Scrapy Login Authenication not working
462 views
Skip to first unread message

Goutam Mohan
Jun 15, 2016, 12:19:47 PM6/15/16
to scrapy-users
I have just started using scrapy. I am facing few problems with login in scrapy. I am trying the scrape items in the website www.instacart.com. But I am facing timeout errors while logging in but I am unsuccessful.
The following is the code
class FirstSpider(scrapy.Spider):
name = "first"
allowed_domains = ["https://instacart.com"]
start_urls = [
"https://www.instacart.com"
]
def init_request(self):
return Request(url=self.login_page, callback=self.login)
def login(self, response):
return scrapy.FormRequest('https://www.instacart.com/#login',
formdata={'email': 'gob...@okstate.edu', 'password': 'instapassword',
},
callback=self.parse)
def check_login_response(self, response):
return scrapy.Request('https://www.instacart.com/', self.parse)
def parse(self, response):
if "Goutam" in response.body:
print "Successfully logged in. Let's start crawling!"
else:
print "Login unsuccessful"The following is the error message
C:\Users\gouta\PycharmProjects\CSG_Scraping\csg_wholefoods>scrapy crawl first
2016-06-15 09:47:00 [scrapy] INFO: Scrapy 1.0.3 started (bot: project)
2016-06-15 09:47:00 [scrapy] INFO: Optional features available: ssl, http11, boto
2016-06-15 09:47:00 [scrapy] INFO: Overridden settings: {'NEWSPIDER_MODULE': 'project.spiders', 'SPIDER_MODULES': ['project.spiders'], 'ROBOTSTXT_OBEY': True, 'BOT_NAME': 'project'}
2016-06-15 09:47:01 [scrapy] INFO: Enabled extensions: CloseSpider, TelnetConsole, LogStats, CoreStats, SpiderState
2016-06-15 09:47:01 [boto] DEBUG: Retrieving credentials from metadata server.
2016-06-15 09:47:02 [boto] ERROR: Caught exception reading instance data
Traceback (most recent call last):
File "C:\Users\gouta\AppData\Roaming\Python\Python27\site-packages\boto\utils.py", line 210, in retry_url
r = opener.open(req, timeout=timeout)
File "C:\Users\gouta\Anaconda2\lib\urllib2.py", line 431, in open
response = self._open(req, data)
File "C:\Users\gouta\Anaconda2\lib\urllib2.py", line 449, in _open
'_open', req)
File "C:\Users\gouta\Anaconda2\lib\urllib2.py", line 409, in _call_chain
result = func(*args)
File "C:\Users\gouta\Anaconda2\lib\urllib2.py", line 1227, in http_open
return self.do_open(httplib.HTTPConnection, req)
File "C:\Users\gouta\Anaconda2\lib\urllib2.py", line 1197, in do_open
raise URLError(err)
URLError: <urlopen error timed out>
2016-06-15 09:47:02 [boto] ERROR: Unable to read instance data, giving up
2016-06-15 09:47:02 [scrapy] INFO: Enabled downloader middlewares: RobotsTxtMiddleware, HttpAuthMiddleware, DownloadTimeoutMiddleware, UserAgentMiddleware, RetryMiddleware, DefaultHeadersMiddleware, MetaRefreshMiddleware, HttpCompressionMiddleware, RedirectMiddleware, CookiesMiddleware, ChunkedTransferMiddleware, DownloaderStats
2016-06-15 09:47:02 [scrapy] INFO: Enabled spider middlewares: HttpErrorMiddleware, OffsiteMiddleware, RefererMiddleware, UrlLengthMiddleware, DepthMiddleware
2016-06-15 09:47:02 [scrapy] INFO: Enabled item pipelines:
2016-06-15 09:47:02 [scrapy] INFO: Spider opened
2016-06-15 09:47:02 [scrapy] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2016-06-15 09:47:02 [scrapy] DEBUG: Telnet console listening on 127.0.0.1:6023
2016-06-15 09:47:02 [scrapy] DEBUG: Crawled (200) <GET https://www.instacart.com/robots.txt> (referer: None)
2016-06-15 09:47:02 [scrapy] DEBUG: Crawled (200) <GET https://www.instacart.com> (referer: None)
Login unsuccessful
2016-06-15 09:47:03 [scrapy] INFO: Closing spider (finished)
2016-06-15 09:47:03 [scrapy] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 440,
'downloader/request_count': 2,
'downloader/request_method_count/GET': 2,
'downloader/response_bytes': 17188,
'downloader/response_count': 2,
'downloader/response_status_count/200': 2,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2016, 6, 15, 14, 47, 3, 20000),
'log_count/DEBUG': 4,
'log_count/ERROR': 2,
'log_count/INFO': 7,
'response_received_count': 2,
'scheduler/dequeued': 1,
'scheduler/dequeued/memory': 1,
'scheduler/enqueued': 1,
'scheduler/enqueued/memory': 1,
'start_time': datetime.datetime(2016, 6, 15, 14, 47, 2, 316000)}
2016-06-15 09:47:03 [scrapy] INFO: Spider closed (finished)Any advice on what I am doing wrong is highly appreciated.

Valdir Stumm Junior
Jun 15, 2016, 1:37:42 PM6/15/16
to scrapy...@googlegroups.com
Hey!
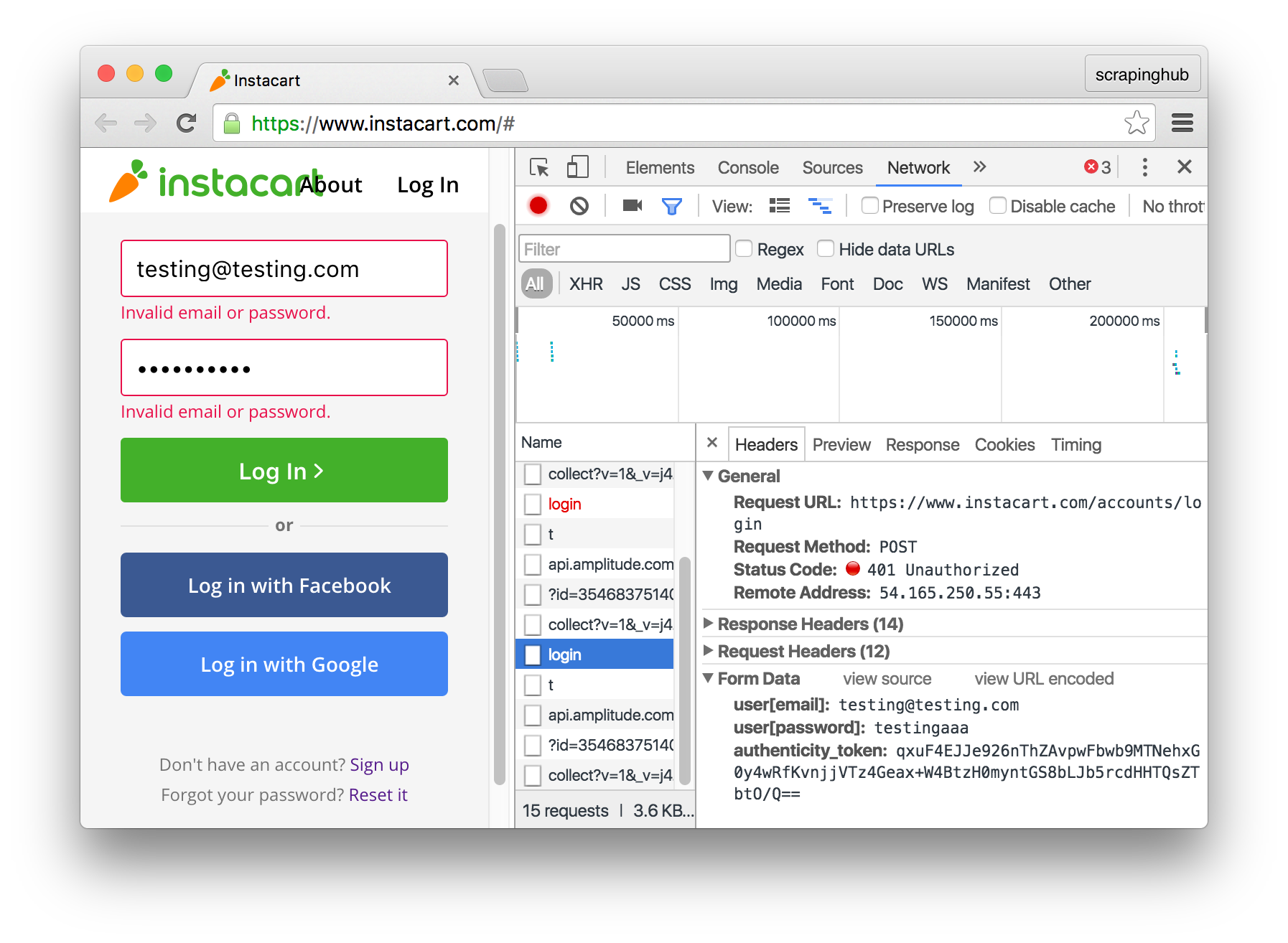
The form you are trying to log in requires you to pass an additional parameter (the CSRF token) with the form data. The parameter is called authenticity_token. To find this out by yourself, open your browser's developer tools, go to the Network panel, and inspect the request that the browser does when you try to log in:
The additional field is generated by the server for each login session, but you can scrape it from the page's HTML.
Also, you might notice that the request to login is made to `/accounts/login`.
--
You received this message because you are subscribed to the Google Groups "scrapy-users" group.
To unsubscribe from this group and stop receiving emails from it, send an email to scrapy-users...@googlegroups.com.
To post to this group, send email to scrapy...@googlegroups.com.
Visit this group at https://groups.google.com/group/scrapy-users.
For more options, visit https://groups.google.com/d/optout.
Valdir Stumm Junior
|
| |||||
Reply all
Reply to author
Forward
0 new messages