Skip to first unread message

Robert Jeannard
Jul 26, 2022, 4:18:54 PM7/26/22
to Apprentissage des Langues et Multimodalité (ALeM)
Bonjour à tous et à toutes.
J'utilise très régulièrement l'outil "phonographe" avec deux de mes apprenants, en cours individuels par visio, et j'en suis très satisfait. Tous deux sont avancés à l'écrit et commettent des erreurs de prononciation dues à leur stratégie consistant à prononcer des lettres muettes. Depuis que nous travaillons en désactivant le mode graphies (un grand merci pour cette innovation !), je constate enfin une évolution: voir les icônes seules les oblige à oublier l'écriture et à focaliser sur les sons.
Je viens de constater une dernière innovation bienvenue, que je m'apprêtais à demander: les graphies sont désormais dans une police "bâton" et non plus comme précédemment, dans une police à empattement. C'est en effet plus conforme aux critères d'accessibilité.
J'ai plusieurs souhaits de perfectionnement du Phonographe:
- Sur un écran moyen ou petit, le travail est peu confortable et oblige à utiliser sans cesse l'ascenseur vertical au cours de la saisie car on ne voit pas simultanément l'ensemble des icônes et le champ où apparaît le texte saisi. Pour pallier cet inconvénient, dézoomer (boutons - +) a pour inconvénient de faire apparaître trop petites les icônes par rapport au texte saisi.
Ce problème ergonomique pourrait être résolu de 2 manières:
- augmenter la taille des icônes par rapport au texte saisi;
- permettre l'affichage en mode "plein écran". - [Rappel de ma demande du 18 décembre 2021] Rendre accessible (comme les indices graphique/trait-point d'Alexandre qui s'affichent au survol du curseur) le code API des phonèmes. Ceci serait surtout utile aux enseignants débutant dans l'utilisation de l'outil. [Rappel de ma demande du 18 décembre 2021]
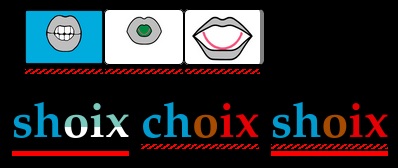
- [Rappel d'une autre demande du 18 décembre 2021] Pour permettre une utilisation du Phonographe en autonomie, il serait utile que l'apprenant reçoive un feedback visuel de ses erreurs phonologiques et orthographiques. La proposition qu'avait faite Sylvain me convient tout à fait: soulignement en hachuré des erreurs phonologiques et en trait plein des erreurs orthographiques:
- Quand on active l'écriture en majuscules, les graphies proposées ne devraient pas être les mêmes qu'avec les minuscules: par exemple si je veux transcrire le phonème [t] en majuscule, 16 graphies sont proposées alors que 3 seulement sont possibles:

- Une rubrique "Aide" donnant accès aux différents tutos présents dans Hypothèses ou ailleurs serait la bienvenue.
- Dans le panneau phono d'Alexandre, l'icône du phonème [ ʁ ] représente , vue de profil, une tête entière alors que seule la bouche et la langue sont utiles.
Au lieu de je préférerais
je préférerais 
- Parmi les graphies proposées pour la voyelle [ ɔ̃ ], il manque "un" pour transcrire "acupuncture".
Un grand merci aux développeurs et à tous les contributeurs de ce magnifique outil.
Robert

SYLVAIN COULANGE
Jul 26, 2022, 5:08:57 PM7/26/22
to Apprentissage des Langues Et Multimodalité, ALEM
Bonsoir Robert, bonsoir à toutes et tous !
Quelle réactivité ! Je viens de mettre à jour le Phonographe tout à l'heure, avec notamment le changement de police que tu as remarqué.
En réalité la mise à jour concerne le mandarin, qui est maintenant disponible sur le Phonographe, mais en version bêta ;) (c'est la première tentative).
Par ailleurs, une grosse mise à jour du Phonographe a eu lieu le weekend dernier, au niveau du player (pour les activités phonologiques). Il y a maintenant une interface auteur qui permet de créer des séries de mots (input audio ou vidéo et on doit pointer ce qu'on entend). Exemple : https://phonographe.alem-app.fr/player/serie-decouverte/play
Nous n'avons pas encore fait les tutoriels, on va s'y mettre dès que possible. Pas besoin de compte utilisateur pour jouer, par contre il en faut un pour créer et éditer les séries. Envoyez moi un mail avec votre nom d'utilisiteur si vous souhaitez que je vous passe en admin !
Quant à tes demandes Robert, tout d'abord merci de les partager. Je ne promets pas de pouvoir tout faire, mais les vacances me permettent de me remettre un peu sur les applis, donc je vais essayer ;)
- Pourrais-tu spécifier un peu plus ton point 1 ? (de quelles icônes parles-tu ? comment imagines-tu le mode plein écran ?)
- Concernant l'affichage des majuscules dans le Fidel, il faudrait proposer un Fidel "majuscules" complet pour que je puisse l'implémenter.
- Pour les points 6 et 7, cela concerne le panneau et le Fidel d'Alexandre, je le laisse réagir.
Pour le reste, c'est clair. Il faut juste que je le fasse. Je m'y mets dès que possible !
Bonne soirée à tous,
Sylvain
De: "Robert Jeannard" <robert....@gmail.com>
À: "Apprentissage des Langues Et Multimodalité, ALEM" <alem...@googlegroups.com>
Envoyé: Mardi 26 Juillet 2022 22:18:54
Objet: [ALeM] Evolution de l'outil "Phonographe"
À: "Apprentissage des Langues Et Multimodalité, ALEM" <alem...@googlegroups.com>
Envoyé: Mardi 26 Juillet 2022 22:18:54
Objet: [ALeM] Evolution de l'outil "Phonographe"
--
Pour répondre à ce message, vous pouvez utiliser le bouton "Répondre" de votre messagerie.
Pour écrire sur un nouveau sujet, rendez-vous sur le forum : https://groups.google.com/d/forum/alem-app
---
Vous recevez ce message, car vous êtes abonné au groupe Google Groupes "Apprentissage des Langues et Multimodalité (ALeM)".
Pour vous désabonner de ce groupe et ne plus recevoir d'e-mails le concernant, envoyez un e-mail à l'adresse alem-app+u...@googlegroups.com.
Cette discussion peut être lue sur le Web à l'adresse https://groups.google.com/d/msgid/alem-app/c5406651-6af2-4339-91aa-db4d34c570e7n%40googlegroups.com.
Pour répondre à ce message, vous pouvez utiliser le bouton "Répondre" de votre messagerie.
Pour écrire sur un nouveau sujet, rendez-vous sur le forum : https://groups.google.com/d/forum/alem-app
---
Vous recevez ce message, car vous êtes abonné au groupe Google Groupes "Apprentissage des Langues et Multimodalité (ALeM)".
Pour vous désabonner de ce groupe et ne plus recevoir d'e-mails le concernant, envoyez un e-mail à l'adresse alem-app+u...@googlegroups.com.
Cette discussion peut être lue sur le Web à l'adresse https://groups.google.com/d/msgid/alem-app/c5406651-6af2-4339-91aa-db4d34c570e7n%40googlegroups.com.

Robert JEANNARD
Jul 27, 2022, 2:03:11 PM7/27/22
to alem...@googlegroups.com
Bonsoir Sylvain et tout le monde.
Merci , Sylvain, pour ton retour.
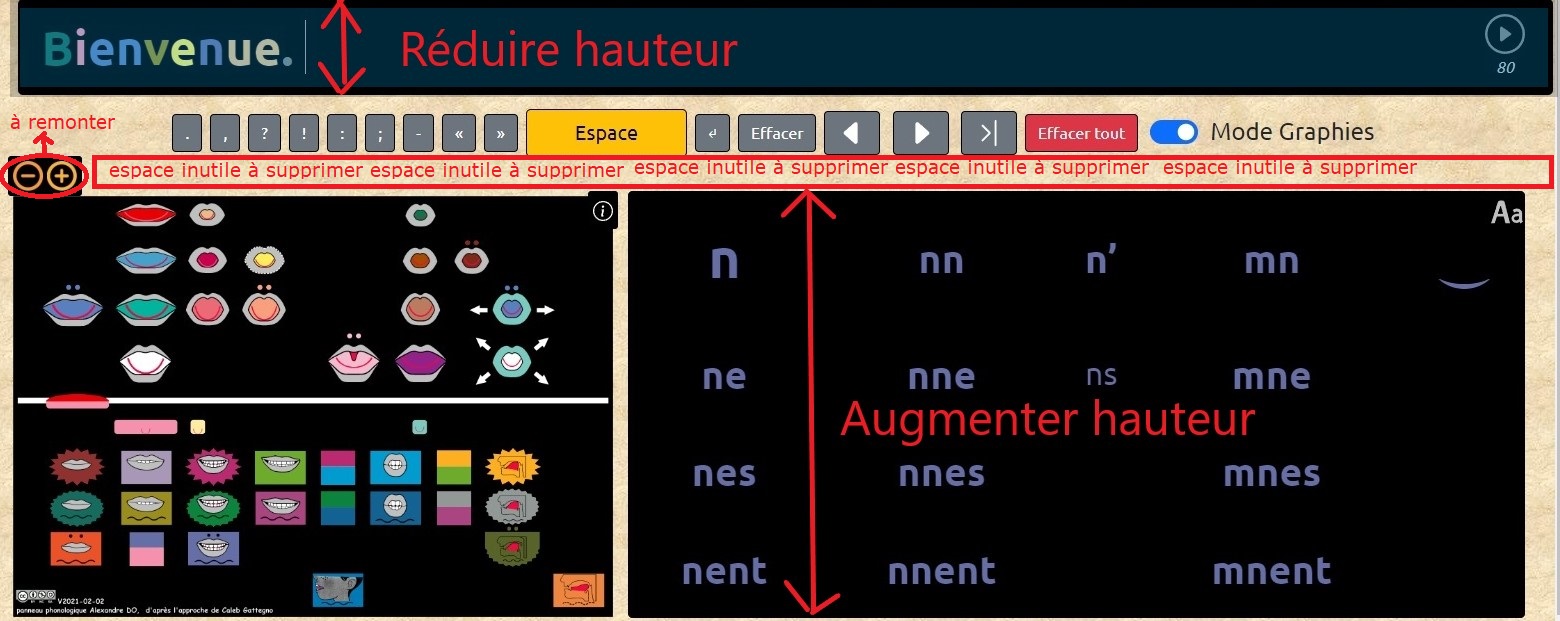
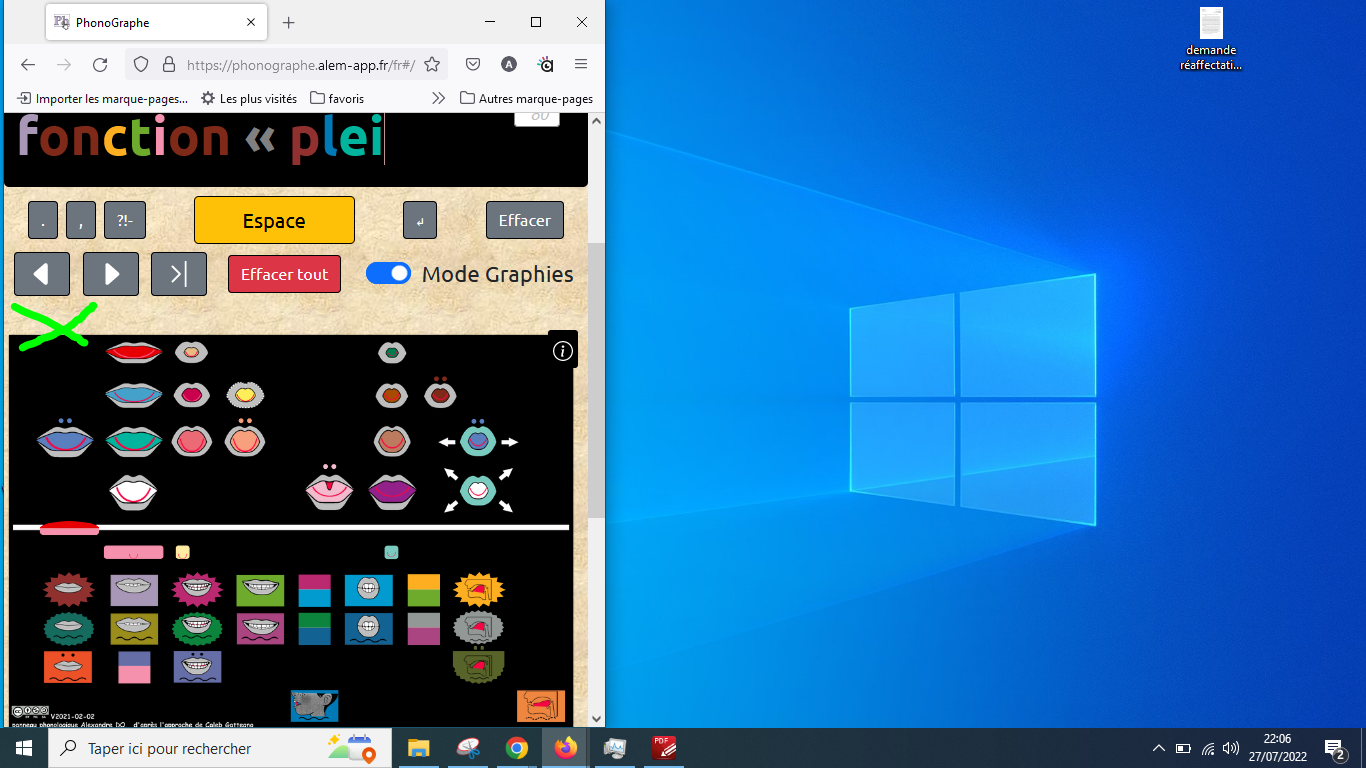
Pour expliciter mon point n° 1, voici des images.
Voici la totalité de mon écran quand j'utilise le Phonographe:
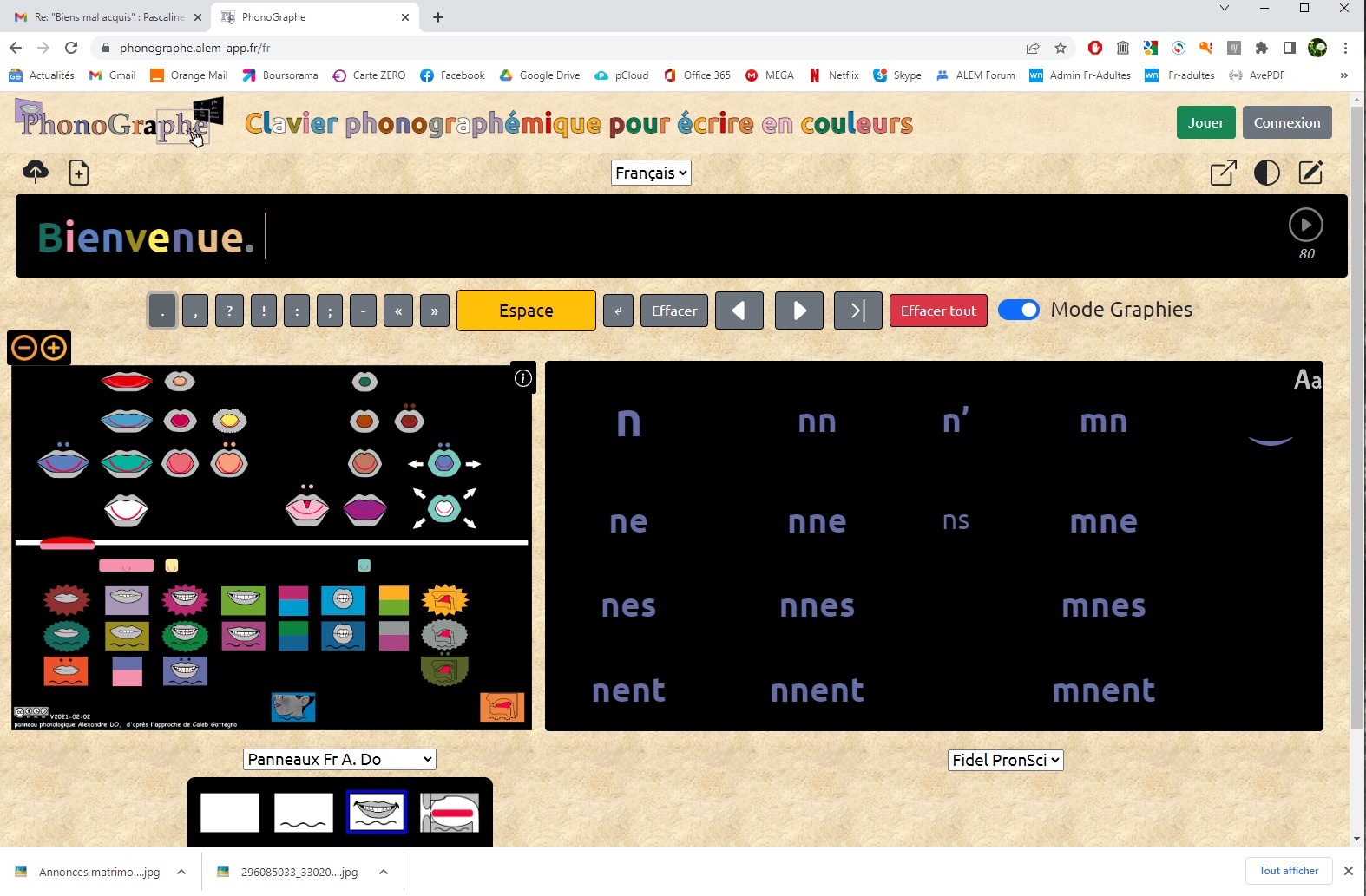
Je souhaiterais pouvoir supprimer de l'affichage la partie supérieure et la partie inférieure, inutiles pour le travail. C'est ce que j'appelle le mode "plein écran".
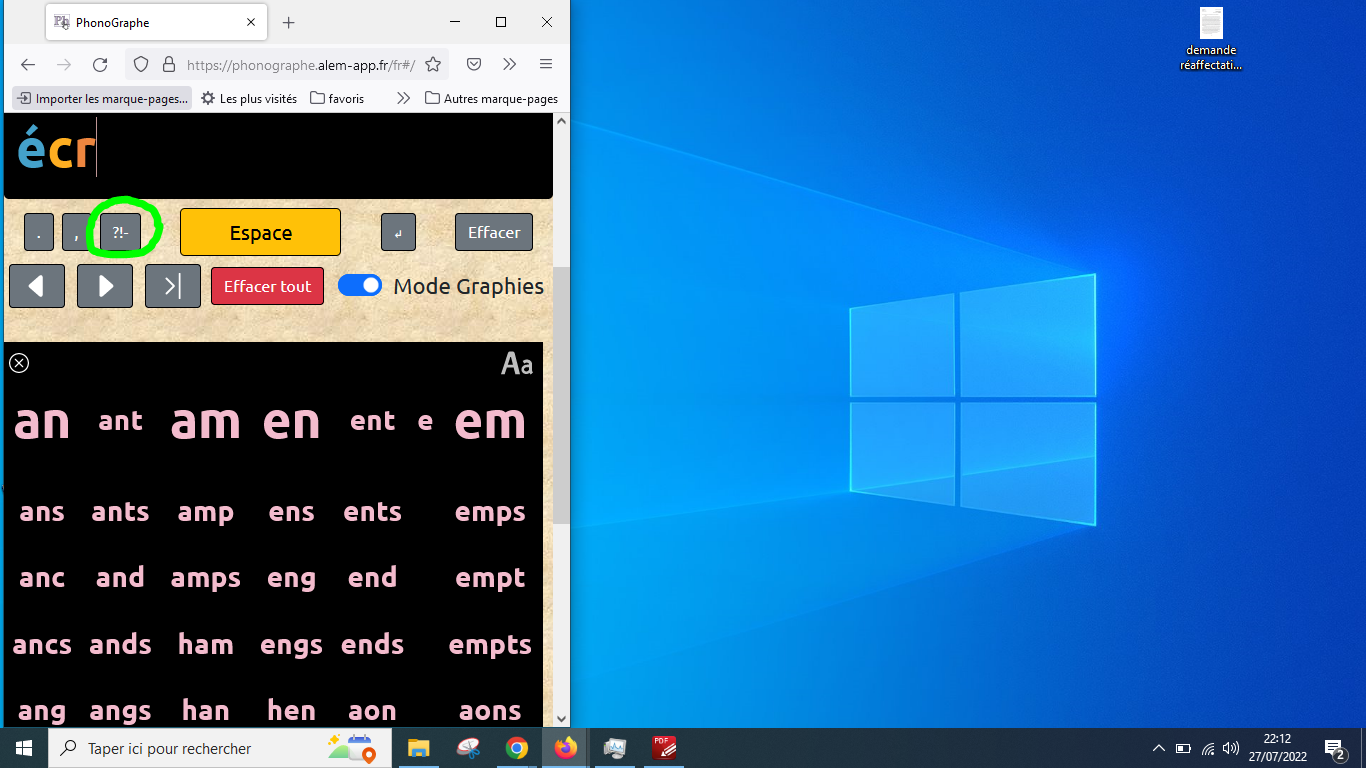
Voici, estompées en bleu, les parties que j'aimerais supprimer:
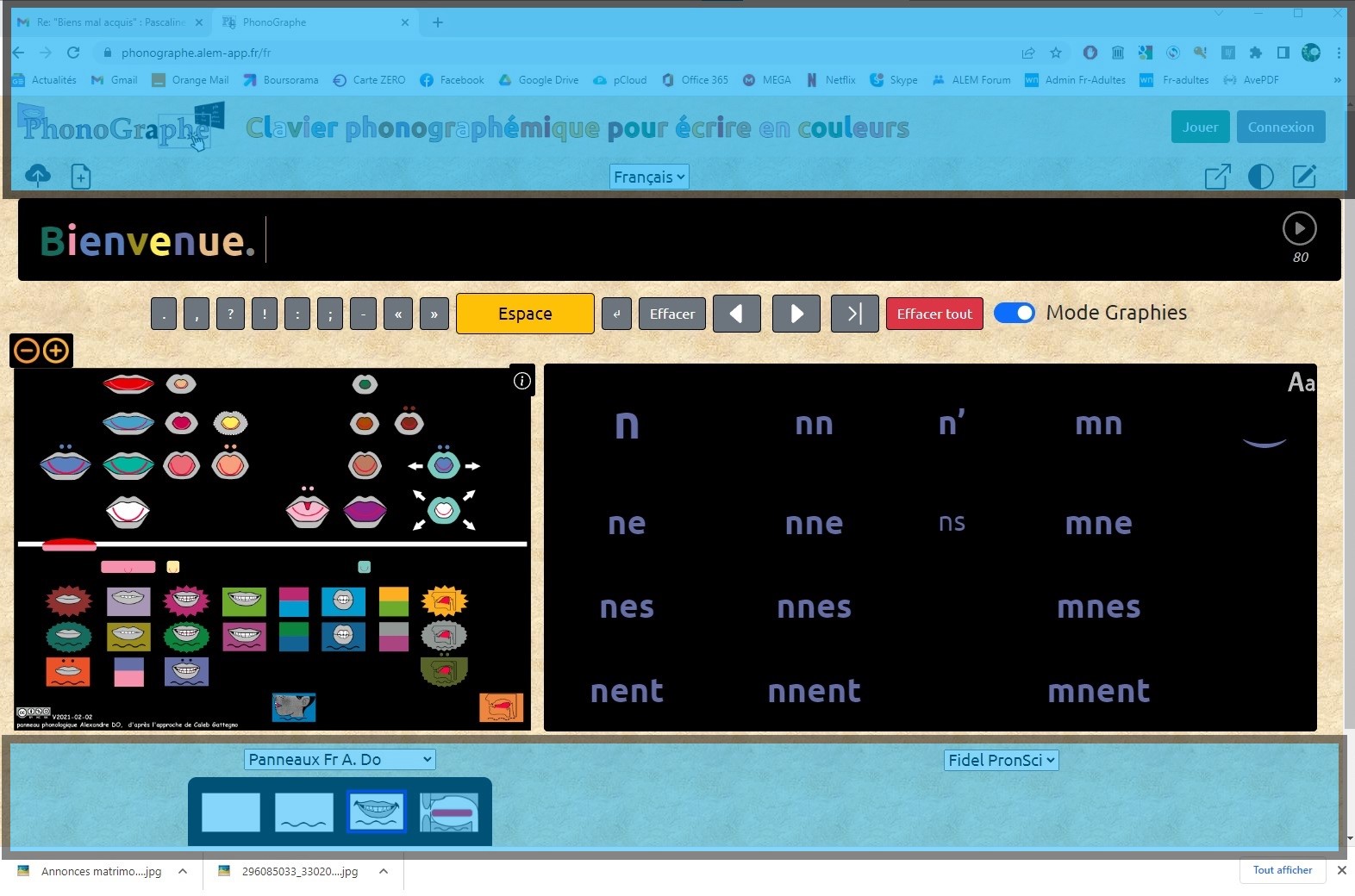
Ce qui donnerait:
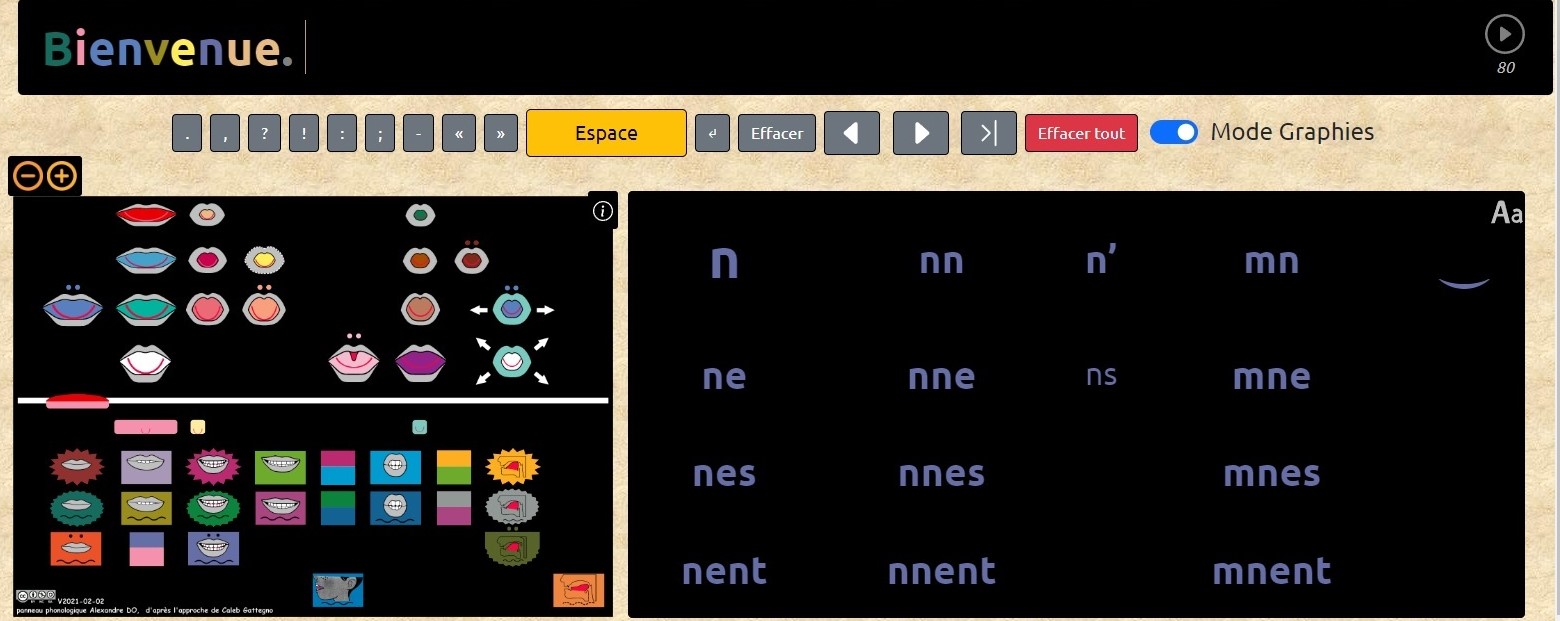
Ensuite, réduire la hauteur de la zone de texte ("Bienvenue") et augmenter la hauteur des 2 panneaux (phono et fidel) de manière que les icônes (dessins des bouches) apparaissent plus gros.
Remonter les boutons + et - de façon à gagner en hauteur la valeur d'une ligne :
Remonter les boutons + et - de façon à gagner en hauteur la valeur d'une ligne :
Concernant mon point n° 4 (le fidel des majuscules), je propose de travailler à une première ébauche de fidel majuscule. En procédant par soustraction à partir du fidel actuel, ça me semble facile.
J'ajoute une 8e et une 9e demandes, oubliées hier:
8) [pour Sylvain] Quand on veut exporter un travail du type

(ce que j'appelle "des icônes"),
ça ne fonctionne pas.
ça ne fonctionne pas.
9) [pour Alexandre] J'aimerais pouvoir supprimer du panneau phono les icônes bicolores, qui perturbent inutilement les apprenants pendant la phase orale de l'apprentissage, avant le contact avec l'écrit. Ces bicolores n'ont d'utilité que pour l'écriture.
Bonne soirée !
Robert

Alexandre DO
Jul 27, 2022, 4:53:41 PM7/27/22
to alem...@googlegroups.com
Bonsoir Robert et tous,
Tout d'abord, merci pour toutes ces questions. Savoir que ces applications servent est intéressant et nous aurions besoin de beaucoup plus de retours d'expériences et de questions pour améliorer l'ergonomie des outils.
Ceci me fait penser qu'il faudrait sans doute faire une visio de partage d'expériences, de questions autour des problèmes rencontrés et de propositions d'évolutions avec tous les utilisateurs de nos applis.
Cependant, je mets ici quelques éléments qui pourraient être une première ébauche de solution concernant l'affichage.
Je parle sous le contrôle de Sylvain mais il me semble que gérer les problèmes d'affichages est une gageure quand on sait que rien ne fonctionne de la même façon selon qu'on travaille sur ordinateur avec des proportions d'écran différentes ou sur tablette ou encore smartphone.
Pour ma part, il est vrai que j'apprécie beaucoup la fonction "responsive" de l'affichage qui permet une adaptation directe du tableau à la largeur disponible. Sur écran tactile, plus de problème de scroll (ascenseur) ou de taille tellement le zoom et le déplacement sont faciles.
Du coup, sur ordinateur, j'ai tendance à réduire la fenêtre à un peu moins qu'un demi écran. Mais les boutons pour la ponctuation ne sont pas "responsive" et prennent beaucoup de place, surtout qu'ils se répartissent sur plusieurs lignes.
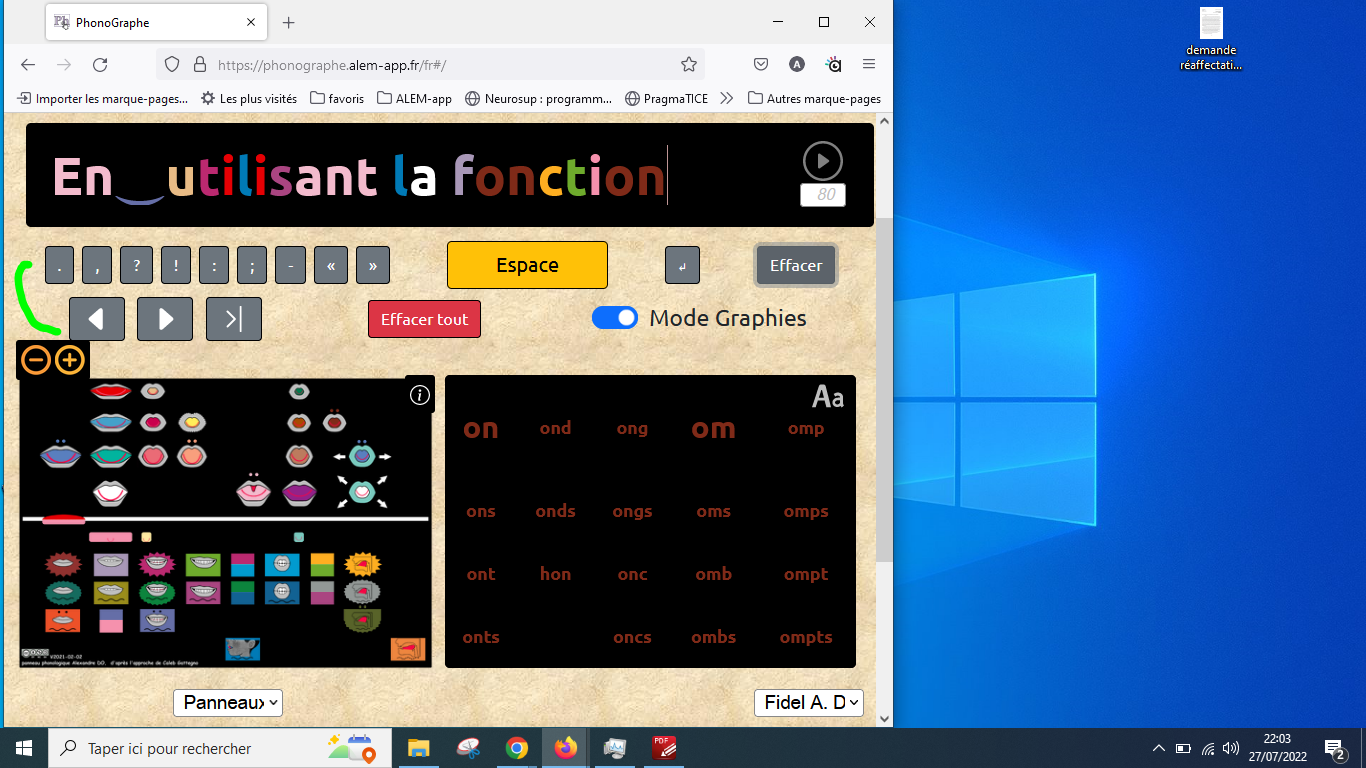
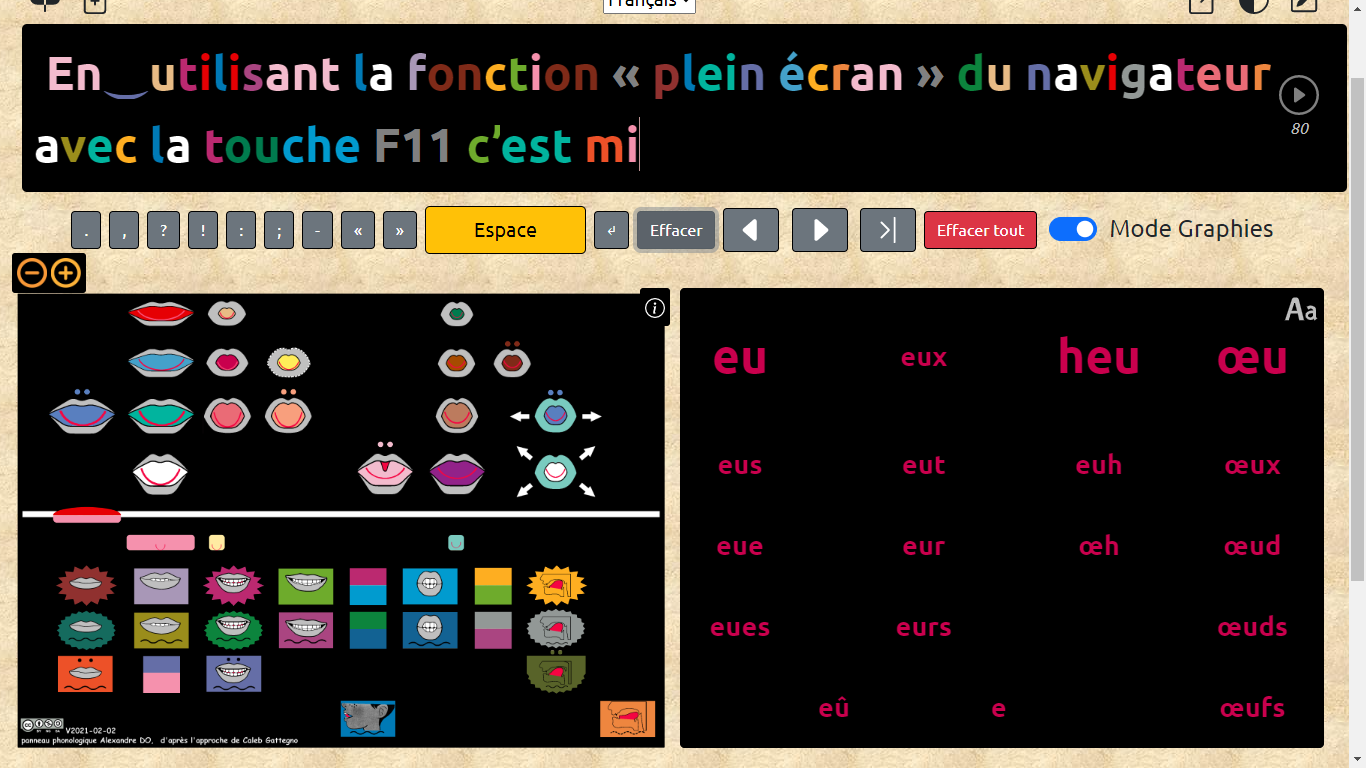
Une autre solution est possible et correspondrait à une solution que tu proposes. C'est celle qui consiste à utiliser la fonction plein écran du navigateur en appuyant sur F11.
Concernant ton point 9), au départ, le phonographe ne servait qu'à écrire en lettres colorées. Maintenant, avec le bouton pour désactiver le mode graphies, il faudrait que des caches masquent les bicolores. Cependant, qui peut le plus peut le moins. Les bicolores provoquent souvent les questions des apprenants mais la surcharge est minime par rapport à celle du Fidel. En faire abstraction n'est pas difficile.
Si on choisit cela, on peut faire la même chose sur le phonodrop et le phonoplayer.
Il y a beaucoup d'autres points dans tes messages et cela méritera certainement de faire une visio en début de semaine prochaine pour pouvoir voir, chercher et discuter en interactions directes avec partage d'écran.
Alexandre
Robert JEANNARD
Jul 28, 2022, 3:15:29 AM7/28/22
to alem...@googlegroups.com
Merci, Alexandre. Ta réponse m'aura au moins appris à utiliser la touche F11 pour obtenir l'affichage plein écran. Jusqu'alors, je ne savais accéder au plein écran qu'à travers un bouton  (la plupart des applications le proposent). Je propose d'ajouter ce bouton au phonographe, je ne dois pas être le seul utilisateur à ignorer les touches F1 à F12.
(la plupart des applications le proposent). Je propose d'ajouter ce bouton au phonographe, je ne dois pas être le seul utilisateur à ignorer les touches F1 à F12.
Cependant, le plein écran laisse, en haut et en bas, des zones inutiles pour le travail:
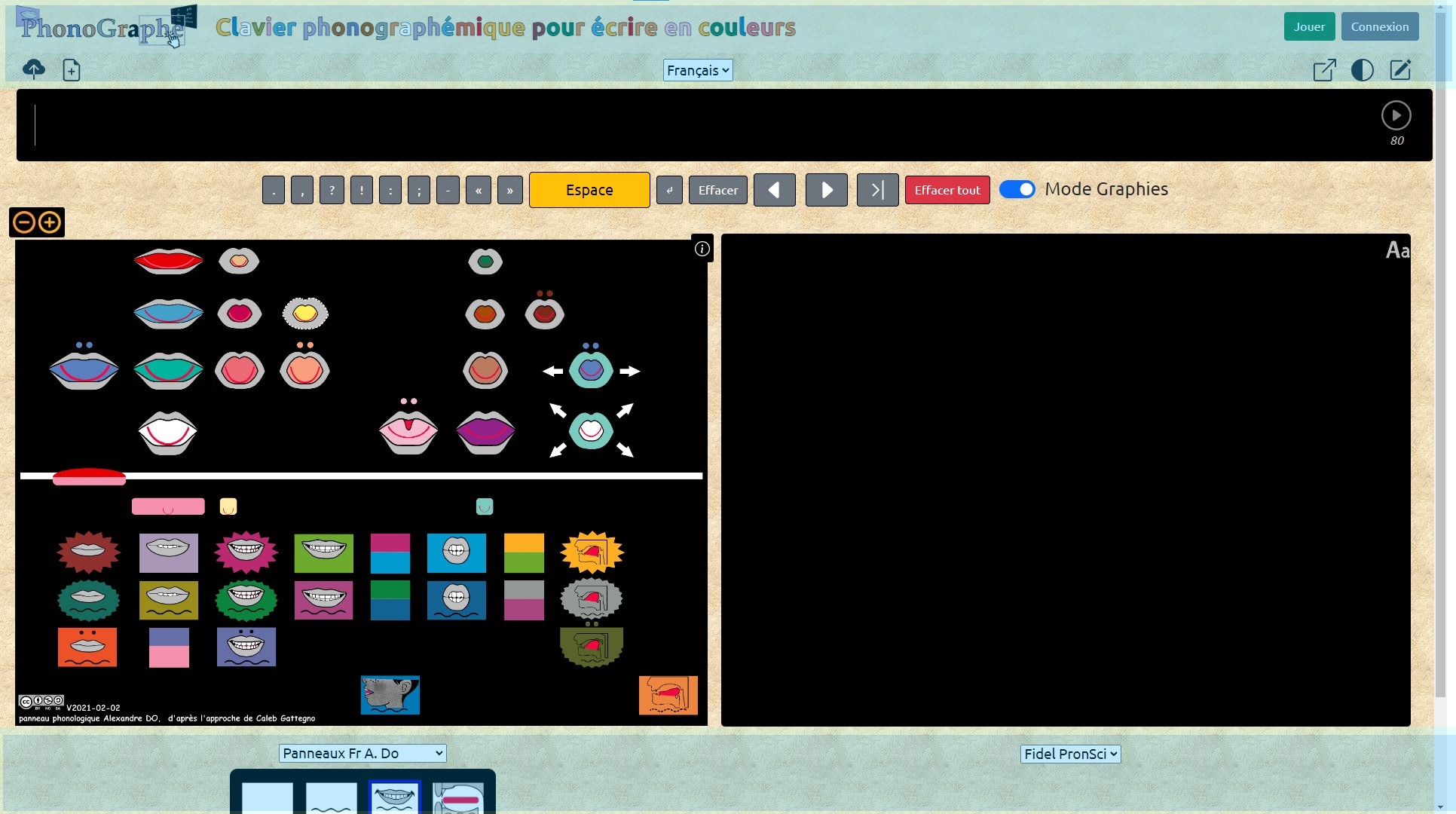
Personnellement, je suis disponible pour une visio quand vous voulez.
Pour réunir le maximum d'utilisateurs, peut-être vaudrait-il mieux lancer un sondage?
A bientôt.
Robert
--
Pour répondre à ce message, vous pouvez utiliser le bouton "Répondre" de votre messagerie.
Pour écrire sur un nouveau sujet, rendez-vous sur le forum : https://groups.google.com/d/forum/alem-app
---
Vous recevez ce message, car vous êtes abonné au groupe Google Groupes "Apprentissage des Langues et Multimodalité (ALeM)".
Pour vous désabonner de ce groupe et ne plus recevoir d'e-mails le concernant, envoyez un e-mail à l'adresse alem-app+u...@googlegroups.com.
Cette discussion peut être lue sur le Web à l'adresse https://groups.google.com/d/msgid/alem-app/CAEO1s87_hGwLDc4kcc39f8rC6Dyg6JfYHPb7wk1521denZbMxw%40mail.gmail.com.
SYLVAIN COULANGE
Aug 2, 2022, 4:49:51 AM8/2/22
to Apprentissage des Langues Et Multimodalité, ALEM
Bonjour à toutes et tous,
J'ai mis en ligne la première version du module de vérification ortho/phonographique du Phonographe.
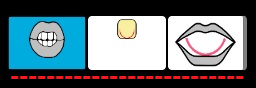
Comme suggéré, si le mot orthographique n'existe pas il est signalé par un soulignement plein ; si le mot phonologique n'existe pas, il est souligné en pointillé.
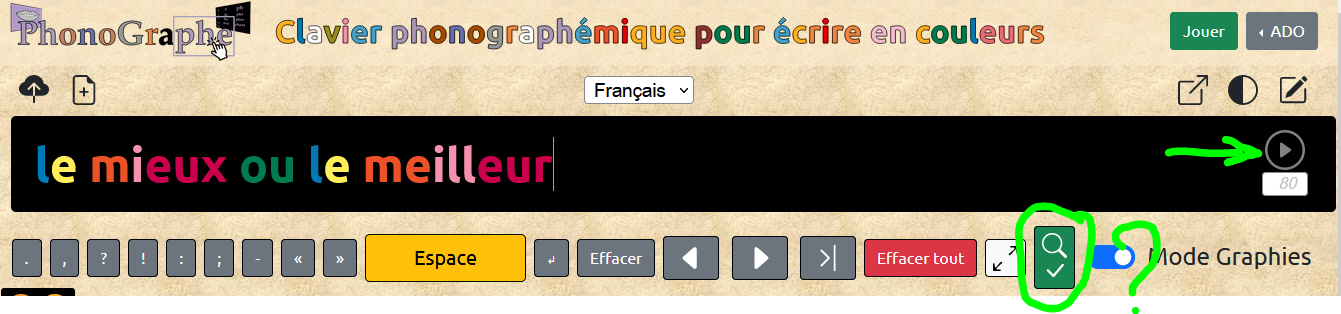
Pour lancer la vérification, il faut appuyer sur  .
.
.J'ai essayé plusieurs méthodes pour optimiser la vitesse de vérification, mais ça reste encore lent, surtout en français (gros dictionnaire). C'est la vérification phonologique qui prend du temps.
La fonction est opérationnelle dans les 3 langues du phonographe.
Modifier le dictionnaire de WikiColor revient à modifier le feedback du PhonoGraphe.
Je ne suis pas encore bien convaincu par ce feedback.
Vaut-il mieux valider ce qui est juste (en vert), ou pointer ce qui est faux ? Ou les deux ? Mais ça ferait lourd.
Toutes vos suggestions sont bienvenues !
sylvain

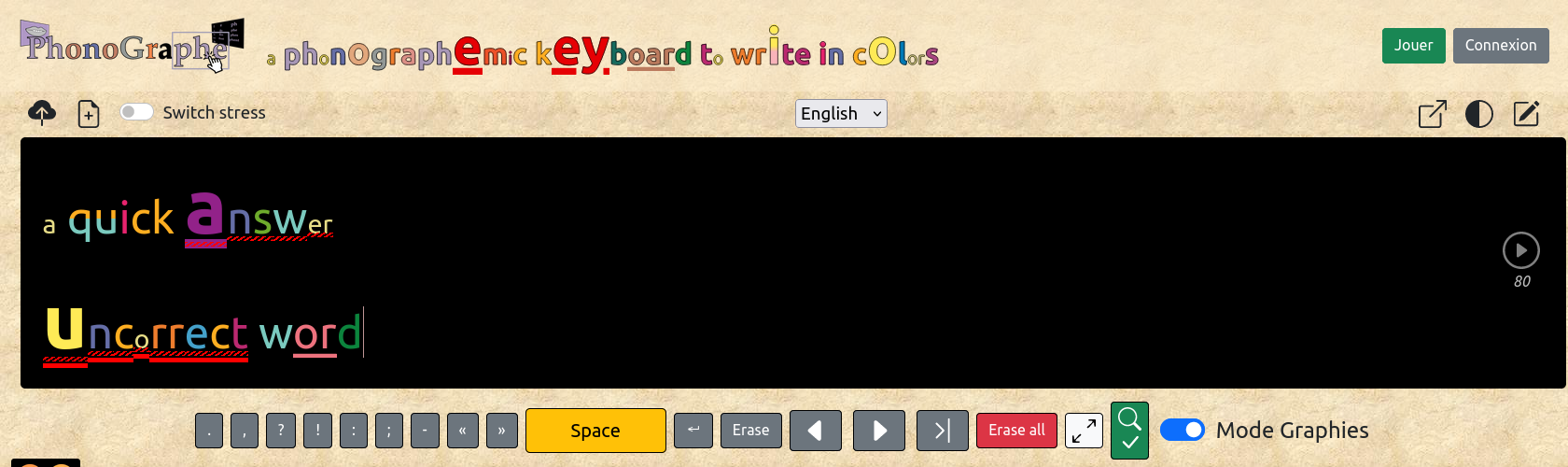
Pour le mandarin, il faut mettre des espaces entre les mots pour que la vérification fonctionne.

De: "Robert jeannard" <robert....@wanadoo.fr>
Envoyé: Jeudi 28 Juillet 2022 09:14:44
Objet: Re: [ALeM] Evolution de l'outil "Phonographe"
Objet: Re: [ALeM] Evolution de l'outil "Phonographe"
Cette discussion peut être lue sur le Web à l'adresse https://groups.google.com/d/msgid/alem-app/CAN6_WqY4-kMZhaHB4pasOuWNVnx0PAR_dB1TMyathYse6NWVKw%40mail.gmail.com.
Robert JEANNARD
Aug 2, 2022, 1:15:54 PM8/2/22
to alem...@googlegroups.com
Merci, Sylvain, pour ces ajouts de fonctionnalités du Phonographe.
J'ai remarqué le bouton "Plein écran" - bien placé.
La vérification est un peu lente mais je trouve que c'est acceptable.
Les soulignements des erreurs sont un peu lourds, je suggère 2 voies pour les alléger:
- Réduire l'épaisseur du trait continu et remplacer le trait hachuré par des pointillés :
 au lieu de
au lieu de 
 au lieu de
au lieu de 
- Au lieu de souligner les mots fautifs, les faire clignoter (je ne sais pas faire)
mais alors on perd la distinction entre les erreurs phonologiques des erreurs orthographiques. Cette distinction est-elle vraiment utile à l'apprenant ?
A la question:
Vaut-il mieux valider ce qui est juste (en vert), ou pointer ce qui est faux ? Ou les deux ? Mais ça ferait lourd.
je réponds sans hésiter: "pointer ce qui est faux", parce que l'apprentissage se fait à partir des erreurs et c'est sur ses erreurs que l'apprenant doit travailler.
Reste le problème des erreurs grammaticales, que ce système de vérification ne détecte pas puisqu'il est conçu pour accepter tout mot (phonologique ou graphique) figurant dans le dictionnaire. Ne serait-il pas possible de faire appel à un correcteur orthographique comme celui des traitements de texte ou des navigateurs, quitte à renoncer à distinguer les types d'erreurs? En existe-t-il de gratuits ?
Tel qu'il est, ce vérificateur me semble un grand pas en avant permettant aux apprenants d'utiliser le Phonographe en autonomie.
A+
Robert
Robert
Alexandre DO
Aug 3, 2022, 2:06:41 PM8/3/22
to Apprentissage des Langues et Multimodalité (ALeM)
Merci Sylvain pour ces nouvelles fonctions.
Concernant la vérification, est-ce qu'il serait possible, lorsqu'on fait une tentative de correction après un 1er FB de l'appli, que seul ce qui a changé soit interrogé ? Est-ce que cela raccourcirait la vérification orthographique ?
Sur le plan esthétique, concernant les erreurs orthographiques, pourquoi pas mettre une vague ondulée comme sur la plupart des traitements de textes. Après, concernant l'épaisseur des traits, je n'ai pas d'arguments.
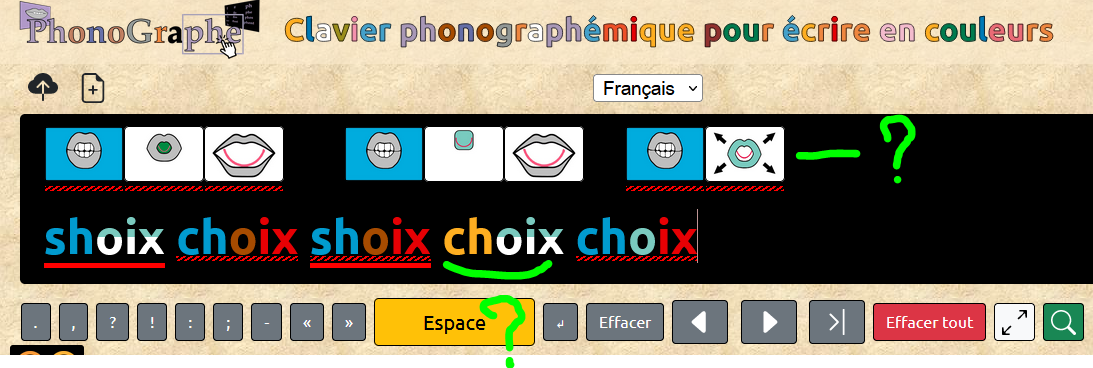
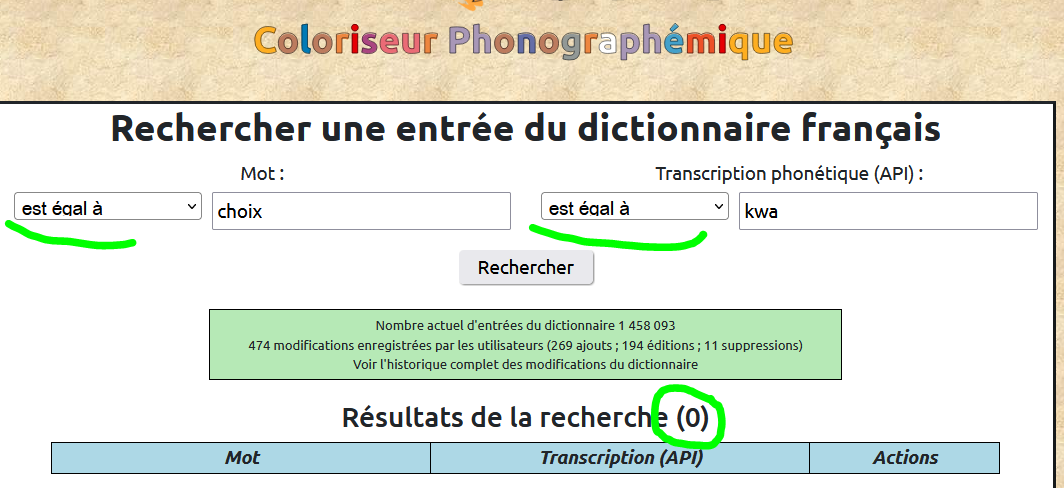
J'adore le double FB ortho et phono quand il y a les deux types d'erreurs pour un même mot. Je ne pourrai pas faire de tests pour le mandarin et l'anglais mais pour le français, il y a 2 problèmes. https://phonographe.alem-app.fr/id-o4fsgf5
Tu as dû procéder à une vérification soit orthographique, soit phonologique mais pas en même temps. Ce n'est pas une condition "ou" mais une condition "et"
Du coup, mon apprenant FLE qui avait fait cette erreur ne trouverait aucun FB pour se corriger. Et le retour vocal ne l'aiderait peut-être pas puisque s'il a fait cette erreur, c'est qu'il avait appris ce mot de manière globale, avec un sens proche de ce qu'il voulait dire, mais en associant la mauvaise prononciation au mot écrit. Alors que pour un francophone, si vous ne voyez pas le problème avec les couleurs, vous l'entendrez avec le retour vocal.
Moi, j'avais trouvé ça génial !!!
Ici la vérification valide la saisie alors que la lecture montre qu'il y a un problème d'association phonologie - orthographe. Mais comme la suite phono existe d'un coté et que l'orthographe est correcte indépendamment de la phono, l'appli ne le voit pas.
J'espère que c'est simple à corriger comme bug.
Alexandre
SYLVAIN COULANGE
Aug 4, 2022, 4:46:25 AM8/4/22
to Apprentissage des Langues Et Multimodalité, ALEM
Cher Robert, je ne t'avais pas encore répondu, désolé !
Très bonne suggestion pour l'épaisseur des lignes, ce sera très simple.
Quant aux erreurs grammaticales, ce n'est pas impossible. Ça ne concerne plus complètement le PhonoGraphe, mais ça se rapproche de GrammaChrome.
La vérification ortho/phonologique qu'on fait avec Wikicolor, on pourrait en faire une similaire au niveau grammatical avec GrammaChrome. Se posera toutefois un problème a priori : l'analyse morphosyntaxique de grammachrome est très classique, elle utilise un modèle de prédiction automatique des catégories grammaticales et des dépendances en fonction du contexte. C'est une techno, comme la reconnaissance de parole, qui a été développée pour travailler à partir de langue "correcte". Ces systèmes ne sont pas habitués à analyser des erreurs, ou de la parole pathologique etc. Tout est question de modèle, et donc de généralisations à partir d'un très gros corpus d'observations. On ne peut donc pas se contenter d'utiliser ces outils tels quels pour évaluer/diagnostiquer la langue de l'apprenant. Tiens, je fais justement ma thèse sur ce sujet, en diagnostic automatique de la prononciation ;)
Bon mais il existe des solutions, il faut juste réfléchir, et ne pas foncer tête biassée sur la technologie existante qui donne tellement l'illusion d'être intelligente. (je dis ça parce que c'est souvent le cas)
Je serais TRÈS intéressé pour discuter avec vous, chers collègues, des possibilités de vérifications grammaticales pour les applis ALeM. Grammachrome est depuis longtemps en attente de nouveautés (notamment des activités guidées type Grammortho, de Maurice Laurent). Le feedback grammatical pourrait être une suite intéressante.
Cher Alexandre,
Oh là là tu es tombé dessus !
Figure-toi que je me suis dit que tu trouverais certainement ce problème. (vérification phono et ortho indépendantes), mais j'ai pas trouvé de cas problématiques dans mes tests.
J'explique :
- Quand on clique sur la petite loupe pour faire la vérification, l'appli découpe la chaine de texte en mots, puis pour chaque mot, envoie une demande à Wikicolor en fournissant l'orthographe et la phonologie encodées.
- Si c'est écrit en bouches (pas d'orthographe), Wikicolor se contente de parcourir le dictionnaire et compare chaque transcriptions API avec la phono de l'utilisateur. Dès qu'il trouve, il s'arrête et renvoie une réponse positive pour la phonologie.
- Si il y a une orthographe et une phono, Wikicolor commence par regarder les mots du dictionnaire ; dès qu'il trouve le même mot que l'utilisateur, il compare la phono avec toutes les transcriptions possibles pour ce mot. Si il trouve une correspondance, la réponse est : ortho=1, phono=1, orthophono=1. Si il ne la trouve pas, il parcourt le dictionnaire pour comparer chaque transcriptions avec la phono de l'utilisateur; et si il en trouve une, la réponse est ortho=1, phono=1, orthophono=0.
- (Ça marche aussi juste avec un mot orthographique)
Donc, on a bien l'information "orthophono" qui indique si cette phono correspond bien à cette orthographe.
Mais le feedback visuel se contente de mettre une ligne type ortho si ortho=1, et ou une ligne type phono si phono=1.
Je me suis demandé ce qu'on voulait faire. Dans le cas de choix, l'orthographe existe et la phono existe, mais pas pour le même mot. Il faudrait un troisième type de feedback dans ce cas ? Comment on l'indique ?
Comment vous imagineriez la chose ?
De: "Alexandre DO" <do.alex...@gmail.com>
Envoyé: Mercredi 3 Août 2022 20:06:41
Objet: Re: [ALeM] Evolution de l'outil "Phonographe"
--
Pour répondre à ce message, vous pouvez utiliser le bouton "Répondre" de votre messagerie.
Pour écrire sur un nouveau sujet, rendez-vous sur le forum : https://groups.google.com/d/forum/alem-app
---
Vous recevez ce message, car vous êtes abonné au groupe Google Groupes "Apprentissage des Langues et Multimodalité (ALeM)".
Pour vous désabonner de ce groupe et ne plus recevoir d'e-mails le concernant, envoyez un e-mail à l'adresse alem-app+u...@googlegroups.com.
Pour répondre à ce message, vous pouvez utiliser le bouton "Répondre" de votre messagerie.
Pour écrire sur un nouveau sujet, rendez-vous sur le forum : https://groups.google.com/d/forum/alem-app
---
Vous recevez ce message, car vous êtes abonné au groupe Google Groupes "Apprentissage des Langues et Multimodalité (ALeM)".
Pour vous désabonner de ce groupe et ne plus recevoir d'e-mails le concernant, envoyez un e-mail à l'adresse alem-app+u...@googlegroups.com.
Cette discussion peut être lue sur le Web à l'adresse https://groups.google.com/d/msgid/alem-app/d10f8136-9e50-4a24-a383-042fc2b067ebn%40googlegroups.com.
Alexandre DO
Aug 4, 2022, 9:56:29 AM8/4/22
to alem...@googlegroups.com
Merci Sylvain pour ces explications.
Concernant le problème que j'ai fait remonter, je ne suis pas tombé dessus. Je l'ai cherché car j'ai l'habitude de voir des élèves qui font ce genre d'erreur.
Je reprends tous les cas possibles dans ce tableau (1 quand l'entrée est correcte ; 0 qd elle est incorrecte)
| orthographe | phonologie | orthophono | FB | |
| a | 0 | 0 | 0 | err ortho et err phono |
| b | 0 | 1 | 0 | err ortho |
| c | 1 | 0 | 0 | err phono |
| d | 1 | 1 | 0 | ? |
| e | 1 | 1 | 1 | rien |
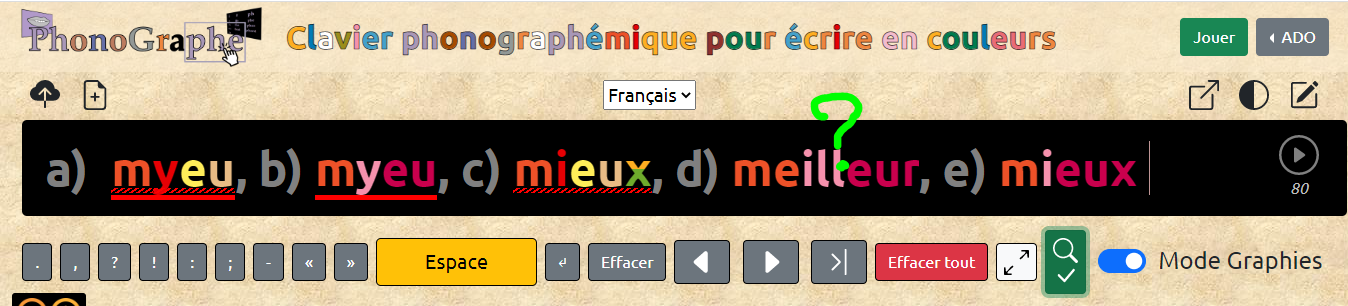
Ce qui nous préoccupe ici, c'est de savoir quel feedback on donne pour une entrée de type d).
Ici, je demanderai "oralement" à l'utilisateur de choisir entre 2 solutions qui existent :
a) 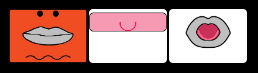 ou
ou 
Ce qui serait bien, c'est que l'utilisateur puisse entendre le retour vocal :
- de la transcription phono a) puis avoir accès au dictionnaire ou
- de la transcription orthographique b) avec une voix de synthèse classique qui lit de l'orthographe.
Alexandre DO
Aug 5, 2022, 2:03:38 PM8/5/22
to alem...@googlegroups.com
Bonsoir à tous,
je rajoute ici un petit problème pour Sylvain.
Je viens de tester le vérificateur phono/ortho sur une vieille page d'un message. J'ai été surpris du retour d'erreur phono pour vocal, problèmes et phonographe. C'est un problème de variation. J'avais mis des /o/ partout au lieu de /ɔ/ comme le précise le dictionnaire de wikicolor.
J'ai alors testé la réactivité de la mise à jour du dictionnaire et je viens de constater que si on met des points pour la segmentation syllabique dans la transcription phonologique du dictionnaire, le retour dans le phonographe n'est pas bon.
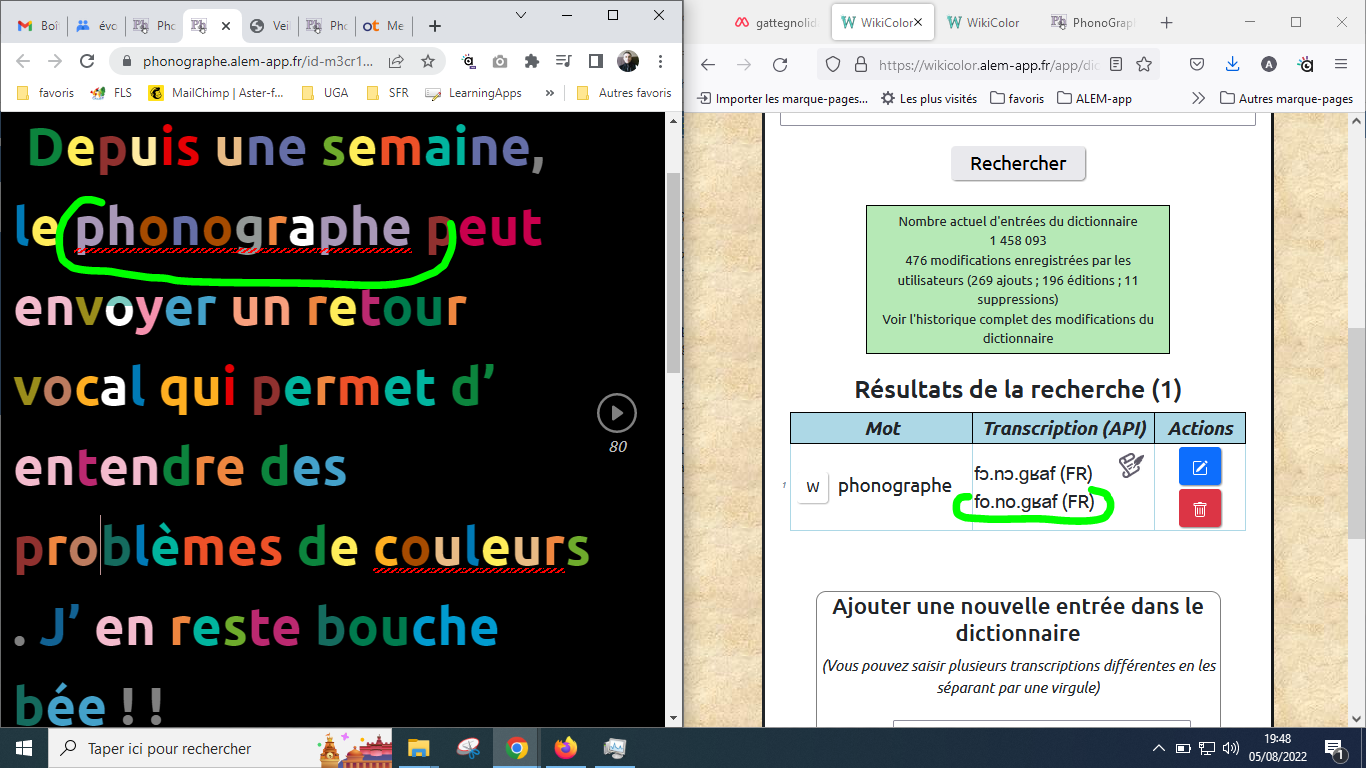
Si j'enlève les points dans le dictionnaire, alors ça marche :
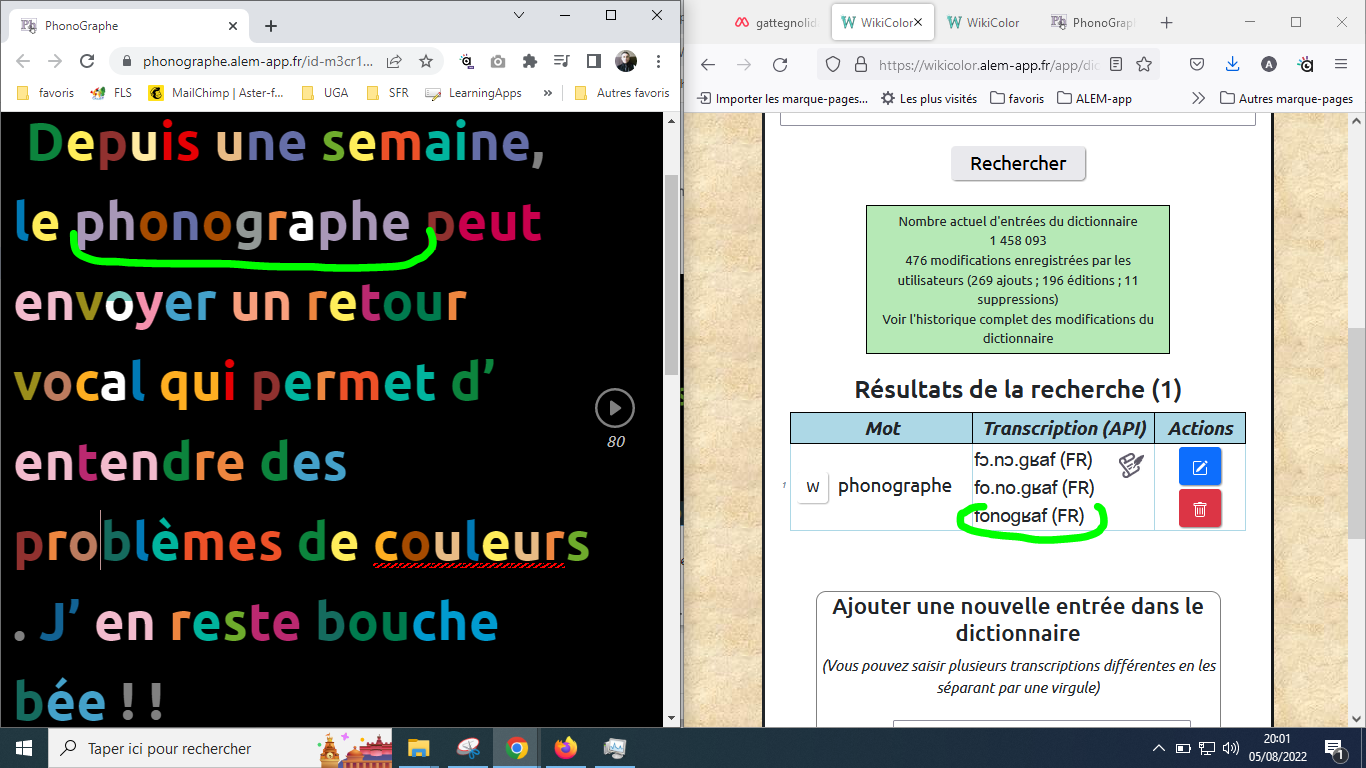
Alexandre
SYLVAIN COULANGE
Aug 6, 2022, 1:59:15 AM8/6/22
to alem...@googlegroups.com
Ah oui, ces points dans les transcriptions du dictionnaire, qui sont parfois indiqués et parfois pas, ils me compliquent bien la vie.
Initialement, lors de la vérification, wikicolor comparait chaque transcription en supprimant les points (qui ne servent à rien nulle part actuellement), mais pour optimiser la vitesse, j'ai fait en sorte qu'au lancement de l'application, le dictionnaire est mis en mémoire sans ces points, comme ça il n'y a plus de suppression a faire lors de la comparaison. L'idée est de simplifier au maximum l'algorithme pour qu'il soit le plus rapide possible lors du parcours des 1 400 000 entrées du dictionnaire.
Je n'ai simplement pas pensé à enlever les points lorsqu'un utilisateur ajoute une nouvelle transcription ! Je fais ça tout de suite.
Sylvain
----- Mail d’origine -----
De: Alexandre DO <do.alex...@gmail.com>
À: alem...@googlegroups.com
Envoyé: Fri, 05 Aug 2022 20:02:55 +0200 (CEST)
> - de la transcription phono a) puis avoir accès au dictionnaire
> ou
> - de la transcription orthographique b) avec une voix de synthèse
Initialement, lors de la vérification, wikicolor comparait chaque transcription en supprimant les points (qui ne servent à rien nulle part actuellement), mais pour optimiser la vitesse, j'ai fait en sorte qu'au lancement de l'application, le dictionnaire est mis en mémoire sans ces points, comme ça il n'y a plus de suppression a faire lors de la comparaison. L'idée est de simplifier au maximum l'algorithme pour qu'il soit le plus rapide possible lors du parcours des 1 400 000 entrées du dictionnaire.
Je n'ai simplement pas pensé à enlever les points lorsqu'un utilisateur ajoute une nouvelle transcription ! Je fais ça tout de suite.
Sylvain
----- Mail d’origine -----
De: Alexandre DO <do.alex...@gmail.com>
À: alem...@googlegroups.com
Envoyé: Fri, 05 Aug 2022 20:02:55 +0200 (CEST)
Objet: Re: [ALeM] Evolution de l'outil "Phonographe"
> ou
> - de la transcription orthographique b) avec une voix de synthèse
> classique qui lit de l'orthographe.
>
> Ensuite, il devrait retranscrire en couleurs la bonne solution.
>
>
> Ensuite, il devrait retranscrire en couleurs la bonne solution.
>
--
Pour répondre à ce message, vous pouvez utiliser le bouton "Répondre" de votre messagerie.
Pour écrire sur un nouveau sujet, rendez-vous sur le forum : https://groups.google.com/d/forum/alem-app
---
Vous recevez ce message, car vous êtes abonné au groupe Google Groupes Apprentissage des Langues et Multimodalité (ALeM).
Pour vous désabonner de ce groupe et ne plus recevoir d'e-mails le concernant, envoyez un e-mail à l'adresse alem-app+u...@googlegroups.com.
Cette discussion peut être lue sur le Web à l'adresse https://groups.google.com/d/msgid/alem-app/CAEO1s87ywwgKK7pxPQF8hm8xOwFK6CLB_r7osp2q8%3DwTGTfNKg%40mail.gmail.com.
Pour répondre à ce message, vous pouvez utiliser le bouton "Répondre" de votre messagerie.
Pour écrire sur un nouveau sujet, rendez-vous sur le forum : https://groups.google.com/d/forum/alem-app
---
Vous recevez ce message, car vous êtes abonné au groupe Google Groupes Apprentissage des Langues et Multimodalité (ALeM).
Pour vous désabonner de ce groupe et ne plus recevoir d'e-mails le concernant, envoyez un e-mail à l'adresse alem-app+u...@googlegroups.com.
SYLVAIN COULANGE
Aug 6, 2022, 2:46:27 AM8/6/22
to Apprentissage des Langues Et Multimodalité, ALEM
C'est tout bon.
N'hésitez pas à contribuer à l'enrichissement des dictionnaires ! Ils sont faits pour ça :)
De: "SYLVAIN COULANGE" <sylvain....@univ-grenoble-alpes.fr>
Envoyé: Samedi 6 Août 2022 07:59:13
Cette discussion peut être lue sur le Web à l'adresse https://groups.google.com/d/msgid/alem-app/41429373.3026563.1659765553649.JavaMail.zimbra%40univ-grenoble-alpes.fr.
SYLVAIN COULANGE
Aug 6, 2022, 10:05:26 AM8/6/22
to Apprentissage des Langues Et Multimodalité, ALEM
Bonjour à tous,
je suis en train de revoir le feedback du Phonographe.
Je suis pas encore bien satisfait, mais pour l'instant voilà à quoi ça ressemble :

AVANT :
Si l'orthographe n'est pas attestée : ligne pleine
Si la phono n'est pas attestée : ligne pointillée
Problème : quand l'orthographe et la phono sont attestée mais pas pour le même mot ("meilleur" prononcé "mieux")
APRÈS :
Ligne pleine rouge : orthographe non attestée
Ligne traits rouge : phonologie non attestée
Ligne pointillée orange : phonologie attestée mais pas pour ce mot orthographique
Ça conviendrait mieux ?
sylvain
De: "Alexandre DO" <do.alex...@gmail.com>
À: "Apprentissage des Langues Et Multimodalité, ALEM" <alem...@googlegroups.com>
À: "Apprentissage des Langues Et Multimodalité, ALEM" <alem...@googlegroups.com>
Envoyé: Jeudi 4 Août 2022 15:55:50
Objet: Re: [ALeM] Evolution de l'outil "Phonographe"
--
Pour répondre à ce message, vous pouvez utiliser le bouton "Répondre" de votre messagerie.
Pour écrire sur un nouveau sujet, rendez-vous sur le forum : https://groups.google.com/d/forum/alem-app
---
Vous recevez ce message, car vous êtes abonné au groupe Google Groupes "Apprentissage des Langues et Multimodalité (ALeM)".
Pour vous désabonner de ce groupe et ne plus recevoir d'e-mails le concernant, envoyez un e-mail à l'adresse alem-app+u...@googlegroups.com.
Pour répondre à ce message, vous pouvez utiliser le bouton "Répondre" de votre messagerie.
Pour écrire sur un nouveau sujet, rendez-vous sur le forum : https://groups.google.com/d/forum/alem-app
---
Vous recevez ce message, car vous êtes abonné au groupe Google Groupes "Apprentissage des Langues et Multimodalité (ALeM)".
Pour vous désabonner de ce groupe et ne plus recevoir d'e-mails le concernant, envoyez un e-mail à l'adresse alem-app+u...@googlegroups.com.
Cette discussion peut être lue sur le Web à l'adresse https://groups.google.com/d/msgid/alem-app/CAEO1s87YKYGDtdJfMqcKuwMRxJmEu3ygg3YNjFUXY6eGhB8qZQ%40mail.gmail.com.
Alexandre DO
Aug 6, 2022, 1:21:36 PM8/6/22
to alem...@googlegroups.com
Bonjour Sylvain,
Je ne vois pas trop ce qu'apporte le pointillé orange dans le cas b). Quand il y a un trait, on imagine qu'il y a un problème.
Hors dans le cas b), le seul pb est au niveau orthographique car la phono existe. On ne peut pas rapprocher visuellement le cas b avec le d.
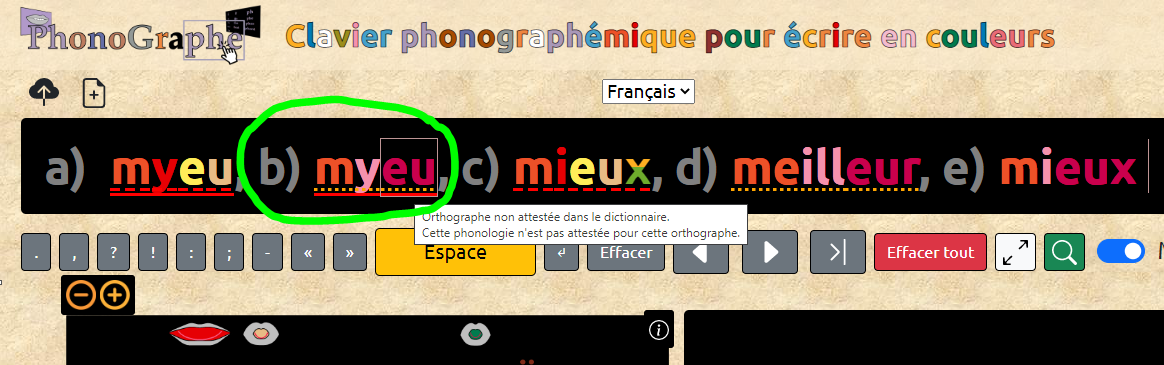
Autre chose qui me dérange, c'est la formulation dans les infos-bulles qui me parait trop compliquée.
Je mettrai seulement : "problème d'orthographe", "problème de phonologie",
et pour le cas d) (qui te fait soucis !) "orthographe et phonologie existantes mais pas pour le même mot".
Si quelqu'un a une autre formulation plus simple pour les info-bulles, ça me va.
Avis aux abonnés du forum pour qu'ils s'expriment sur ce point.
Autres avis à donner : cette fonctionnalité vous semble-t-elle intéressante ?
Alexandre
Cette discussion peut être lue sur le Web à l'adresse https://groups.google.com/d/msgid/alem-app/825275400.3053411.1659794723741.JavaMail.zimbra%40univ-grenoble-alpes.fr.
SYLVAIN COULANGE
Aug 7, 2022, 3:51:42 AM8/7/22
to Apprentissage des Langues Et Multimodalité, ALEM
Ah très juste, pas trop d'intérêt de faire un retour sur la phonographie si la graphie n'est pas attestée.
J'ai fait les changements.

J'aimerais bien trouver un moyen pour optimiser la vitesse de vérification. Vérifier que ce qui a changé est une option intéressante, je vais creuser. Mais sinon je me demande pourquoi c'est si long.
Peut-être faire une requête avec la liste des mots, plutôt qu'une requête indépendante par mot... je vais voir.
sylvain
De: "Alexandre DO" <do.alex...@gmail.com>
À: "Apprentissage des Langues Et Multimodalité, ALEM" <alem...@googlegroups.com>
À: "Apprentissage des Langues Et Multimodalité, ALEM" <alem...@googlegroups.com>
Envoyé: Samedi 6 Août 2022 19:20:55
Cette discussion peut être lue sur le Web à l'adresse https://groups.google.com/d/msgid/alem-app/CAEO1s86_5e5BJusm3hZ5X7ztWShCUK6b_jPfSCWDQXbZbdQAnA%40mail.gmail.com.
Reply all
Reply to author
Forward
0 new messages