backup-push failing
61 views
Skip to first unread message

btsc...@gmail.com
Jan 9, 2015, 4:31:35 PM1/9/15
to wa...@googlegroups.com
Hello!
First of all, this is my first post to this user group. If I'm in the wrong place please don't hesitate to point me in a different direction.
Starting around mid-December I've been unable to complete a backup-push. After running for an hour or so the server stops responding to network requests. The only thing I can do is wait until backup-push finishes and then I can ssh back in to the server.
Once back online I can find the following problems:
- dmesg repeats this error: [1107575.808936] xen_netfront: xennet: skb rides the rocket: 19 slots
- Wal-e complains about HTTP 500 when pushing files to S3 (sorry, I don't have a copy of this error handy)
My server is configured as follows (let me know if more info is helpful):
- amazon ec2 i2.4xlarge
- ubuntu 14.04 lts
- postgres 9.3
- wal-e 7.3
- database size is ~2.4TB
From what I've been able to find so far there may be a bug in the xennet driver that is causing the "rides the rocket" error, see here and here. I've tried turning some of the suggested features off with ethtool as suggested in the links and it seems to have prevented the "rides to the rocket" errors but backup-push still doesn't complete.
I've since used an older backup-push to get another server going for testing and it too has the same problem.
Has anyone else seen this? If so, were you able to resolve it?
Cheers,
Brian

Daniel Farina
Jan 9, 2015, 6:32:51 PM1/9/15
to btsc...@gmail.com, wal-e
On Fri, Jan 9, 2015 at 1:31 PM, <btsc...@gmail.com> wrote:
> Hello!
>
> First of all, this is my first post to this user group. If I'm in the wrong
> place please don't hesitate to point me in a different direction.
You got it right :)
> Hello!
>
> First of all, this is my first post to this user group. If I'm in the wrong
> place please don't hesitate to point me in a different direction.
> Starting around mid-December I've been unable to complete a backup-push.
> After running for an hour or so the server stops responding to network
> requests. The only thing I can do is wait until backup-push finishes and
> then I can ssh back in to the server.
> Once back online I can find the following problems:
>
> dmesg repeats this error: [1107575.808936] xen_netfront: xennet: skb rides
> the rocket: 19 slots
> Wal-e complains about HTTP 500 when pushing files to S3 (sorry, I don't have
> a copy of this error handy)
> My server is configured as follows (let me know if more info is helpful):
>
> amazon ec2 i2.4xlarge
> ubuntu 14.04 lts
> postgres 9.3
> wal-e 7.3
> database size is ~2.4TB
>
> From what I've been able to find so far there may be a bug in the xennet
> driver that is causing the "rides the rocket" error, see here and here.
> I've tried turning some of the suggested features off with ethtool as
> suggested in the links and it seems to have prevented the "rides to the
> rocket" errors but backup-push still doesn't complete.
>
> I've since used an older backup-push to get another server going for testing
> and it too has the same problem.
>
> Has anyone else seen this? If so, were you able to resolve it?
Also, try the current WAL-E master. Compared to 0.7.3, I have
drastically optimized the buffer management. Performance is perhaps
even ten times better, which matters for an instance of your size.
Brian Scholl
Jan 9, 2015, 9:01:09 PM1/9/15
to Daniel Farina, wal-e
Hello Daniel,
Thanks for the response! I will try both of these on a test server. It might take a few days but I'll update this thread when I have an update.
Have a great weekend!
Brian
Brian Scholl
Jan 21, 2015, 9:55:10 AM1/21/15
to Daniel Farina, wal-e
Updating this thread in case anyone else finds themselves in this boat...
This problem is still ongoing, here are the things I've tried:
Updated kernel to 3.16.0-29
No change, the launchpad thread on this issue (https://bugs.launchpad.net/ubuntu/+source/linux/+bug/1317811) indicates that the fix in 3.14+ might be a regression but should be fixed in the 15.04 release. Hopefully that fix makes its way back to LTS.
WAL-E master
No change after installing the master, but it did seem to take longer for the "rides the rocket" errors to start compounding.
That's just anecdotal though, I don't have any real timings.
Pool Size
I am currently trying a backup-push using --pool-size 1. This has been running for 12+ hours now and has only caused the error a few times. I'm hoping that even if this takes a couple days I can get a complete basebackup in to S3.
I haven't tried using the --cluster-read-rate-limit option yet. If the pool size change above doesn't pan out this option is next. My main concern with this option is not having a sense of what rate to pass in so pool size option was a little easier to attempt. If anyone has a suggestion on how to compute that number please let me know.

Daniel Farina
Jan 21, 2015, 12:24:32 PM1/21/15
to btsc...@gmail.com, Daniel Farina, wal-e
On Wed, Jan 21, 2015 at 6:55 AM, Brian Scholl <btsc...@gmail.com> wrote:
> Updating this thread in case anyone else finds themselves in this boat...
>
> This problem is still ongoing, here are the things I've tried:
>
> Updated kernel to 3.16.0-29
> No change, the launchpad thread on this issue
> (https://bugs.launchpad.net/ubuntu/+source/linux/+bug/1317811) indicates
> that the fix in 3.14+ might be a regression but should be fixed in the 15.04
> release. Hopefully that fix makes its way back to LTS.
>
> WAL-E master
> No change after installing the master, but it did seem to take longer for
> the "rides the rocket" errors to start compounding.
> That's just anecdotal though, I don't have any real timings.
>
> Pool Size
> I am currently trying a backup-push using --pool-size 1. This has been
> running for 12+ hours now and has only caused the error a few times. I'm
> hoping that even if this takes a couple days I can get a complete basebackup
> in to S3.
>
> I haven't tried using the --cluster-read-rate-limit option yet. If the pool
> size change above doesn't pan out this option is next. My main concern with
> this option is not having a sense of what rate to pass in so pool size
> option was a little easier to attempt. If anyone has a suggestion on how to
> compute that number please let me know.
Did you get a copy of that 500 you report?
> Updating this thread in case anyone else finds themselves in this boat...
>
> This problem is still ongoing, here are the things I've tried:
>
> Updated kernel to 3.16.0-29
> No change, the launchpad thread on this issue
> (https://bugs.launchpad.net/ubuntu/+source/linux/+bug/1317811) indicates
> that the fix in 3.14+ might be a regression but should be fixed in the 15.04
> release. Hopefully that fix makes its way back to LTS.
>
> WAL-E master
> No change after installing the master, but it did seem to take longer for
> the "rides the rocket" errors to start compounding.
> That's just anecdotal though, I don't have any real timings.
>
> Pool Size
> I am currently trying a backup-push using --pool-size 1. This has been
> running for 12+ hours now and has only caused the error a few times. I'm
> hoping that even if this takes a couple days I can get a complete basebackup
> in to S3.
>
> I haven't tried using the --cluster-read-rate-limit option yet. If the pool
> size change above doesn't pan out this option is next. My main concern with
> this option is not having a sense of what rate to pass in so pool size
> option was a little easier to attempt. If anyone has a suggestion on how to
> compute that number please let me know.
Brian Scholl
Jan 21, 2015, 12:25:25 PM1/21/15
to Daniel Farina, Daniel Farina, wal-e
Not yet, but I'll keep an eye on the backup-push output.
Daniel Farina
Jan 21, 2015, 12:31:07 PM1/21/15
to Brian Scholl, wal-e
On Wed, Jan 21, 2015 at 9:25 AM, Brian Scholl <btsc...@gmail.com> wrote:
> Not yet, but I'll keep an eye on the backup-push output.
WAL-E writes to syslog by default, maybe that helps?
> Not yet, but I'll keep an eye on the backup-push output.
Brian Scholl
Jan 21, 2015, 12:43:21 PM1/21/15
to Daniel Farina, wal-e
Hmm, no luck. I think logrotate might have eaten it already. If I find it I'll update this thread.
Brian Scholl
Jan 22, 2015, 4:16:54 PM1/22/15
to Daniel Farina, wal-e
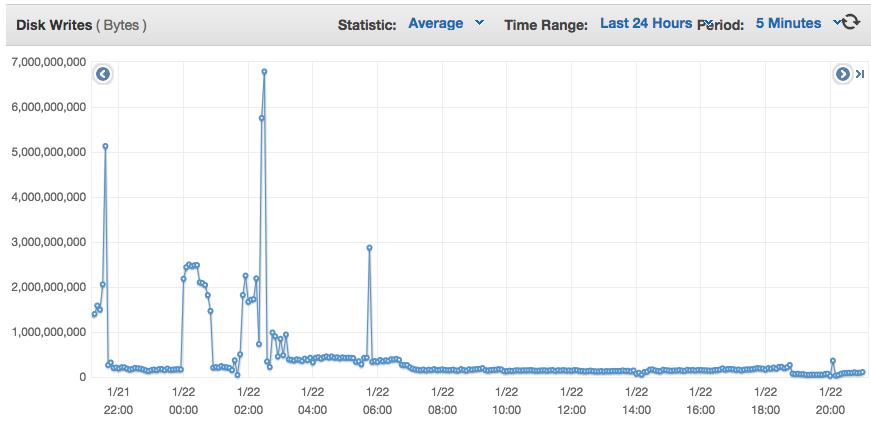
Reducing the backup-push pool size to 1 worked, it takes almost 18hrs but the server doesn't become completely inaccessible. I did end up disabling tso and sg on eth0 to work around the "rides the rocket" errors. It still feels a little spikey when connected via SSH (delays in connecting, delays in commands) but it's totally survivable.
Network utilization looks pegged throughout backup-push. I'm not sure if that's expected given my configuration. I've attached the ec2 monitoring graphs for disk read, disk write, and network over the past 24 hours.
Daniel, I think the only option I haven't tried yet is the --cluster-read-rate-limit. Do you still think that could be helpful? If so, could you provide some guidance as far as expected behavior and picking a rate?
{kind=link}
{kind=link}
{kind=link}
Daniel Farina
Jan 22, 2015, 4:19:30 PM1/22/15
to Brian Scholl, wal-e
On Thu, Jan 22, 2015 at 1:16 PM, Brian Scholl <btsc...@gmail.com> wrote:
> Reducing the backup-push pool size to 1 worked, it takes almost 18hrs but
> the server doesn't become completely inaccessible. I did end up disabling
> tso and sg on eth0 to work around the "rides the rocket" errors. It still
> feels a little spikey when connected via SSH (delays in connecting, delays
> in commands) but it's totally survivable.
>
> Network utilization looks pegged throughout backup-push. I'm not sure if
> that's expected given my configuration. I've attached the ec2 monitoring
> graphs for disk read, disk write, and network over the past 24 hours.
>
> Daniel, I think the only option I haven't tried yet is the
> --cluster-read-rate-limit. Do you still think that could be helpful? If
> so, could you provide some guidance as far as expected behavior and picking
> a rate?
How big is this database, and what is the 500 you see otherwise?
> Reducing the backup-push pool size to 1 worked, it takes almost 18hrs but
> the server doesn't become completely inaccessible. I did end up disabling
> tso and sg on eth0 to work around the "rides the rocket" errors. It still
> feels a little spikey when connected via SSH (delays in connecting, delays
> in commands) but it's totally survivable.
>
> Network utilization looks pegged throughout backup-push. I'm not sure if
> that's expected given my configuration. I've attached the ec2 monitoring
> graphs for disk read, disk write, and network over the past 24 hours.
>
> Daniel, I think the only option I haven't tried yet is the
> --cluster-read-rate-limit. Do you still think that could be helpful? If
> so, could you provide some guidance as far as expected behavior and picking
> a rate?
I have used 10MiB/s for nominal databases with success, but with
backups taking 18 hours, it would appear you have some combination of
a large database on tiny resources.
Brian Scholl
Jan 22, 2015, 4:25:51 PM1/22/15
to Daniel Farina, wal-e
I think we can discard the 500 error for now, I just can't find it and for all I know at this point it was a one-off.
The database is 2.5TB and it's running on an ec2 hs1.8xlarge. It's sitting on the ephemeral disks in a raid0.
Daniel Farina
Jan 22, 2015, 4:45:48 PM1/22/15
to Brian Scholl, wal-e
On Thu, Jan 22, 2015 at 1:25 PM, Brian Scholl <btsc...@gmail.com> wrote:
> I think we can discard the 500 error for now, I just can't find it and for
> all I know at this point it was a one-off.
>
> The database is 2.5TB and it's running on an ec2 hs1.8xlarge. It's sitting
> on the ephemeral disks in a raid0.
Hm. That's a fairly large instance. First of all, the optimizations
> I think we can discard the 500 error for now, I just can't find it and for
> all I know at this point it was a one-off.
>
> The database is 2.5TB and it's running on an ec2 hs1.8xlarge. It's sitting
> on the ephemeral disks in a raid0.
ought to help in this case, because the previous CPU usage per byte
was drastically higher.
How fast do you want to take the backup? Basic math suggests that
around 50% of gigabit saturation yields about 12 hours of backing up.
You are going to have to beef up the parallelism settings considerably
to go much faster, and if for any reason it's not possible to read
several files at the same time, you are out of luck.
Reply all
Reply to author
Forward
0 new messages