What can be done to improve the accuracy of extract
107 views
Skip to first unread message

Prav
Jul 15, 2017, 2:37:53 AM7/15/17
to tesseract-ocr
Hi,
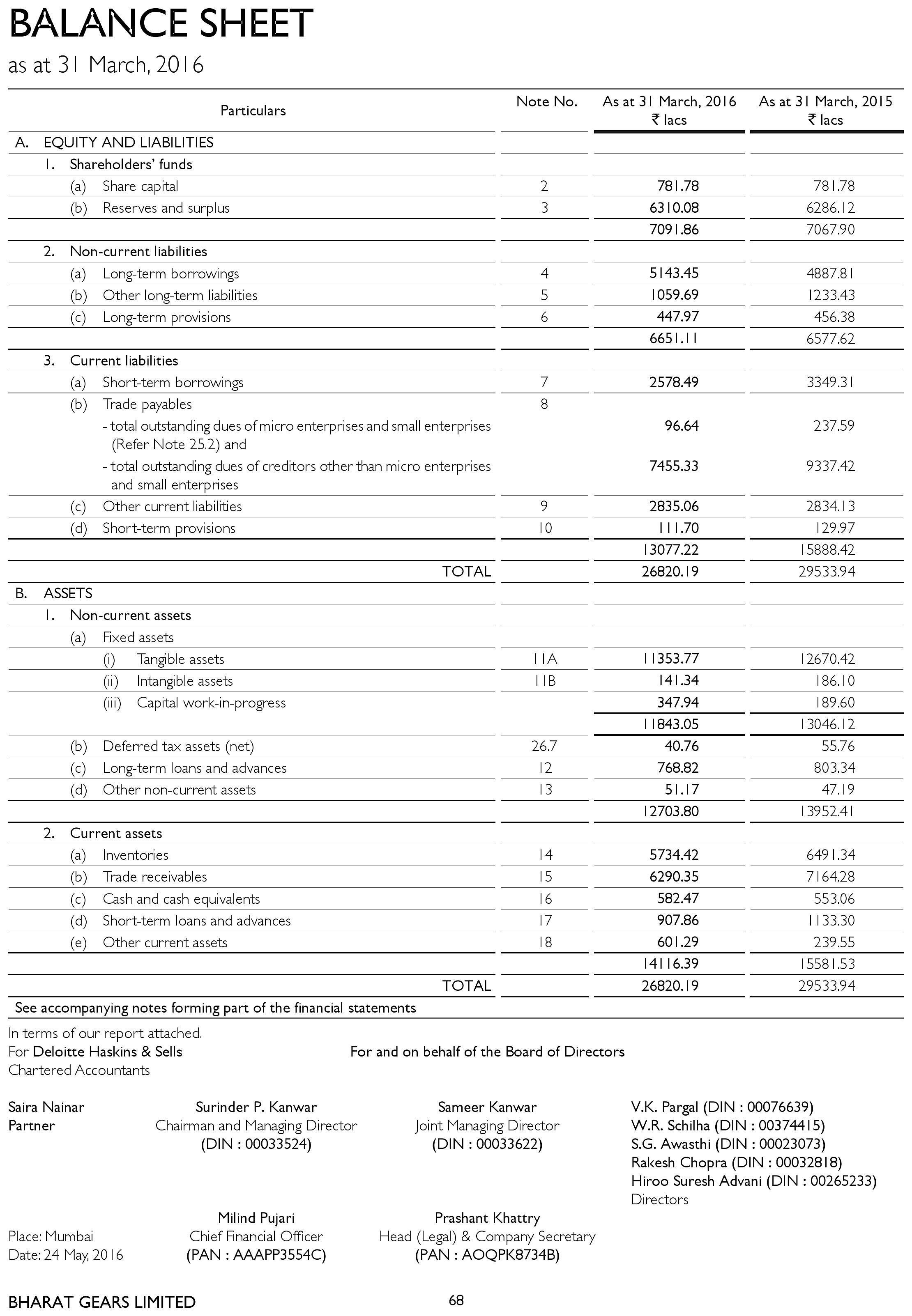
I have a good quality image from which text has to be extracted. I am getting the output with a lot of junk characters
The image is attached.
Corresponding hocr is also attached.
Any ideas on how the quality of output can be improved. There is a lot of junk coming out for a good quality image.

Tom Morris
Jul 15, 2017, 5:01:22 PM7/15/17
to tesseract-ocr
That doesn't look too bad for a completely untuned result.
The first thing you probably want to do is line removal and perhaps some segmentation of the image form. There are many, many threads in the archive concerning this, so I'm sure you'll find some good tips.
Tom

{kind=link}
srn...@gmail.com
Jul 17, 2017, 6:20:20 AM7/17/17
to tesseract-ocr
Hello Tom,
So, if for particular case is considered and to be trained.. then i should use one training text with lot of fonts (or)
so much of training text(so many copies of training text in one file one by one) with only one font.
What would be the ideal choice then,...
Can you please tell briefly about it..
Thanks...
So, if for particular case is considered and to be trained.. then i should use one training text with lot of fonts (or)
so much of training text(so many copies of training text in one file one by one) with only one font.
What would be the ideal choice then,...
Can you please tell briefly about it..
Thanks...
Reply all
Reply to author
Forward
0 new messages