RavenDB 4 - Document load time
34 views
Skip to first unread message

Andrej Krivulčík
May 21, 2018, 8:32:29 AM5/21/18
to RavenDB - 2nd generation document database
What is included in the studio's Traffic Watch Duration. Related - what is NOT included in this time?
When I load a bunch of documents from a testing database, the Duration in Traffic Watch reports typically 1000-1500 ms but the wall time is 2500-3000 ms.

(That's a decimal comma in the terminal window.)
I understand that there is some deserialization and processing going on client-side but the difference seems to be quite significant. The server could retrieve the documents from storage, deserialize them from disk, serialize them (and send over the wire) within 1500 ms, and there is another 1000-1500 ms overhead client-side? Is this reasonable/expected? The server runs locally in this case.

Oren Eini (Ayende Rahien)
May 21, 2018, 8:35:01 AM5/21/18
to ravendb
Try running this request inside Fiddler, it will give you a good breakdown of the costs.
Hibernating Rhinos Ltd
Oren Eini l CEO l Mobile: + 972-52-548-6969
Office: +972-4-622-7811 l Fax: +972-153-4-622-7811
--
You received this message because you are subscribed to the Google Groups "RavenDB - 2nd generation document database" group.
To unsubscribe from this group and stop receiving emails from it, send an email to ravendb+unsubscribe@googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
Oren Eini (Ayende Rahien)
May 21, 2018, 8:35:28 AM5/21/18
to ravendb
Andrej Krivulčík
May 21, 2018, 8:58:33 AM5/21/18
to RavenDB - 2nd generation document database
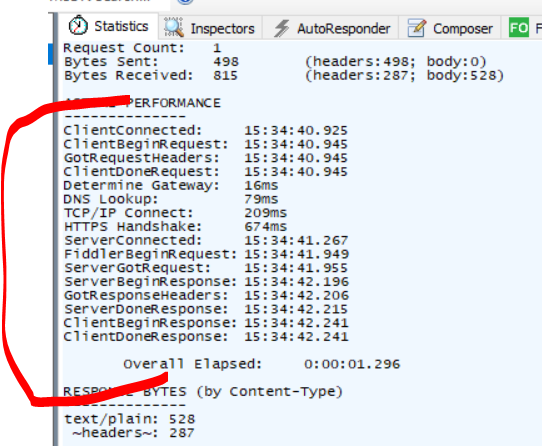
Cool, so I've got the following for a random request:
Request Count: 1
Bytes Sent: 36 097 (headers:303; body:35 794)
Bytes Received: 3 864 952 (headers:254; body:3 864 698)
ACTUAL PERFORMANCE
--------------
ClientConnected: 14:38:48.919
ClientBeginRequest: 14:38:50.560
GotRequestHeaders: 14:38:50.560
ClientDoneRequest: 14:38:50.927
Determine Gateway: 0ms
DNS Lookup: 0ms
TCP/IP Connect: 0ms
HTTPS Handshake: 0ms
ServerConnected: 14:37:39.866
FiddlerBeginRequest: 14:38:50.927
ServerGotRequest: 14:38:50.927
ServerBeginResponse: 14:38:51.314
GotResponseHeaders: 14:38:51.314
ServerDoneResponse: 14:38:51.798
ClientBeginResponse: 14:38:51.800
ClientDoneResponse: 14:38:51.803
Overall Elapsed: 0:00:01.243
RESPONSE BYTES (by Content-Type)
--------------
application/json: 3 864 698
~headers~: 254
Studio reports 870 ms duration for this particular request (corresponds nicely to the difference between ServerDoneResponse and ServerGotRequest). However, wall time elapsed is reported to be 3910 ms. So the client spent more than 3 seconds (3040 ms) doing "something" (deserialization being probably the biggest piece of work) with this data. Is this something to be expected? The laptop used is an ordinary i5-powered Windows machine with nothing much going on so this difference between server-side processing time and client-side processing time seems somewhat large to me. Have you experienced something like this during your performance benchmarks?
Now when I do the math, there are 10k documents processed in 3000 ms, so it's around 3,3 ms per document processing time. The documents are simple, just a string value, an int value and a Dictionary<string, int> with 50 int values (plus ID and metadata). Average size seems to be around 1,2 kB blittable, 1,5 kB JSON, 386 bytes over the wire (gzip-compressed JSON).
I'd like to confirm if this kind of performance is reasonable on synthetic data, as I'm trying to speed up processing of a large production database and this seems to be one of the places where making it a bit faster would result in big improvements.
Oren Eini (Ayende Rahien)
May 21, 2018, 9:10:26 AM5/21/18
to ravendb
This looks like 3 MB of JSON, so it is entirely possible that we are seeing high serialization times, yes.
How many documents are you reading here?
And you can probably also run a profiler on this to see where the time is spent
Hibernating Rhinos Ltd
Oren Eini l CEO l Mobile: + 972-52-548-6969
Office: +972-4-622-7811 l Fax: +972-153-4-622-7811
--
Andrej Krivulčík
May 21, 2018, 10:01:13 AM5/21/18
to RavenDB - 2nd generation document database
10k documents, with the following structure:
public class Doc
{
public string Id { get; set; }
public int IntVal { get; set; }
public Dictionary<string, int> IntVals { get; set; }
public string Version { get; set; }
}
IntVals contains 50 values in each document.
Profiler results indicate that yes, this is JSON parsing:

![]()
Thanks for clarification and explanations.
To unsubscribe from this group and stop receiving emails from it, send an email to ravendb+u...@googlegroups.com.
Oren Eini (Ayende Rahien)
May 21, 2018, 2:23:22 PM5/21/18
to ravendb
Please note that reading 10,000 documents using Load is not something that is really expected.
What exactly are you doing here?
To unsubscribe from this group and stop receiving emails from it, send an email to ravendb+unsubscribe@googlegroups.com.
Andrej Krivulčík
May 21, 2018, 4:56:16 PM5/21/18
to RavenDB - 2nd generation document database
So in a high level:
- I have a collection of source documents containing various string and double values (in dictionaries).
- There are around 10 million documents in this collection.
- Let's call these Sources.
- I'm processing these documents to a processed collection, grouped by a common identifier. There are typically 1-5 documents per such identifier, total number of documents in this processed collection will be around 3.5M.
- Let's call these Targets.
- The Source documents already contain some preprocessed values, which I don't need there anymore (are moved to the Targets), so in addition to computing the values in Targets, the Sources are changed too.
- I'm using subscriptions for the processing.
- The processing for the batch is the following:
- Load relevant Targets for all the Sources received in the batch.
- I need to almost always load as many Targets as there are Sources because of the document ordering in the collection (it's not possible to order by in subscription).
- This is where I got curious about the loading speed.
- Process the data from Sources to Targets.
- Remove the redundant data from Sources.
- Save session changes.
- When using the default batch size of 4096, the total processing speed was around 1600-2000 Sources/minute.
Using batch size of 1024, I did some timing in more detail with the following results (all times are wall times, measured using a System.Diagnostics.Stopwatch). Document sizes were determined by simple JSON serialization of the holding enumerable/dictionary etc. so not necessarily exact:
- Sources "load" (time between ending the previous batch and start of the current batch):
- Roughly 2 seconds, received 1024 documents, totaling usually 8 MB.
- Load of Targets, usually around 1000-1024 (some are not created yet, several are used for multiple Sources):
- Roughly 5-15 seconds, typically around 30 MB.
- Processing of the documents in memory.
- Usually 2 seconds +- several 10s of ms.
- Size of Source documents changes from 8 to ~3 MB, Target documents size is increased but I can't say exactly to how much. I was logging an incorrect value and now the characteristics of the documents are different so I'm getting different sizes for everything. I would guess that the resulting Target size is around 35-40 MB.
- Session save
- This needs to save the 3 MB of Sources and 35-40 MB of Targets and takes around 15 seconds.
With the diagnostics, the processing went at a rate of around 1200-1400 Sources/minute. The extra JSON serialization took some time and I *think* that the times above include the extra serializations, so are inflated somewhat.
After that, I removed the diagnostics and the best processing speed is around 2300 Sources/minute. I tried to let it run with batch size 256 for some time and it seems that the speed is comparable with batch size 1024. The times for batch size 256 are roughly 1/4 of the times for 1024, as expected: 0.5 secs Sources load, 2 secs Targets load, 0.5 secs processing, 4-6 secs session save. I log times but I don't log sizes
The speeds are for client running locally on an Azure L4s instance (4 cores, 32 GB RAM), with document data on a cloud SSD disk and indexing data on a host-local SSD disk (even faster than cloud SSD). During the reprocessing, I disabled all indexing.
Now, I'm aware that there is a lot going on here but the processing of the full data (10M documents) at this rate takes 3 days if it runs nonstop at full speed. In practice, it took more almost two weeks - slower speed combined with some issues with subscription timeouts (I'll report separately tomorrow, we already discussed this with Maxim and Adi here: https://groups.google.com/forum/#!topic/ravendb/rhF8lC6ydwA) and with memory leaks caused by using a version from before fixing this (https://groups.google.com/forum/#!topic/ravendb/-gk78LS7W2I) caused me some delays. I was busy doing other work during most of the processing so didn't really have an opportunity to look into this in more detail before. Also, it's possible that I'll need to reprocess the Sources again in the future so I'd like to not have avoidable bottlenecks.
This processing is almost over, last batches are being processed as I'm typing this message but any insight is greatly appreciated and will help me with future processing.
Oren Eini (Ayende Rahien)
May 22, 2018, 1:40:33 AM5/22/18
to ravendb
Is there a reason why you aren't using load in the subscription?
Note that in this case, you gather all the data you need up front and do it in one shot.
from Orders as o load o.Company as c select { Name: c.Name.toLowerCase(), Country: c.Address.Country, LinesCount: o.Lines.length }
Note that in this case, you gather all the data you need up front and do it in one shot.
Alternatively, if this is a one time thing, subscription is not ideal there, you are better off doing streaming for the entire data set.
Hibernating Rhinos Ltd
Oren Eini l CEO l Mobile: + 972-52-548-6969
Office: +972-4-622-7811 l Fax: +972-153-4-622-7811
--
Andrej Krivulčík
May 22, 2018, 2:02:01 AM5/22/18
to RavenDB - 2nd generation document database
I didn't think of using load in the subscription, I'll keep that in mind when I'll need to process the data again, thanks for the suggestion.
Last time I tried to process such collection using streaming, I was running into various problems (see https://groups.google.com/d/msg/ravendb/rx4v9te-Kzc/EaKnrGxoCQAJ) , and subscriptions worked nicely. However that was almost 2 years ago and on 3.5 so I'll give it a try next time, thanks again.
Reply all
Reply to author
Forward
0 new messages