: "Robert jeannard" <robert....@wanadoo.fr>
Envoyé: Lundi 25 Mai 2020 12:46:14
Objet: [ALEM] WikiColor : problèmes d'alignement
Objet: [ALEM] WikiColor : problèmes d'alignement
--
Pour répondre à ce message, vous pouvez utiliser le bouton "Répondre" de votre messagerie.
Pour écrire sur un nouveau sujet, rendez-vous sur le forum : https://groups.google.com/d/forum/alem-app
---
Vous recevez ce message, car vous êtes abonné au groupe Google Groupes "Apprentissage des Langues Et Multimodalité (ALEM)".
Pour vous désabonner de ce groupe et ne plus recevoir d'e-mails le concernant, envoyez un e-mail à l'adresse alem-app+u...@googlegroups.com.
Pour écrire sur un nouveau sujet, rendez-vous sur le forum : https://groups.google.com/d/forum/alem-app
---
Vous recevez ce message, car vous êtes abonné au groupe Google Groupes "Apprentissage des Langues Et Multimodalité (ALEM)".
Pour vous désabonner de ce groupe et ne plus recevoir d'e-mails le concernant, envoyez un e-mail à l'adresse alem-app+u...@googlegroups.com.
Cette discussion peut être lue sur le Web à l'adresse https://groups.google.com/d/msgid/alem-app/00a84fff-215e-4395-9796-4f090afabc7e%40googlegroups.com.
SYLVAIN COULANGE
May 25, 2020, 8:05:20 AM5/25/20
to Apprentissage des Langues Et Multimodalité, ALEM
Très juste !
J'ai juste oublié de traiter le /ɑ/... il n'existe pas pour moi c'est pour ça ;)
je vais l'ajouter.
De: "Alexandre DO" <do.alex...@gmail.com>
À: "Apprentissage des Langues Et Multimodalité, ALEM" <alem...@googlegroups.com>
À: "Apprentissage des Langues Et Multimodalité, ALEM" <alem...@googlegroups.com>
Envoyé: Dimanche 24 Mai 2020 22:56:41
Objet: Re: [ALEM] WikiColor : alignement du 'h'
--
Pour répondre à ce message, vous pouvez utiliser le bouton "Répondre" de votre messagerie.
Pour écrire sur un nouveau sujet, rendez-vous sur le forum : https://groups.google.com/d/forum/alem-app
---
Vous recevez ce message, car vous êtes abonné au groupe Google Groupes "Apprentissage des Langues Et Multimodalité (ALEM)".
Pour vous désabonner de ce groupe et ne plus recevoir d'e-mails le concernant, envoyez un e-mail à l'adresse alem-app+u...@googlegroups.com.
Pour écrire sur un nouveau sujet, rendez-vous sur le forum : https://groups.google.com/d/forum/alem-app
---
Vous recevez ce message, car vous êtes abonné au groupe Google Groupes "Apprentissage des Langues Et Multimodalité (ALEM)".
Pour vous désabonner de ce groupe et ne plus recevoir d'e-mails le concernant, envoyez un e-mail à l'adresse alem-app+u...@googlegroups.com.
Cette discussion peut être lue sur le Web à l'adresse https://groups.google.com/d/msgid/alem-app/CAEO1s87JOZTs5hBPOYHUpo%3D_783QFS%3D7HE9CFWshVU-QYXeuKg%40mail.gmail.com.
SYLVAIN COULANGE
May 25, 2020, 8:17:03 AM5/25/20
to Apprentissage des Langues Et Multimodalité, ALEM
Enfait je me rends compte que j'ai pas d'entrée /wɑ/ dans le Fidel, et qu'on en a jamais eues ! Ni dans le tien Alexandre, ni dans PronSci (je parle des Fidels de PhonoGraphe)
Qu'est-ce qu'on fait ?
Soit je traite les /ɑ/ comme des /a/ et c'est réglé, soit vous me fournissez la liste des graphies de /wɑ/ que vous souhaitez intégrer, et je les ajoute dans le Fidel global. À voir de quelle manière on fusionne les deux après...
J'arrive vraiment pas à me convaincre de l'intérêt didactique de garder le /ɑ/... (pareil pour œ̃)
sylvain
De: "SYLVAIN COULANGE" <sylvain....@univ-grenoble-alpes.fr>
Envoyé: Lundi 25 Mai 2020 14:05:19
Cette discussion peut être lue sur le Web à l'adresse https://groups.google.com/d/msgid/alem-app/390074594.13464552.1590408319304.JavaMail.zimbra%40univ-grenoble-alpes.fr.
Robert JEANNARD
May 25, 2020, 10:28:25 AM5/25/20
to alem...@googlegroups.com
OK, j'ai vérifié, ça fonctionne.
Il est cependant difficile d'obtenir "œ" dans la fenêtre de saisie du Wikicolor: le correcteur orthographique ne fonctionne pas et ne le propose donc pas, il faut recourir à un copié-collé depuis un traitement de texte ou au raccourci clavier Alt+0156, pas évident.
Pas très important.
Robert
Robert
Le lun. 25 mai 2020 à 15:59, SYLVAIN COULANGE a écrit :
Bonjour Robert,c'est parce que le Fidel ne permet pas d'aligner "oe" à /œ/. (on peut l'ajouter éventuellement)Ça marche que si on écrit "œil".
De: "Robert jeannard"
À: "Apprentissage des Langues Et Multimodalité, ALEM" <alem...@googlegroups.com>
Envoyé: Lundi 25 Mai 2020 12:46:14
Objet: [ALEM] WikiColor : problèmes d'alignement
Bonjour.Relevé ce matin au cours d'essais dans Wikiclor: "oeil" est transcrit "eil".A+Robert
SYLVAIN COULANGE
May 25, 2020, 11:17:55 AM5/25/20
to Apprentissage des Langues Et Multimodalité, ALEM
Je ne peux pas savoir quand l'utilisateur veut écrire œ, et quand il veut écrire oe. Il y a certainement des cas où c'est l'un et pas l'autre.
Le plus simple semble-t-il, est d'ajouter les graphies correspondantes dans le Fidel (oe, oeu, oeux etc.). Mais ça voudrait dire que le résultat sortirait comme il a été entré (si l'utilisateur écrit oeil, il obtien oeil colorisé, et pas œil.
Par contre le dictionnaire ne contient pas d'entrée "soeur" (il faut écrire "sœur" pour que ça colorise).
Pareil pour les majuscules non accentuées. Ce serait un gros travail de traitement...
Le plus gênant dans l'histoire, c'est qu'on ne soit pas capables d'écrire toutes les lettres de notre alphabet avec le clavier azerty (alors que c'est possible avec le clavier... japonais, et oui)
si le problème remonte souvent, on pourra envisager des développements sur ce problème.
sylvain
De: "Robert jeannard" <robert....@wanadoo.fr>
Envoyé: Lundi 25 Mai 2020 16:27:47
Objet: Re: [ALEM] WikiColor : problèmes d'alignement
Objet: Re: [ALEM] WikiColor : problèmes d'alignement
--
Pour répondre à ce message, vous pouvez utiliser le bouton "Répondre" de votre messagerie.
Pour écrire sur un nouveau sujet, rendez-vous sur le forum : https://groups.google.com/d/forum/alem-app
---
Vous recevez ce message, car vous êtes abonné au groupe Google Groupes "Apprentissage des Langues Et Multimodalité (ALEM)".
Pour vous désabonner de ce groupe et ne plus recevoir d'e-mails le concernant, envoyez un e-mail à l'adresse alem-app+u...@googlegroups.com.
Pour répondre à ce message, vous pouvez utiliser le bouton "Répondre" de votre messagerie.
Pour écrire sur un nouveau sujet, rendez-vous sur le forum : https://groups.google.com/d/forum/alem-app
---
Vous recevez ce message, car vous êtes abonné au groupe Google Groupes "Apprentissage des Langues Et Multimodalité (ALEM)".
Pour vous désabonner de ce groupe et ne plus recevoir d'e-mails le concernant, envoyez un e-mail à l'adresse alem-app+u...@googlegroups.com.
Cette discussion peut être lue sur le Web à l'adresse https://groups.google.com/d/msgid/alem-app/CAN6_WqatENdw8t%2BpMiS-G25qsaFRFVUJpWf_KkgRSGiNjMnb1A%40mail.gmail.com.
SYLVAIN COULANGE
May 25, 2020, 1:33:35 PM5/25/20
to Apprentissage des Langues Et Multimodalité, ALEM
Hello !
C'est bon, normalement tout fonctionne : j'ai ajouté l'exception pour /wɑ/, les graphies de PronSci dans le Fidel (oix ois oids), les styles pour la bicolorisation wɑ. Enfait on avait rien du tout, c'est dingue je m'en rends compte que maintenant.
Alexandre, pour le problème d'alignement sur la première transcription de "boisage" ( /bwɑzaʒ/ ), c'est que PronSci ne propose pas de graphie "oi" pour /wɑ/. Je l'ajoute ? Y a d'autres mots comme ça ? ou c'est une erreur sur le wiktionnaire ? (il y a beaucoup d'erreurs)
Robert, j'ai modifié l'aligneur pour qu'il garde le tiret et le passe en gris (couleur de la ponctuation). porte-feuille Choisy-le-Roi
Je vois que "peut-être" est considéré comme 2 mots par l'analyseur morphosyntaxique. Je sais pas trop quelles règles il a, mais je ne peux pas agir dessus pour l'instant...
J'ai aussi ajouté une fenêtre pour ajouter des mots dans le dictionnaire depuis la page d'édition du dictionnaire (ça permet d'ajouter des expressions ou des mots composés, que le serveur à tendance à découper en mots et qu'il n'est donc pas possible d'ajouter au dico depuis la page principale).
Voilà. Nouveaux styles = ctrl+F5 pour être sûr de voir les bonnes couleurs.
sylvain
De: "SYLVAIN COULANGE" <sylvain....@univ-grenoble-alpes.fr>
À: "Apprentissage des Langues Et Multimodalité, ALEM" <alem...@googlegroups.com>
À: "Apprentissage des Langues Et Multimodalité, ALEM" <alem...@googlegroups.com>
Envoyé: Lundi 25 Mai 2020 14:17:02
Cette discussion peut être lue sur le Web à l'adresse https://groups.google.com/d/msgid/alem-app/847771087.13485134.1590409022008.JavaMail.zimbra%40univ-grenoble-alpes.fr.
Robert JEANNARD
May 25, 2020, 3:02:15 PM5/25/20
to alem...@googlegroups.com
OK pour les traits d'union.
Une bizarrerie: alors que "Choisy-le-Roi" et "Villeneuve-le-Roi" sont correctement colorisés, ça ne fonctionne pas pour "Marly-le Roi", qui sort en gris. Si je veux ajouter le mot dans le dictionnaire, je reçois le message qu'il y figure déjà.
Robert
Le lun. 25 mai 2020 à 21:33, SYLVAIN COULANGE <sylvain....@univ-grenoble-alpes.fr> a écrit :
Hello !C'est bon, normalement tout fonctionne : j'ai ajouté l'exception pour /wɑ/, les graphies de PronSci dans le Fidel (oix ois oids), les styles pour la bicolorisation wɑ. En fait on avait rien du tout, c'est dingue je m'en rends compte que maintenant.
SYLVAIN COULANGE
May 25, 2020, 5:15:19 PM5/25/20
to Apprentissage des Langues Et Multimodalité, ALEM
Bonsoir Robert,
c'est parce qu'il a été enregistré avec un "r" au lieu de "ʁ" dans la transcription. L'aligneur cherche le phonème /r/ mais ne le trouve pas dans le Fidel du français...
C'est ce que m'a raconté le serveur :
il suffit donc de corriger la transcription du dictionnaire, et ça marchera.
sylvain
De: "Robert jeannard" <robert....@wanadoo.fr>
Envoyé: Lundi 25 Mai 2020 21:01:37
Objet: Re: [ALEM] WikiColor : problèmes d'alignement
--
Pour répondre à ce message, vous pouvez utiliser le bouton "Répondre" de votre messagerie.
Pour écrire sur un nouveau sujet, rendez-vous sur le forum : https://groups.google.com/d/forum/alem-app
---
Vous recevez ce message, car vous êtes abonné au groupe Google Groupes "Apprentissage des Langues Et Multimodalité (ALEM)".
Pour vous désabonner de ce groupe et ne plus recevoir d'e-mails le concernant, envoyez un e-mail à l'adresse alem-app+u...@googlegroups.com.
Pour répondre à ce message, vous pouvez utiliser le bouton "Répondre" de votre messagerie.
Pour écrire sur un nouveau sujet, rendez-vous sur le forum : https://groups.google.com/d/forum/alem-app
---
Vous recevez ce message, car vous êtes abonné au groupe Google Groupes "Apprentissage des Langues Et Multimodalité (ALEM)".
Pour vous désabonner de ce groupe et ne plus recevoir d'e-mails le concernant, envoyez un e-mail à l'adresse alem-app+u...@googlegroups.com.
Cette discussion peut être lue sur le Web à l'adresse https://groups.google.com/d/msgid/alem-app/CAN6_WqZkXLJgqASJPOuFd98Swn_XOmOxUPyGdoRSN_v56dBbPA%40mail.gmail.com.
Robert JEANNARD
May 26, 2020, 6:19:50 AM5/26/20
to alem...@googlegroups.com
Merci, Sylvain, pour l'explication.
J'ai corrigé la transcription dans le dictionnaire et effectivement, la colorisation pour "Marly-le-Roi" fonctionne maintenant.
Ce serveur est vraiment sympa de s'exprimer dans la langue la plus claire du monde ! Je croyais que les messages d'erreurs étaient exprimés dans un codage informatique inaccessible au public.
Je trouve très ergonomiques le lien entre le coloriseur et le dictionnaire, ainsi que la manière de modifier le dictionnaire.
Je viens d'ajouter une dizaine de mots issus de ceux que viennent d'ajouter Larousse et le Robert pour leur édition 2020.
Aussi le mot "coloriseur", que le coloriseur ignorait !
Comment faites-vous pour taper les caractères de l'API ? On trouve sur internet plusieurs claviers virtuels mais je n'ai rien trouvé de satisfaisant. Je fais donc du copié-collé à partir d'une liste proposée par Wikipedia mais j'aimerais avoir un solution plus pratique.
Robert
SYLVAIN COULANGE
May 26, 2020, 6:26:49 AM5/26/20
to Apprentissage des Langues Et Multimodalité, ALEM
Salut Robert,
ça dépend comment on lui appren à s'exprimer ;)
Mais en réalité c'est que des expressions prérentrées qui sont affichées en fonction de ce qui se passe.
Pour taper en API il y a un clavier intégrer à l'application (en bas de l'écran, quand tu es dans une zone de texte de transcription ! Ça ne marche pas chez toi ??
Je te mets une petite vidéo en pièce jointe.
C'est embêtant que tu ne le vois pas, ça veut dire que d'autres utilisateurs sont certainement aussi concernés...
sylvain
De: "Robert jeannard" <robert....@wanadoo.fr>
À: "Apprentissage des Langues Et Multimodalité, ALEM" <alem...@googlegroups.com>
À: "Apprentissage des Langues Et Multimodalité, ALEM" <alem...@googlegroups.com>
Envoyé: Mardi 26 Mai 2020 12:19:11
Objet: Re: [ALEM] WikiColor : problèmes d'alignement
Le mar. 26 mai 2020 à 01:15, SYLVAIN COULANGE <sylvain....@univ-grenoble-alpes.fr> a écrit :
Bonsoir Robert,c'est parce qu'il a été enregistré avec un "r" au lieu de "ʁ" dans la transcription. L'aligneur cherche le phonème /r/ mais ne le trouve pas dans le Fidel du français...C'est ce que m'a raconté le serveur :il suffit donc de corriger la transcription du dictionnaire, et ça marchera.sylvain
--
Pour répondre à ce message, vous pouvez utiliser le bouton "Répondre" de votre messagerie.
Pour écrire sur un nouveau sujet, rendez-vous sur le forum : https://groups.google.com/d/forum/alem-app
---
Vous recevez ce message, car vous êtes abonné au groupe Google Groupes "Apprentissage des Langues Et Multimodalité (ALEM)".
Pour vous désabonner de ce groupe et ne plus recevoir d'e-mails le concernant, envoyez un e-mail à l'adresse alem-app+u...@googlegroups.com.
Pour écrire sur un nouveau sujet, rendez-vous sur le forum : https://groups.google.com/d/forum/alem-app
---
Vous recevez ce message, car vous êtes abonné au groupe Google Groupes "Apprentissage des Langues Et Multimodalité (ALEM)".
Pour vous désabonner de ce groupe et ne plus recevoir d'e-mails le concernant, envoyez un e-mail à l'adresse alem-app+u...@googlegroups.com.
Cette discussion peut être lue sur le Web à l'adresse https://groups.google.com/d/msgid/alem-app/CAN6_WqaaNL9vJePqmOsVMQ2cBot6oWc1eEQX6Hk89i8t84QgbA%40mail.gmail.com.
Reply all
Reply to author
Forward
0 new messages