The Tree Problem: Part 11 - Actual Modeling
23 views
Skip to first unread message

John Clark
May 1, 2014, 12:20:51 PM5/1/14
to root...@googlegroups.com
Now that we defined our conceptual model in Part 10, lets actually model some stuff.
Introducing pTree
pTree is a Genealogical Data Model Specification that runs on vGraph. It splits its data into two parts, the What and the Why, and connects these together with a standard interface. It also allows multiple Whys, or research processes/methodologies, to coexist through namespacing.
Modeling What
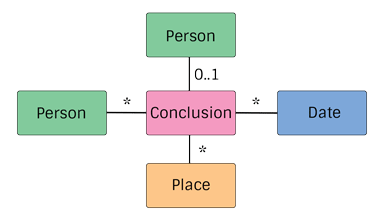
This is the basic diagram of how things are organized at the What level. In it we are Person-centric, with Conclusions being associated with a Person, Dates, Places, and other Persons.
Person - Pretty much just an identifier used to associate Conclusions with.
Conclusion - An abstract concept covering things like Events, Facts, etc. You will never actually see a "Conclusion" node in pTree, as each "Conclusion" is a specific type with its own attributes. Also, a Conclusion may be a sub-Graph, with multiple nodes and edges.
If you are familiar with GEDCOMX you may be saying "wait, why aren't you differentiating between Facts and Events?". My answer is why do we need to? What I consider an event is probably different that what you consider an event. If you want to get all "Events" for a person, just ask for what you want. Or you could just run a query that got all conclusions that have a Date and a Place (which is pretty much the only difference between a fact and an event). Not classifying lets us focus on modeling the What without trying to shoehorn it into something (ie, something happened, lets try and model it based on what it actually is/was).
Place - A Representation of a location on planet earth.
Date - A Representation of a date or date range, wether specific or approximate.
Marriage Conclusion Example
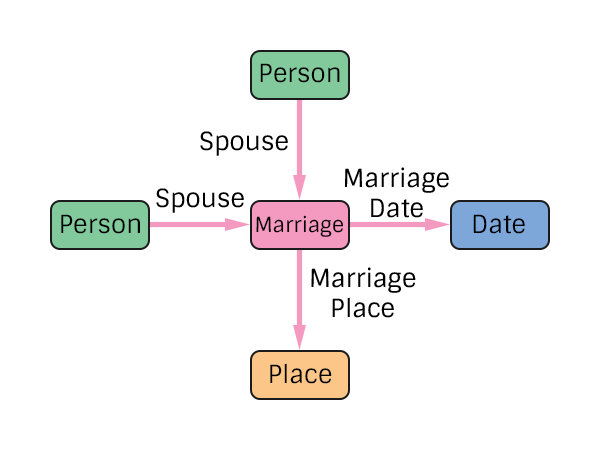
You will notice that the Marriage Conclusion has 3 edge types, Spouse, Date, and Place. Also, because we are in a graph we can represent missing information by just leaving it off. If we don't know the place, we just don't have the edge connecting Marriage to Place.
Modeling Why
The particular implementation of a Why depends on what type it is. In essence, it is whatever you want it to be. Just be sure to namespace all nodes and edges!
Here is the simplest Why of all, a Note!
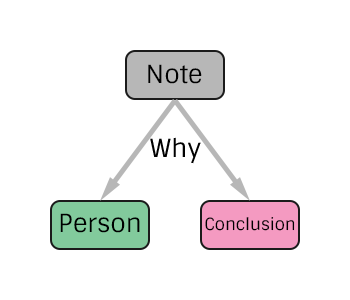
A Note can be associated with either a Person or a Conclusion. We have to be careful about associating a Why with a Place or Date. Most (if not all) conclusions allow at most 1 date or place, so we should just associate the note about why we think the date is correct to the actual Conclusion. This allows us to re-use Places, and then we can do things like get all people that have a conclusion that references a specific place. Plus, we could even start moving towards a standard set of place nodes. Wouldn't that be exiting!
We need more Whys. See Questions at the bottom for how to contribute.
Connecting Why to What
The connection between a Why and What is accomplished by using Why Connectors, edges that have the label "Why" and a type property set to the particular Why model that it links to.
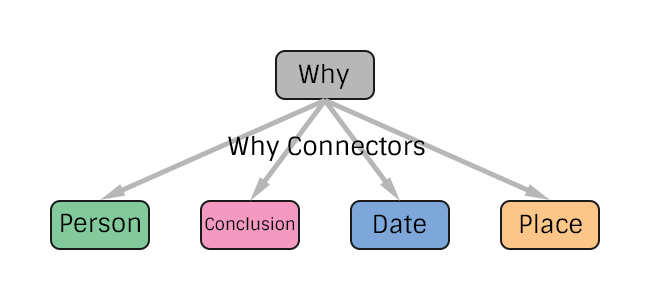
You can add additional properties to the Why Connector, and associate as many as you want with any What Node (Person, Conclusion, Date, Place).
Ramifications
1. Graph Statements
Because the only connection from a Why subgraph to a What subgraph is through a Why Connector, we can make some statements about our graph.
Any edge we follow from a Person, Date, or Place that is not a Why Connector belongs to a conclusion. This means that:
- We can dynamically discover conclusions, even if they are custom or we don't otherwise know about them.
- In our UI we can show ALL conclusions related to a person (Event, Relationship, fact, etc)
Any Why Connector edge we follow from a Person, Date, or Place will lead to a Why, and for each why that subgraph is clearly bounded. This means that:
- We can dynamically discover and partition off a particular Why without knowing any details about its composition.
- We can show ALL of the research that is available for a particular What (or set of Whats)
2. Namespacing
Because everything is namespaced, we can introduce new concepts into pTree dynamically. This allows for experimentation and complete customization WITHOUT interfering with anything else (provided the namespacing does not collide).
3. Modeling Complexity
Because a Conclusion can be a subgraph (multiple nodes and edges), we can model complex concepts and maintain the level of detail we want. We also have a beautiful way to enhance existing specs by adding optional edges to additional nodes. Adding things in this way will not break anyone, anywhere.
4. Serialization
Because we are build on a property graph, serialization is trivial. We can just export the underlying vGraph and save to disk.
5. Import/Export
We can import from and export to existing specifications. Because our model is flexible and very granular, we can translate to and from standards without much trouble. On import we can capture all of the applicable information, and when we export we can choose to only export compatible data, or try and translate non-compatible data to our export format (Personas and long evidence chains may be a bit tricky to put into GEDCOMX though). The nice thing is that if we need to, we can create a custom namespaced conclusion or Why to store information from a format that doesn't fit nicely, or doesn't really apply. Also, because we are in a property graph, we can create queries to extract and format the data for export.
6. Custom Views
Because we model what happened, and traversal is so cheap in a graph database, we can create custom "views" of our data at the application level. Say I wanted to be able to make 1 call and get a "family". Easy. Lets define what you mean by "family" (do we include foster children? What about biological vs nonbiological fathers? multiple marriages and spouses?, etc.) and then query pTree to extract what we want. Voila, we have gained convenience without sacrificing accuracy. Get X generations? No problem. Lets just define what we mean by generation and how we want to traverse generations, and lets query it! You have a different meaning of "marriage" than I do? No problem. Lets make two different queries and we're good.
What's Next
The pTree spec needs a lot more work, but it's time to let you in. We still need to address cross-repository querying, so I'll probably introduce that very soon here. After that it's time to bring everything together and examine what we've built. We're very close to finishing the first lap of the race!
Questions
Whys
I do not have the level of understanding in the various research processes discussed in this group to create them. I would love to see what a Persona Why looks like, as well as some of the other research processes. Lets discuss them and see how we can implement them. What do you guys want to see and/or create?
Conclusions
I know I have overlooked things in various Conclusions, so let me know where I'm wrong or missing things.
Incomplete
I'm actively working on the pTree spec right now. Normally I would polish a spec up more before releasing it, but I really value your feedback and experience in this area. Take a look and let me know what you think!- John C.
Reply all
Reply to author
Forward
0 new messages