Server side extensions on RavenDB 4.0
241 views
Skip to first unread message

Bruno Lopes
Jun 8, 2017, 12:10:18 PM6/8/17
to ravendb
On a recent blogpost I asked about server side plugins on RavenDB 4.0 and Oren mentioned that at the moment they "don't have them in 4.0. Aside from analyzers (...)" [1]. From some quick exchanges with Oren, it's not a final decision from HR's part, they're exploring solutions and would like some feedback.
Since we at InnovationCast have a couple of extensions that are very useful and play an important role on our infrastructure, I'd prefer if we could still extend RavenDB's behaviour on the server-side. Specially since I'm convinced that some of them are not possible just from client side (or would be very onerous/error-prone).
I'd like to ask around this ML whether other people have extended RavenDB and how/why they did it to have some more data points.
I'll be looking at our usages to share what are our use cases.
Bruno Lopes
Jun 11, 2017, 2:55:48 PM6/11/17
to RavenDB - 2nd generation document database
Hey all,
I believe that extensibility server-side is a plus for RavenDB. Being in C#, it's easier to extend than anything in c++ for us. This is my attempt at communicating how we extend, why it's a good choice to extend, and why the other options don't seem that palatable.
Also, there's PostgreSQL as previous art for extensibility on a database server. See https://github.com/dhamaniasad/awesome-postgres for some examples, for instance.
We use the extensibility points to add cross-cutting concerns (security culling and multi-language entities) on the infrastruture of our product, with minimal, declarative usage of those concerns. Wwe store extra fields on the indexes, and then query and project over them, so it's transparent and fast.
We use four extension points:
- AbstractDynamicCompilationExtension gives us a way to call methods during indexing on the server side, instead of copy/pasting common patterns. I believe that there are other usages for this, and it's one of the points which I think "must" be in 4.0 even if the others are not implemented;
- AbstractIndexUpdateTrigger allows us to add new fields to an index based on some characteristic of the index, without having to rewrite the linq expressions for maps and reduces;
- AbstractIndexQueryTrigger allows us to rewrite the query using Lucene's Query instances, instead of parsing the query ourselves and outputing the transformed version, or doing a somewhat blind change on the string;
- AbstractAnalyzerGenerator is used to select analyzers based on the document's language, instead of a field.
I think that without something like AbstractDynamicCompilationExtension, or some other way to add namespaces/assemblies/code which can be run on indexing we'll easily hit a wall when porting our infrastructure. From a quick read of the 4.0 code I don't think there's a way to add namespaces/assemblies, but I might be wrong, or it might just not be implemented yet.
If we lose the AbstractIndexUpdateTrigger , we'll need to move to rewriting the index definition. That means working the expression trees to add new fields, and that's something I dread a bit. And even then I'm not 100% sure we can get feature parity, but this is just a feeling.
On the other hand, indexes might be a bit easier to read/debug, because all the behaviour would be in the index itself. Looking at the definition stored on ravendb would show all the extra fields.
This would be harsher for the multi-language support, since adding a new language to the software would mean that all indexes would be refreshed to add those fields. The index definition for when we support 10 languages on entities with 5 or 7 multilanguage fields would have at least 70 fields (n_fields*n_languages).
Losing AbstractIndexQueryTrigger would mean either string manipulation of the lucene query (which might be a bit error prone), or parsing it client side, transforming and re-outputing it. Doing it server-side before running it seems better, since we'd be working with the final representation of the query after parsing.
Losing AbstractAnalyzerGenerator might push us to have to declare one version of each multilanguage field per language. If we add a new language, we'd then need to add it to all multilanguage indexes, and they'd be re-indexed. Also, the number of fields would explode.
I hope this helps put across why we think server-side extensibility is important :)
I believe that extensibility server-side is a plus for RavenDB. Being in C#, it's easier to extend than anything in c++ for us. This is my attempt at communicating how we extend, why it's a good choice to extend, and why the other options don't seem that palatable.
Also, there's PostgreSQL as previous art for extensibility on a database server. See https://github.com/dhamaniasad/awesome-postgres for some examples, for instance.
We use the extensibility points to add cross-cutting concerns (security culling and multi-language entities) on the infrastruture of our product, with minimal, declarative usage of those concerns. Wwe store extra fields on the indexes, and then query and project over them, so it's transparent and fast.
We use four extension points:
- AbstractDynamicCompilationExtension gives us a way to call methods during indexing on the server side, instead of copy/pasting common patterns. I believe that there are other usages for this, and it's one of the points which I think "must" be in 4.0 even if the others are not implemented;
- AbstractIndexUpdateTrigger allows us to add new fields to an index based on some characteristic of the index, without having to rewrite the linq expressions for maps and reduces;
- AbstractIndexQueryTrigger allows us to rewrite the query using Lucene's Query instances, instead of parsing the query ourselves and outputing the transformed version, or doing a somewhat blind change on the string;
- AbstractAnalyzerGenerator is used to select analyzers based on the document's language, instead of a field.
I think that without something like AbstractDynamicCompilationExtension, or some other way to add namespaces/assemblies/code which can be run on indexing we'll easily hit a wall when porting our infrastructure. From a quick read of the 4.0 code I don't think there's a way to add namespaces/assemblies, but I might be wrong, or it might just not be implemented yet.
If we lose the AbstractIndexUpdateTrigger , we'll need to move to rewriting the index definition. That means working the expression trees to add new fields, and that's something I dread a bit. And even then I'm not 100% sure we can get feature parity, but this is just a feeling.
On the other hand, indexes might be a bit easier to read/debug, because all the behaviour would be in the index itself. Looking at the definition stored on ravendb would show all the extra fields.
This would be harsher for the multi-language support, since adding a new language to the software would mean that all indexes would be refreshed to add those fields. The index definition for when we support 10 languages on entities with 5 or 7 multilanguage fields would have at least 70 fields (n_fields*n_languages).
Losing AbstractIndexQueryTrigger would mean either string manipulation of the lucene query (which might be a bit error prone), or parsing it client side, transforming and re-outputing it. Doing it server-side before running it seems better, since we'd be working with the final representation of the query after parsing.
Losing AbstractAnalyzerGenerator might push us to have to declare one version of each multilanguage field per language. If we add a new language, we'd then need to add it to all multilanguage indexes, and they'd be re-indexed. Also, the number of fields would explode.
I hope this helps put across why we think server-side extensibility is important :)

Tal Weiss
Jun 12, 2017, 4:46:31 AM6/12/17
to RavenDB - 2nd generation document database
Hi Bruno,
First let me start with saying that nothing is set in stone and we are still evaluating extensions so take what i'm saying with grain of salt.
Custom analyzers will be supported in v4.0
Query manipulation could be done in the client, we have a query parser in v4.0 as a separate project that runs on .net 4.6 you can generate the code of the parser or just grab it from our server and use it to parse strings into lucene queries (you can look at the QueryBuilder class in the server it does just that).
Regarding compilation extensions and abstract index trigger we tend to avoid those because they tend to be the source for issues for our clients and also impose internal compatibility requirements we don't support.
We have removed the notion of triggers all together so at least for now they are not supported.
--
You received this message because you are subscribed to the Google Groups "RavenDB - 2nd generation document database" group.
To unsubscribe from this group and stop receiving emails from it, send an email to ravendb+unsubscribe@googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
Hibernating Rhinos Ltd 
Tal Weiss l Core Team Developer l Mobile:+972-54-802-4849
Office: +972-4-622-7811 l Fax: +972-153-4-622-7811l Skype: talweiss1982
RavenDB paving the way to "Data Made Simple" http://ravendb.net/

Oren Eini (Ayende Rahien)
Jun 12, 2017, 5:28:17 AM6/12/17
to ravendb
inline
Hibernating Rhinos Ltd
Oren Eini l CEO l Mobile: + 972-52-548-6969
Office: +972-4-622-7811 l Fax: +972-153-4-622-7811
On Sun, Jun 11, 2017 at 9:55 PM, Bruno Lopes <bruno...@gmail.com> wrote:
Hey all,
I believe that extensibility server-side is a plus for RavenDB. Being in C#, it's easier to extend than anything in c++ for us. This is my attempt at communicating how we extend, why it's a good choice to extend, and why the other options don't seem that palatable.
Also, there's PostgreSQL as previous art for extensibility on a database server. See https://github.com/dhamaniasad/awesome-postgres for some examples, for instance.
We use the extensibility points to add cross-cutting concerns (security culling and multi-language entities) on the infrastruture of our product, with minimal, declarative usage of those concerns. Wwe store extra fields on the indexes, and then query and project over them, so it's transparent and fast.
We use four extension points:
- AbstractDynamicCompilationExtension gives us a way to call methods during indexing on the server side, instead of copy/pasting common patterns. I believe that there are other usages for this, and it's one of the points which I think "must" be in 4.0 even if the others are not implemented;
We are thinking about making this a setting, so you'll upload a document that contain the namespaces to add as well as some code that will be compiled with all indexes.
The benefit is that we don't need to compile it and we don't need to maintain version dependence.
- AbstractIndexUpdateTrigger allows us to add new fields to an index based on some characteristic of the index, without having to rewrite the linq expressions for maps and reduces;
That has been a pretty bad issue regarding performance in several cases.
It is better to do the index re-write as it goes in.
- AbstractIndexQueryTrigger allows us to rewrite the query using Lucene's Query instances, instead of parsing the query ourselves and outputing the transformed version, or doing a somewhat blind change on the string;
This is better doing that on the client.
- AbstractAnalyzerGenerator is used to select analyzers based on the document's language, instead of a field.
I'm actually thinking that we can move this behavior to the index itself.
Name = Index(d.Name, "analyzer name")
That would be simpler, I think.
I think that without something like AbstractDynamicCompilationExtension, or some other way to add namespaces/assemblies/code which can be run on indexing we'll easily hit a wall when porting our infrastructure. From a quick read of the 4.0 code I don't think there's a way to add namespaces/assemblies, but I might be wrong, or it might just not be implemented yet.
If we lose the AbstractIndexUpdateTrigger , we'll need to move to rewriting the index definition. That means working the expression trees to add new fields, and that's something I dread a bit. And even then I'm not 100% sure we can get feature parity, but this is just a feeling.
What exactly are you doing there?
And I wonder if I we can add that as something that the code script which will be uploaded will do?
Something like:
void IndexDocument(Document index, dynamic doc){
// do something there
}
I would rather avoid it, because it is magical, and not a good idea.
On the other hand, indexes might be a bit easier to read/debug, because all the behaviour would be in the index itself. Looking at the definition stored on ravendb would show all the extra fields.
This would be harsher for the multi-language support, since adding a new language to the software would mean that all indexes would be refreshed to add those fields. The index definition for when we support 10 languages on entities with 5 or 7 multilanguage fields would have at least 70 fields (n_fields*n_languages).
Losing AbstractIndexQueryTrigger would mean either string manipulation of the lucene query (which might be a bit error prone), or parsing it client side, transforming and re-outputing it. Doing it server-side before running it seems better, since we'd be working with the final representation of the query after parsing.
Losing AbstractAnalyzerGenerator might push us to have to declare one version of each multilanguage field per language. If we add a new language, we'd then need to add it to all multilanguage indexes, and they'd be re-indexed. Also, the number of fields would explode.
I hope this helps put across why we think server-side extensibility is important :)
On Thursday, 8 June 2017 17:10:18 UTC+1, Bruno Lopes wrote:On a recent blogpost I asked about server side plugins on RavenDB 4.0 and Oren mentioned that at the moment they "don't have them in 4.0. Aside from analyzers (...)" [1]. From some quick exchanges with Oren, it's not a final decision from HR's part, they're exploring solutions and would like some feedback.Since we at InnovationCast have a couple of extensions that are very useful and play an important role on our infrastructure, I'd prefer if we could still extend RavenDB's behaviour on the server-side. Specially since I'm convinced that some of them are not possible just from client side (or would be very onerous/error-prone).I'd like to ask around this ML whether other people have extended RavenDB and how/why they did it to have some more data points.I'll be looking at our usages to share what are our use cases.[1] https://ayende.com/blog/178434/ravendb-4-0-licensing-pricing#comment23
--
Bruno Lopes
Jun 13, 2017, 9:41:38 AM6/13/17
to ravendb
Tal, Oren,
Thanks for the replies.
I understand that these features are/were sharp tools to be used with care.
When
you mention that the triggers usually cause performance issues, we see as a trade-off between querying and indexing performance, some ease of use and less bugs (in our case, since we're able to abstract behaviour behind some of the extensions)
On Mon, Jun 12, 2017 at 10:27 AM, Oren Eini (Ayende Rahien) <aye...@ayende.com> wrote:
inlineHibernating Rhinos Ltd
Oren Eini l CEO l Mobile: + 972-52-548-6969
Office: +972-4-622-7811 l Fax: +972-153-4-622-7811
On Sun, Jun 11, 2017 at 9:55 PM, Bruno Lopes <bruno...@gmail.com> wrote:Hey all,
I believe that extensibility server-side is a plus for RavenDB. Being in C#, it's easier to extend than anything in c++ for us. This is my attempt at communicating how we extend, why it's a good choice to extend, and why the other options don't seem that palatable.
Also, there's PostgreSQL as previous art for extensibility on a database server. See https://github.com/dhamaniasad/awesome-postgres for some examples, for instance.
We use the extensibility points to add cross-cutting concerns (security culling and multi-language entities) on the infrastruture of our product, with minimal, declarative usage of those concerns. Wwe store extra fields on the indexes, and then query and project over them, so it's transparent and fast.
We use four extension points:
- AbstractDynamicCompilationExtension gives us a way to call methods during indexing on the server side, instead of copy/pasting common patterns. I believe that there are other usages for this, and it's one of the points which I think "must" be in 4.0 even if the others are not implemented;We are thinking about making this a setting, so you'll upload a document that contain the namespaces to add as well as some code that will be compiled with all indexes.The benefit is that we don't need to compile it and we don't need to maintain version dependence.
I like this.
I see a big advantage in that the code would be scoped narrower than the whole process.
Would it be per index or per database? Most of our code would be the same in a database.
I see a big advantage in that the code would be scoped narrower than the whole process.
Would it be per index or per database? Most of our code would be the same in a database.
Would we still be able to load other assemblies ? I'm thinking of being able to import something like NodaTime, perhaps.
- AbstractIndexUpdateTrigger allows us to add new fields to an index based on some characteristic of the index, without having to rewrite the linq expressions for maps and reduces;That has been a pretty bad issue regarding performance in several cases.It is better to do the index re-write as it goes in.- AbstractIndexQueryTrigger allows us to rewrite the query using Lucene's Query instances, instead of parsing the query ourselves and outputing the transformed version, or doing a somewhat blind change on the string;This is better doing that on the client.
- AbstractAnalyzerGenerator is used to select analyzers based on the document's language, instead of a field.I'm actually thinking that we can move this behavior to the index itself.Name = Index(d.Name, "analyzer name")That would be simpler, I think.
If we can upload a method so it would look like "Name = AnalyzeForLanguage(d.Name, d.LanguageName)" this would work, I think.
We'd still need to be able to store the Name so we can load the doc from the index directly, I'm not sure if that would be an issue.
I think that without something like AbstractDynamicCompilationExtension, or some other way to add namespaces/assemblies/code which can be run on indexing we'll easily hit a wall when porting our infrastructure. From a quick read of the 4.0 code I don't think there's a way to add namespaces/assemblies, but I might be wrong, or it might just not be implemented yet.
If we lose the AbstractIndexUpdateTrigger , we'll need to move to rewriting the index definition. That means working the expression trees to add new fields, and that's something I dread a bit. And even then I'm not 100% sure we can get feature parity, but this is just a feeling.What exactly are you doing there?
For the multilanguage support, we look into the doc's language, and create the language specific fields. Title goes into Title_en if it's an english doc, Title_pt if it's portuguese. Then on reduce we'd merge all. Title itself ends up being a complex object which doesn't get used when loading the document from the index. When we load the document from the index, we match languages and grab from the fields for a particular language.
For the security support, we do a LoadDocument (yes, yes, yes, I know, give me the benefit of the doubt here and assume it's not that horrid an idea in our case) for the security document referenced by the item (which doesn't get changed all that often) and create the fields for security filtering (like _Security_Read_UserIds or _Security_Moderate_RoleIds).
Both these behaviours are declarative on the index definition.
And I wonder if I we can add that as something that the code script which will be uploaded will do?Something like:void IndexDocument(Document index, dynamic doc){// do something there}
This could work. I'm not sure how we'd plug in orthogonal behaviours (like it's secure multilanguage index, instead of just secure), but together with a code script that includes some methods I think we'd be good.
I would rather avoid it, because it is magical, and not a good idea.
Magical from who's point of view? I might be biased in that I don't think all "magic" is bad. A bit of it can go a long way, if one's careful.
Btw, guys, configuration options for the index? these would be awesome for us if we still had the triggers ;)
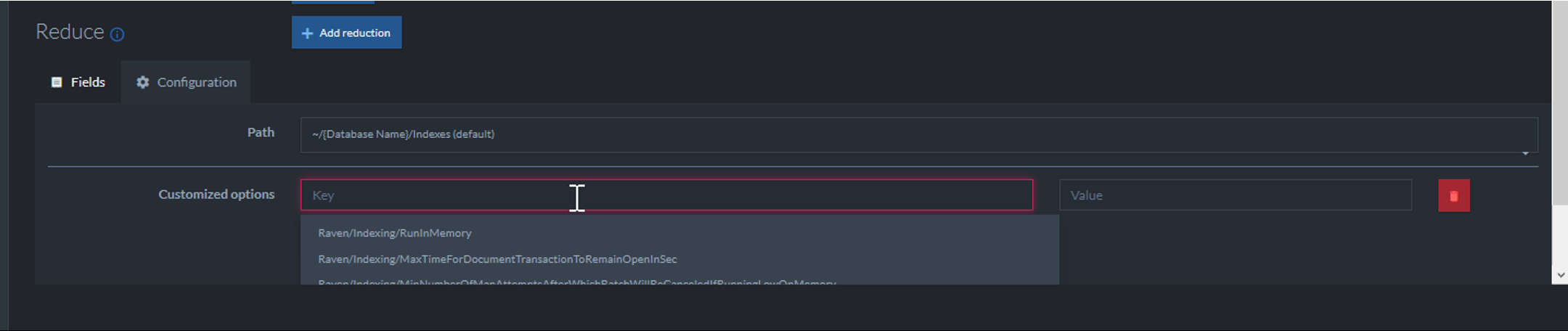
On the other hand, indexes might be a bit easier to read/debug, because all the behaviour would be in the index itself. Looking at the definition stored on ravendb would show all the extra fields.
This would be harsher for the multi-language support, since adding a new language to the software would mean that all indexes would be refreshed to add those fields. The index definition for when we support 10 languages on entities with 5 or 7 multilanguage fields would have at least 70 fields (n_fields*n_languages).
Losing AbstractIndexQueryTrigger would mean either string manipulation of the lucene query (which might be a bit error prone), or parsing it client side, transforming and re-outputing it. Doing it server-side before running it seems better, since we'd be working with the final representation of the query after parsing.
Losing AbstractAnalyzerGenerator might push us to have to declare one version of each multilanguage field per language. If we add a new language, we'd then need to add it to all multilanguage indexes, and they'd be re-indexed. Also, the number of fields would explode.
I hope this helps put across why we think server-side extensibility is important :)
On Thursday, 8 June 2017 17:10:18 UTC+1, Bruno Lopes wrote:On a recent blogpost I asked about server side plugins on RavenDB 4.0 and Oren mentioned that at the moment they "don't have them in 4.0. Aside from analyzers (...)" [1]. From some quick exchanges with Oren, it's not a final decision from HR's part, they're exploring solutions and would like some feedback.Since we at InnovationCast have a couple of extensions that are very useful and play an important role on our infrastructure, I'd prefer if we could still extend RavenDB's behaviour on the server-side. Specially since I'm convinced that some of them are not possible just from client side (or would be very onerous/error-prone).I'd like to ask around this ML whether other people have extended RavenDB and how/why they did it to have some more data points.I'll be looking at our usages to share what are our use cases.[1] https://ayende.com/blog/178434/ravendb-4-0-licensing-pricing#comment23--
You received this message because you are subscribed to the Google Groups "RavenDB - 2nd generation document database" group.
To unsubscribe from this group and stop receiving emails from it, send an email to ravendb+unsubscribe@googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
--
You received this message because you are subscribed to a topic in the Google Groups "RavenDB - 2nd generation document database" group.
To unsubscribe from this topic, visit https://groups.google.com/d/topic/ravendb/iLMZVZHZuWQ/unsubscribe.
To unsubscribe from this group and all its topics, send an email to ravendb+unsubscribe@googlegroups.com.
Oren Eini (Ayende Rahien)
Jun 13, 2017, 9:57:35 AM6/13/17
to ravendb
inline
Probably per db, I think.
Would we still be able to load other assemblies ? I'm thinking of being able to import something like NodaTime, perhaps.
This is a bit problematic.
One of the reasons we want to move this code to the database level is that we can take care of spinning it into the cluster as a whole.
If you reference additional assemblies, you'll need to also ensure that the binaries are deployed properly on all the nodes.
- AbstractIndexUpdateTrigger allows us to add new fields to an index based on some characteristic of the index, without having to rewrite the linq expressions for maps and reduces;That has been a pretty bad issue regarding performance in several cases.It is better to do the index re-write as it goes in.- AbstractIndexQueryTrigger allows us to rewrite the query using Lucene's Query instances, instead of parsing the query ourselves and outputing the transformed version, or doing a somewhat blind change on the string;This is better doing that on the client.
- AbstractAnalyzerGenerator is used to select analyzers based on the document's language, instead of a field.I'm actually thinking that we can move this behavior to the index itself.Name = Index(d.Name, "analyzer name")That would be simpler, I think.If we can upload a method so it would look like "Name = AnalyzeForLanguage(d.Name, d.LanguageName)" this would work, I think.
Yes, I think that would be the way to go, yes.
We'd still need to be able to store the Name so we can load the doc from the index directly, I'm not sure if that would be an issue.
Not following?
I think that without something like AbstractDynamicCompilationExtension, or some other way to add namespaces/assemblies/code which can be run on indexing we'll easily hit a wall when porting our infrastructure. From a quick read of the 4.0 code I don't think there's a way to add namespaces/assemblies, but I might be wrong, or it might just not be implemented yet.
If we lose the AbstractIndexUpdateTrigger , we'll need to move to rewriting the index definition. That means working the expression trees to add new fields, and that's something I dread a bit. And even then I'm not 100% sure we can get feature parity, but this is just a feeling.What exactly are you doing there?For the multilanguage support, we look into the doc's language, and create the language specific fields. Title goes into Title_en if it's an english doc, Title_pt if it's portuguese. Then on reduce we'd merge all. Title itself ends up being a complex object which doesn't get used when loading the document from the index. When we load the document from the index, we match languages and grab from the fields for a particular language.
Is there any reason not to do that using:
_ = FieldsForLanguage(d.Name)
?
For the security support, we do a LoadDocument (yes, yes, yes, I know, give me the benefit of the doubt here and assume it's not that horrid an idea in our case) for the security document referenced by the item (which doesn't get changed all that often) and create the fields for security filtering (like _Security_Read_UserIds or _Security_Moderate_RoleIds).
LoadDocument is actually MUCH better in 4.0 :-)
Both these behaviours are declarative on the index definition.
And I wonder if I we can add that as something that the code script which will be uploaded will do?Something like:void IndexDocument(Document index, dynamic doc){// do something there}This could work. I'm not sure how we'd plug in orthogonal behaviours (like it's secure multilanguage index, instead of just secure), but together with a code script that includes some methods I think we'd be good.
Actually, we can just have you do something like:
select new {
}.DecorateYourEntityWithCustomFields();
No?
I would rather avoid it, because it is magical, and not a good idea.Magical from who's point of view? I might be biased in that I don't think all "magic" is bad. A bit of it can go a long way, if one's careful.Btw, guys, configuration options for the index? these would be awesome for us if we still had the triggers ;)
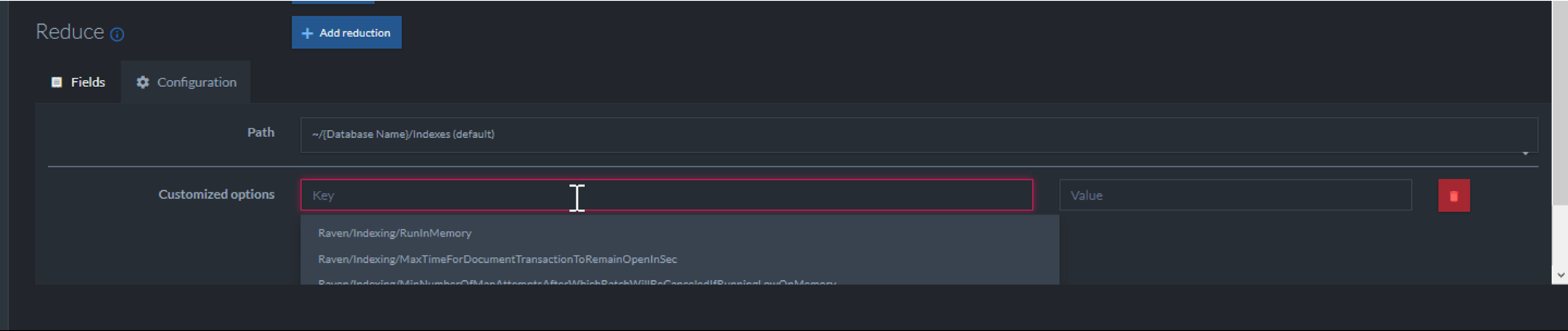
Those are actually for the purpose of special configuration of the index itself (storage behavior, etc).
Bruno Lopes
Jun 13, 2017, 10:38:35 AM6/13/17
to ravendb
Ah, yes, I get that.
If this is just for these kind of dependencies, I wouldn't mind handling this myself (if we need to restart the server for it to pick up the new assemblies it wouldn't be too much of an issue) but then again, I haven't had to deal with clusters so far, so I might just be blind to the issues.
- AbstractIndexUpdateTrigger allows us to add new fields to an index based on some characteristic of the index, without having to rewrite the linq expressions for maps and reduces;That has been a pretty bad issue regarding performance in several cases.It is better to do the index re-write as it goes in.- AbstractIndexQueryTrigger allows us to rewrite the query using Lucene's Query instances, instead of parsing the query ourselves and outputing the transformed version, or doing a somewhat blind change on the string;This is better doing that on the client.
- AbstractAnalyzerGenerator is used to select analyzers based on the document's language, instead of a field.I'm actually thinking that we can move this behavior to the index itself.Name = Index(d.Name, "analyzer name")That would be simpler, I think.If we can upload a method so it would look like "Name = AnalyzeForLanguage(d.Name, d.LanguageName)" this would work, I think.Yes, I think that would be the way to go, yes.We'd still need to be able to store the Name so we can load the doc from the index directly, I'm not sure if that would be an issue.Not following?
I don't know what AnalyzeForLanguage or Index would return. If it's lucene terms to be stored on the lucene document, some object representing both what we intend to store and what we intend to search on, an array of strings that are analyzed.
Perhaps it's easier if I just say that "I want to be able to search on Title for 'reader', find 'reading a book', and have the query result be read from the index itself".
If "Index" or "AnalyzeForLanguage" causes the original field to be lost (because raven would just use whatever it returns to store on the lucene document), we wouldn't be able to read the Title from the index
But I might be thinking of a problem which doesn't (wouldn't) exist.
I think that without something like AbstractDynamicCompilationExtension, or some other way to add namespaces/assemblies/code which can be run on indexing we'll easily hit a wall when porting our infrastructure. From a quick read of the 4.0 code I don't think there's a way to add namespaces/assemblies, but I might be wrong, or it might just not be implemented yet.
If we lose the AbstractIndexUpdateTrigger , we'll need to move to rewriting the index definition. That means working the expression trees to add new fields, and that's something I dread a bit. And even then I'm not 100% sure we can get feature parity, but this is just a feeling.What exactly are you doing there?For the multilanguage support, we look into the doc's language, and create the language specific fields. Title goes into Title_en if it's an english doc, Title_pt if it's portuguese. Then on reduce we'd merge all. Title itself ends up being a complex object which doesn't get used when loading the document from the index. When we load the document from the index, we match languages and grab from the fields for a particular language.Is there any reason not to do that using:_ = FieldsForLanguage(d.Name)?
I'd have to check our notes to be sure, but it might be that we store entity and entity translation separately, we map-reduce them for the listings to get a single entity result and need to figure out what language a field value comes from.
We map both entity and entityTranslation, into a "multilanguageEntityResult". Some of the values we take from the entity (like creation date, or owner) and some from the multilanguage content nearest the requested language.
On the reduce we need to know which language a field value is from to create the proper field, so on the map we actually store a {languageName:"en",value:"an english title", __multilanguage_marker__:true}, and on the reduce we gather all such objects to create the final fields.
We map both entity and entityTranslation, into a "multilanguageEntityResult". Some of the values we take from the entity (like creation date, or owner) and some from the multilanguage content nearest the requested language.
On the reduce we need to know which language a field value is from to create the proper field, so on the map we actually store a {languageName:"en",value:"an english title", __multilanguage_marker__:true}, and on the reduce we gather all such objects to create the final fields.
For the security support, we do a LoadDocument (yes, yes, yes, I know, give me the benefit of the doubt here and assume it's not that horrid an idea in our case) for the security document referenced by the item (which doesn't get changed all that often) and create the fields for security filtering (like _Security_Read_UserIds or _Security_Moderate_RoleIds).LoadDocument is actually MUCH better in 4.0 :-)
Whoho! I think I can remember some talk of optimizations there, and it's great because when we need it, we really need it (or at least I think we do) ;)
Both these behaviours are declarative on the index definition.And I wonder if I we can add that as something that the code script which will be uploaded will do?Something like:void IndexDocument(Document index, dynamic doc){// do something there}This could work. I'm not sure how we'd plug in orthogonal behaviours (like it's secure multilanguage index, instead of just secure), but together with a code script that includes some methods I think we'd be good.Actually, we can just have you do something like:select new {}.DecorateYourEntityWithCustomFields();No?
Because the resulting object is a dynamic, and I can just append fields to that dynamic, right?
Yap, that could work :)
select new {
}.SecureWithPermissions(Core.Read, Quality.Moderate).Multilanguage()
I would rather avoid it, because it is magical, and not a good idea.Magical from who's point of view? I might be biased in that I don't think all "magic" is bad. A bit of it can go a long way, if one's careful.Btw, guys, configuration options for the index? these would be awesome for us if we still had the triggers ;)
Those are actually for the purpose of special configuration of the index itself (storage behavior, etc).
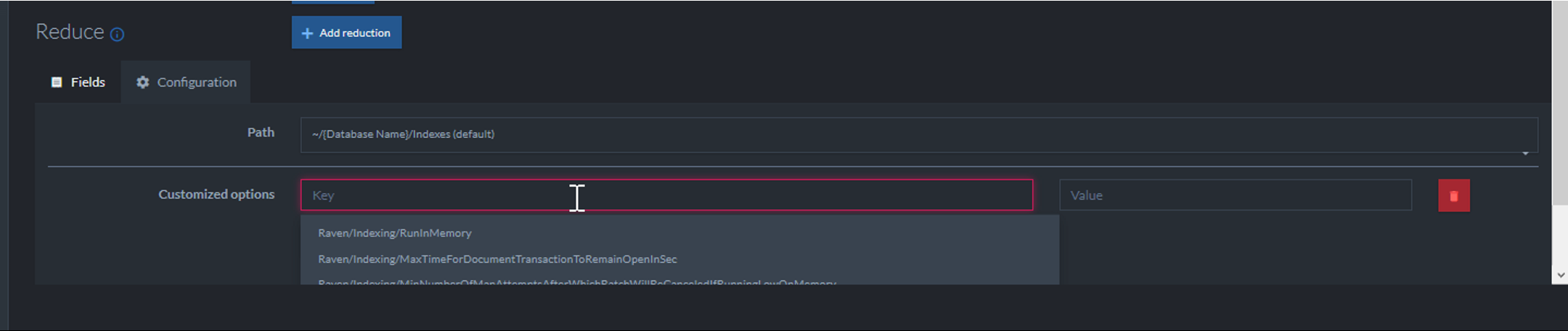
Yeah, I got that :) I just remember searching for something like that to "hijack" when we did our extensions.
Oren Eini (Ayende Rahien)
Jun 14, 2017, 6:01:44 AM6/14/17
to ravendb
This is a bit problematic.One of the reasons we want to move this code to the database level is that we can take care of spinning it into the cluster as a whole.If you reference additional assemblies, you'll need to also ensure that the binaries are deployed properly on all the nodes.Ah, yes, I get that.If this is just for these kind of dependencies, I wouldn't mind handling this myself (if we need to restart the server for it to pick up the new assemblies it wouldn't be too much of an issue) but then again, I haven't had to deal with clusters so far, so I might just be blind to the issues.
Yes, I think that would be the way to go, yes.
We'd still need to be able to store the Name so we can load the doc from the index directly, I'm not sure if that would be an issue.Not following?
I don't know what AnalyzeForLanguage or Index would return. If it's lucene terms to be stored on the lucene document, some object representing both what we intend to store and what we intend to search on, an array of strings that are analyzed.
Same as anything that is analyzed. You can create a lucene field directly, pass an array, whatever you want.
We'll handle it in the same manner.
Perhaps it's easier if I just say that "I want to be able to search on Title for 'reader', find 'reading a book', and have the query result be read from the index itself".
Isn't that done by projecting from the index?
If "Index" or "AnalyzeForLanguage" causes the original field to be lost (because raven would just use whatever it returns to store on the lucene document), we wouldn't be able to read the Title from the index
Oh, you can just return an array with a stored field that isn't indexed, and then all the terms you want to be indexed.
Bruno Lopes
Sep 19, 2017, 2:31:35 PM9/19/17
to RavenDB - 2nd generation document database
Hey guys,
Is there any support for server-side code like the one mentioned here on the RC, or planned for RTM?
We're revisiting this in order to see how/when/if we'll move from 3.5.
Thanks
Oren Eini (Ayende Rahien)
Sep 19, 2017, 2:52:31 PM9/19/17
to ravendb
We have added the ability to supply your own code that will be compiled with your index.
The UI for that isn't plugged in, though.
Hibernating Rhinos Ltd
Oren Eini l CEO l Mobile: + 972-52-548-6969
Office: +972-4-622-7811 l Fax: +972-153-4-622-7811
--
You received this message because you are subscribed to the Google Groups "RavenDB - 2nd generation document database" group.
To unsubscribe from this group and stop receiving emails from it, send an email to ravendb+unsubscribe@googlegroups.com.
Bruno Lopes
Sep 20, 2017, 7:02:03 AM9/20/17
to RavenDB - 2nd generation document database
Cheers, will look into this.
Any way to do it on the database level? We might have code that's common between several indexes.
Any way to do it on the database level? We might have code that's common between several indexes.
To unsubscribe from this group and stop receiving emails from it, send an email to ravendb+u...@googlegroups.com.
Oren Eini (Ayende Rahien)
Sep 20, 2017, 9:25:58 AM9/20/17
to ravendb
No, by design, since that avoids versioning issues.
On the client side, you can just reference the same source files, of course.
To unsubscribe from this group and stop receiving emails from it, send an email to ravendb+unsubscribe@googlegroups.com.
Bruno Lopes
Sep 26, 2017, 12:00:09 PM9/26/17
to RavenDB - 2nd generation document database
Would we be able to create extension methods on the extension?
Currently MethodDynamicParametersRewriter clobbers all over the parameter list and so this approach fails.
Wrapping the object on a method call also doesn't seem to work, but I havent' looked too much into that.
Oren Eini (Ayende Rahien)
Sep 26, 2017, 12:33:35 PM9/26/17
to ravendb
To unsubscribe from this group and stop receiving emails from it, send an email to ravendb+unsubscribe@googlegroups.com.
Bruno Lopes
Sep 27, 2017, 5:54:24 AM9/27/17
to RavenDB - 2nd generation document database
Cool, thanks.
Do you guys have any ideas regarding not duplicating the code between the AdditionalSources string and "real code"?
I'm exploring how to do that (since this can be a pain point), and if you have figured it out it would spare me a bit of work :)
Oren Eini (Ayende Rahien)
Sep 27, 2017, 5:56:04 AM9/27/17
to ravendb
You can use a single file and register it once as a resource and once as code.
Then use that
To unsubscribe from this group and stop receiving emails from it, send an email to ravendb+unsubscribe@googlegroups.com.
Bruno Lopes
Sep 27, 2017, 6:44:42 AM9/27/17
to RavenDB - 2nd generation document database
That's... straightforward. I'm glad I ask, thanks :)
Reply all
Reply to author
Forward
0 new messages