please update spanish wikipedia (es wiki)

☠☠☠

mhbraun
☠☠☠
• Articles per hour: artikel_pro_h = 6 990 ×60/50 = 8 388
• Estimated time of arrival (in hours): eta_h = anz_artikel/artikel_pro_h = 207.976
• Estimated time of arrival (in days): eta_d = runden(eta_h/24) = 9
• Megabytes per hour on disk: mb_pro_h = 81×60/50 = 97.2
• Expected final size of database when finished (in Gigabytes): db_gb = runden(mb_pro_h×eta_h/ 1 000 ) = 20
☠☠☠
########################
export TERM=rxvt-unicode
echo "export TERM=rxvt-unicode" >> ~/.bashrc # otherwise I had problems with my terminal and the forward and backward keys etc.
dnf install -y --nogpgcheck https://dl.fedoraproject.org/pub/epel/epel-release-latest-8.noarch.rpm
########################
# mwscrape for aardict #
########################
dnf install -y yum-utils
yum-config-manager --add-repo https://couchdb.apache.org/repo/couchdb.repo
dnf install -y couchdb libicu-devel gcc gcc-c++ python3-virtualenv python3-lxml python3-cssselect jq
pip3 install PyICU couchdb cssutils
# couchdb setup (better compression, admin account with stupid password for couchdb)
sed -i 's%;file_compression.*%file_compression = deflate_6%' /opt/couchdb/etc/default.ini
sed -i 's%;admin\ *=.*%admin = password%' /opt/couchdb/etc/local.ini
# start the DB
systemctl start couchdb.service
# show which databases are present in couchdb (none before you use mwscrape for the first time)
sleep 5s # starting of DB takes some time
curl http://admin:pass...@127.0.0.1:5984/_all_dbs | jq
Erik

itkach
☠☠☠
• Articles per hour: artikel_pro_h = 34 002 ×60/min_uptime = 4 988,07
• Estimated time of arrival (in hours): eta_h = anz_artikel/artikel_pro_h = 349,735
• Estimated time of arrival (in days): eta_d = runden(eta_h/24) = 15
• Megabytes per hour on disk: mb_pro_h = 873×60/min_uptime = 128,068
• Expected final size of database when finished (in Gigabytes): db_gb = runden(mb_pro_h×eta_h/ 1 000 ) = 45
☠☠☠
artikel_pro_h = 106 798 ×60/min_uptime = 4 567.27
eta_h = anz_artikel/artikel_pro_h = 381.957
eta_d = runden(eta_h/24) = 16
mb_pro_h = 1 100 ×60/min_uptime = 47.042 1
db_gb = runden(mb_pro_h×eta_h/ 1 000 ) = 18
mhb...@freenet.de
Sent: Thursday, January 13, 2022 05:47
To: aarddict
Subject: Re: please update spanish wikipedia (es wiki)
☠☠☠
STATISTICS_FILE="$HOME/statistics.txt"
# number of documents of first database (that should be Wikipedia/Wiktionary)
articles=$(curl -s http://admin:pass...@127.0.0.1:5984/$(curl -s http://admin:pass...@127.0.0.1:5984/_all_dbs | cut -d, -f 1 | sed "s%[\"\[]%%g") | sed "s%,%\n%g" | \grep doc_count | cut -d: -f2)
# size of db
db_size=$(du -s /opt/couchdb/data/ | cut -f1)
# uptime in Minuten
uptime_minutes=$(( ($(date +%s)-$(date --date="$(uptime -s)" +%s))/60 ))
# print them
echo $uptime_minutes $articles $db_size >> "$STATISTICS_FILE"
Erik
☠☠☠
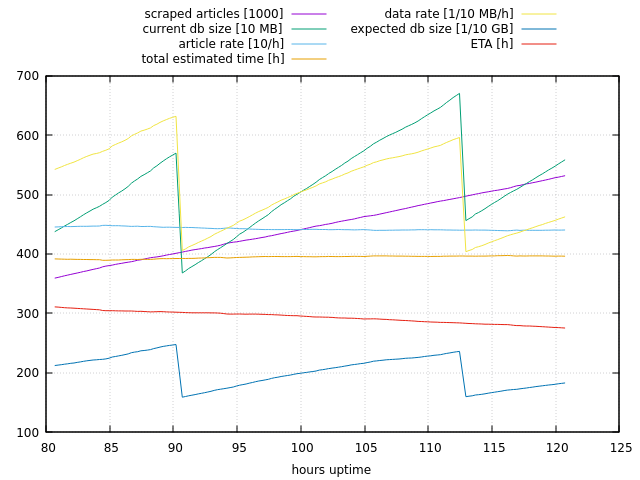
set xlabel "hours uptime"
f='statistics.txt'
set grid
tot_art=1744503
plot f u (h=$1/60):(scraped_articles=$2, scraped_articles/1000) w l t "scraped articles [1000]", \
f u (h=$1/60):(current_db_size=$3/1000, current_db_size/10) w l t "current db size [10 MB]", \
f u (h=$1/60):(art_rate=$2/$1*60, art_rate/10) w l t "article rate [10/h]", \
f u (h=$1/60):(tot_estimated_h=tot_art/($2/$1*60)) w l t "total estimated time [h]", \
f u (h=$1/60):(data_rate_mb_per_h=($3/1000)/$1*60, data_rate_mb_per_h*10) w l t "data rate [1/10 MB/h]", \
f u (h=$1/60):(data_rate_mb_per_h=($3/1000)/$1*60, total_estimated_time=tot_art/($2/$1*60), \
expected_db_size_gb=data_rate_mb_per_h*total_estimated_time/1000, expected_db_size_gb*10) w l t "expected db size [1/10 GB]", \
f u (h=$1/60):(total_estimated_time=tot_art/($2/$1*60), h=$1/60, eta_h=total_estimated_time-h) w l t "ETA [h]"######
☠☠☠
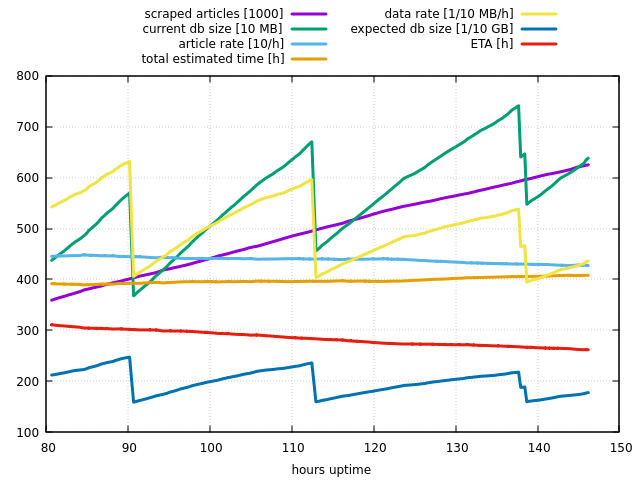
Markus Braun
This is great, Erik.
Thank you for your ideas and sharing the code. I am actually implementing it in a slightly different way, as I want to monitor the weekly updates this way.
Will keep you updated.
Markus
To view this discussion on the web visit https://groups.google.com/d/msgid/aarddict/1b00f14d-d810-44c4-b270-7b1763dab73an%40googlegroups.com.
☠☠☠
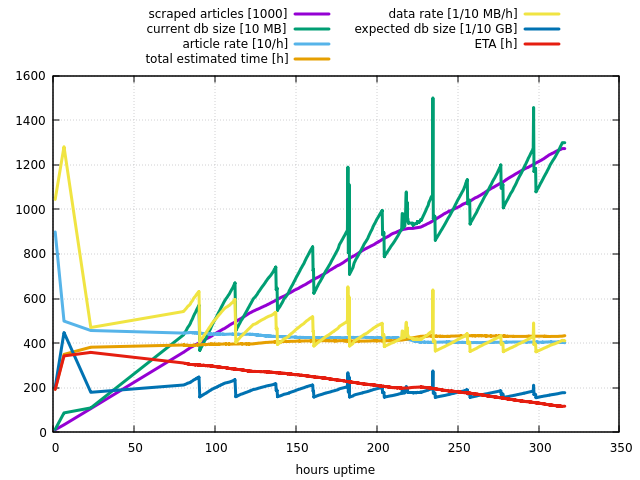
☠☠☠
I wanted to add this statistics graph.
☠☠☠
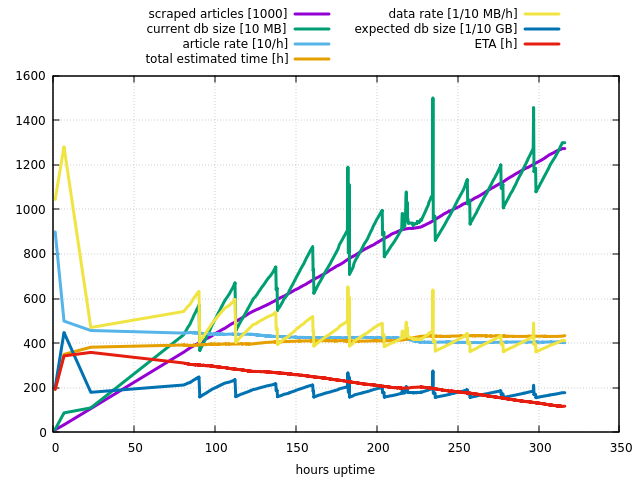
Markus Braun
Good. Sound strange. I have a similar (unresolved) issue with enwikitionary. Full scraping and updating does not deliver all articles. I have all articles with dewiki and enwiki.
The ceration of slob is super fast on your machine. For double the articles ( approx 6.8 mio) my enwiki takes about 5 days on a 4 core machine as a VM.
Let me know how to get your files and I will host it in the
library on RWTH Aachen in the Spanish section. Will give you more
details later today, as I am in a hurry now.
Thank you for your update
To view this discussion on the web visit https://groups.google.com/d/msgid/aarddict/f488737a-c3c6-464d-bff4-6133caaee11an%40googlegroups.com.
☠☠☠
itkach
☠☠☠
☠☠☠
☠☠☠

franc
This is good news that Wikimedia does weekly dumps of all wikis :) :) :)
But 100% reliable this is surely not, and I have to admit that I never read my logfiles ;)