poor results on relatively straightforward image
75 views
Skip to first unread message

hj
May 21, 2015, 2:27:25 AM5/21/15
to tesser...@googlegroups.com
see attached image. have tried various things, including this config:
tessedit_char_whitelist 0123456789:.
load_system_dawg F
load_freq_dawg F
tessedit_write_images T
tessedit_create_boxfile T
and playing around with the source image in various ways to get it in its attached form. also run it with -psm 7 (and have tried 8) to no avail.
currently i get: "30:59" which is significantly better than what i was obtaining previously.
based on the previous two posts and one i found on stackoverflow, it seems like tesseract has difficulty classifying "digital" font characters.
any suggested preprocessing that would improve performance here?

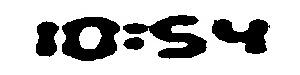{kind=link}
Dmitri Silaev
May 21, 2015, 3:08:19 AM5/21/15
to tesser...@googlegroups.com
Show the source image. Show what you have done to get the binarized version.
--
You received this message because you are subscribed to the Google Groups "tesseract-ocr" group.
To unsubscribe from this group and stop receiving emails from it, send an email to tesseract-oc...@googlegroups.com.
To post to this group, send email to tesser...@googlegroups.com.
Visit this group at http://groups.google.com/group/tesseract-ocr.
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/30dcc5f5-d7f3-4916-8dc4-cc8ad08b3d6b%40googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
Reply all
Reply to author
Forward
0 new messages