Trying to understand a sudden drop in throughput with Akka IO

Soumya Simanta
I'm asking this question here because Rediscala uses Akka IO. So maybe someone here could provide some insight into what's going on.
I'm trying to run a simple test by putting 1 million keys-values into Redis (running on the same machine). For 100,000 keys it is really fast.
However, the performance degrades a lot when I bump the number of keys to 1 million. The max. heap space is 12G and I'm running this on a Macbook pro.
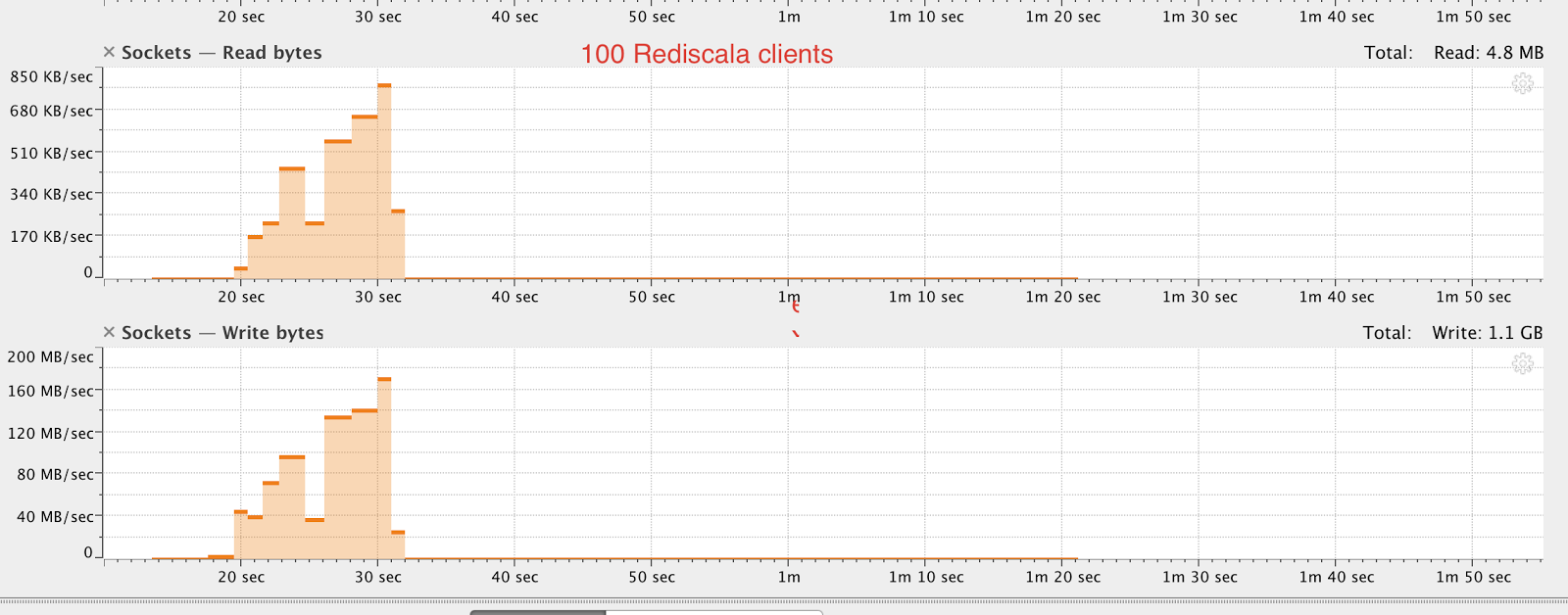
As you can see the network write drops significantly after sometime. Not sure what's going on here. Any help would be really appreciated.
NOTE: The time measurements are just to get an estimate. I plan to use a micro benchmark library for my final measurements.
I'm using the following versions:
"com.etaty.rediscala" %% "rediscala" % "1.4.0"
scalaVersion := "2.11.4"
Here is the code.
package redisbenchmark
import akka.util.ByteString
import scala.concurrent.{Future}
import redis.RedisClient
import java.util.UUID
object RedisLocalPerf {
def main(args:Array[String]) = {
implicit val akkaSystem = akka.actor.ActorSystem()
var numberRuns = 1000 //default to 100
var size = 1
if( args.length == 1 )
numberRuns = Integer.parseInt(args(0))
val s = """How to explain ZeroMQ? Some of us start by saying all the wonderful things it does. It's sockets on steroids. It's like mailboxes with routing. It's fast! Others try to share their moment of enlightenment, that zap-pow-kaboom satori paradigm-shift moment when it all became obvious. Things just become simpler. Complexity goes away. It opens the mind. Others try to explain by comparison. It's smaller, simpler, but still looks familiar. Personally, I like to remember why we made ZeroMQ at all, because that's most likely where you, the reader, still are today.How to explain ZeroMQ? Some of us start by saying all the wonderful things it does. It's sockets on steroids. It's like mailboxes with routing. It's fast! Others try to share their moment of enlightenment, that zap-pow-kaboom satori paradigm-shift moment when it all became obvious. Things just become simpler. Complexity goes away. It opens the mind. Others try to explain by comparison. It's smaller, simpler, but still looks familiar. Personally, I like to remember why we made ZeroMQ at all, because that's most likely where"""
val msgSize = s.getBytes.size
val redis = RedisClient()
implicit val ec = redis.executionContext
val futurePong = redis.ping()
println("Ping sent!")
futurePong.map(pong => {
println(s"Redis replied with a $pong")
})
val random = UUID.randomUUID().toString
val start = System.currentTimeMillis()
val result: Seq[Future[Boolean]] = for {i <- 1 to numberRuns} yield {
redis.set(random + i.toString, ByteString(s))
}
val res: Future[List[Boolean]] = Future.sequence(result.toList)
val end = System.currentTimeMillis()
val diff = (end - start)
println(s"for msgSize $msgSize and numOfRuns [$numberRuns] time is $diff ms ")
akkaSystem.shutdown()
}
}


Akka Team
val res: Future[List[Boolean]] = Future.sequence(result.toList) val end = System.currentTimeMillis() val diff = (end - start) println(s"for msgSize $msgSize and numOfRuns [$numberRuns] time is $diff ms ") akkaSystem.shutdown()}
--}
>>>>>>>>>> Read the docs: http://akka.io/docs/
>>>>>>>>>> Check the FAQ: http://doc.akka.io/docs/akka/current/additional/faq.html
>>>>>>>>>> Search the archives: https://groups.google.com/group/akka-user
---
You received this message because you are subscribed to the Google Groups "Akka User List" group.
To unsubscribe from this group and stop receiving emails from it, send an email to akka-user+...@googlegroups.com.
To post to this group, send email to akka...@googlegroups.com.
Visit this group at http://groups.google.com/group/akka-user.
For more options, visit https://groups.google.com/d/optout.
--
Soumya Simanta
I suspected the thread scheduler to be the limitation.
Or the way Future.sequence works.
If you can isolate a test that scale linearly up to 1M of futures, I would be interested to see it. By replacing akka-io with another java.nio library (xnio) I was able to pass the 1M req (at the speed of around 500k req/s)"
https://github.com/etaty/rediscala/issues/67
If replacing akka-io with java.nio resolves this then either akka-io is not used correctly in Rediscala OR it is a fundamental limitation of akka-io.
On Saturday, December 20, 2014 6:35:22 AM UTC-5, Akka Team wrote:
Hi,My personal guess is that since you don't obey any backpressure when you start flooding the redis client with requests you end up with a lot of queued messages and probably high GC pressure. You can easily test this by looking at the memory profile of your test.
On Sat, Dec 20, 2014 at 6:55 AM, Soumya Simanta <soumya....@gmail.com> wrote:val res: Future[List[Boolean]] = Future.sequence(result.toList) val end = System.currentTimeMillis() val diff = (end - start) println(s"for msgSize $msgSize and numOfRuns [$numberRuns] time is $diff ms ") akkaSystem.shutdown()}
What does the above code intend to measure? Didn't you want to actually wait on the "res" future?
Soumya Simanta

Soumya Simanta

Akka Team
--
>>>>>>>>>> Read the docs: http://akka.io/docs/
>>>>>>>>>> Check the FAQ: http://doc.akka.io/docs/akka/current/additional/faq.html
>>>>>>>>>> Search the archives: https://groups.google.com/group/akka-user
---
You received this message because you are subscribed to the Google Groups "Akka User List" group.
To unsubscribe from this group and stop receiving emails from it, send an email to akka-user+...@googlegroups.com.
To post to this group, send email to akka...@googlegroups.com.
Visit this group at http://groups.google.com/group/akka-user.
For more options, visit https://groups.google.com/d/optout.
Soumya Simanta
Darwin 14.0.0 Darwin Kernel Version 14.0.0: Fri Sep 19 00:26:44 PDT 2014; root:xnu-2782.1.97~2/RELEASE_X86_64 x86_64
Processor Name: Intel Core i7
Processor Speed: 2.6 GHz
Number of Processors: 1
Total Number of Cores: 4
L2 Cache (per Core): 256 KB
L3 Cache: 6 MB
Memory: 16 GB



Soumya Simanta
Akka Team
Endre,Thank you for taking the time to explain everything. It was really helpful not only in understanding the streams basics but also to create a better/faster version of what I'm trying to do.Before I go any further I want to say that I love Akka streams and it is going to be a useful API for a lot of my future work. Thanks to the Akka team.I tweaked both the dispatchers settings as well as the type of dispatcher used by default dispatcher. The program still ends up taking a good deal of my CPU (NOTE: The screenshot below is for FJP and not a ThreadpoolExecutor but I see similar usage with TPE).
The memory footprint is always under control as excepted. I gave 12G of heap space to the JVM.The frequency of young generation GC depends on the MaterializerSettings buffer sizes. I've not tweaked the GC yet. Do you think that can make a difference ?
BTW, does the a size of 64 mean that there will be 64 items in each buffer in the pipeline. I bumped it to 512 and saw an increase in throughput.
Here is the configuration and screenshots of one of the better runs I had. I'm not sure if I'm limited by TCP or how Rediscala is using Akka IO at this point.Any further insights will be very useful and appreciated. In the mean time I'll continue to play around with different values.
Akka Team
Another akka-streams back pressure related question in context of the following piece of code.def insertValues(rnd: String): Flow[Int, Boolean] = {Flow[Int].mapAsyncUnordered(k => redis.set(k + rnd, message))}val maxSeq = 5000000val seqSource = Source( () => (1 to maxSeq).iterator )val streamWithSeqSource = seqSource.via(insertValues(random1)).runWith(blackhole)My understanding is that the next request is send to Redis from the client only after a "single" Future is completed. Is this correct ?
Is there a way I can batch a bunch of set requests and wait for them to be over before I can send a new batch ?
Soumya Simanta

Soumya Simanta
def insertValues(rnd: String): Flow[Int, Boolean] = {Flow[Int].mapAsyncUnordered(k => redis.set(k + rnd, message))}val maxSeq = 5000000val seqSource = Source( () => (1 to maxSeq).iterator )val streamWithSeqSource = seqSource.via(insertValues(random1)).runWith(blackhole)My understanding is that the next request is send to Redis from the client only after a "single" Future is completed. Is this correct ?No, the number of allowed uncompleted Futures is defined by the buffer size. If there wouldn't be a parallelization between Futures then there would be no need for an ordered and unordered version of the same operation.
Is there a way I can batch a bunch of set requests and wait for them to be over before I can send a new batch ?If there would be a version of set that accepts a Seq[] of writes, let's say "batchSet" then you could use:seqSource.grouped(100).mapAsyncUnordered(ks => redis.batchSet(...))Where grouped makes maximum 100 sized groups from the stream of elements resulting in a stream of sequences. You need API support for that from the Redis client though.

Akka Team
I added a ticket to write a simple batcher element recipe in the new cookbook: https://github.com/akka/akka/issues/16610
--
>>>>>>>>>> Read the docs: http://akka.io/docs/
>>>>>>>>>> Check the FAQ: http://doc.akka.io/docs/akka/current/additional/faq.html
>>>>>>>>>> Search the archives: https://groups.google.com/group/akka-user
---
You received this message because you are subscribed to the Google Groups "Akka User List" group.
To unsubscribe from this group and stop receiving emails from it, send an email to akka-user+...@googlegroups.com.
To post to this group, send email to akka...@googlegroups.com.
Visit this group at http://groups.google.com/group/akka-user.
For more options, visit https://groups.google.com/d/optout.