Integration into currently planned architecture
87 views
Skip to first unread message

Blaž Križaj
Mar 4, 2015, 9:52:26 AM3/4/15
to raft...@googlegroups.com
Hi,
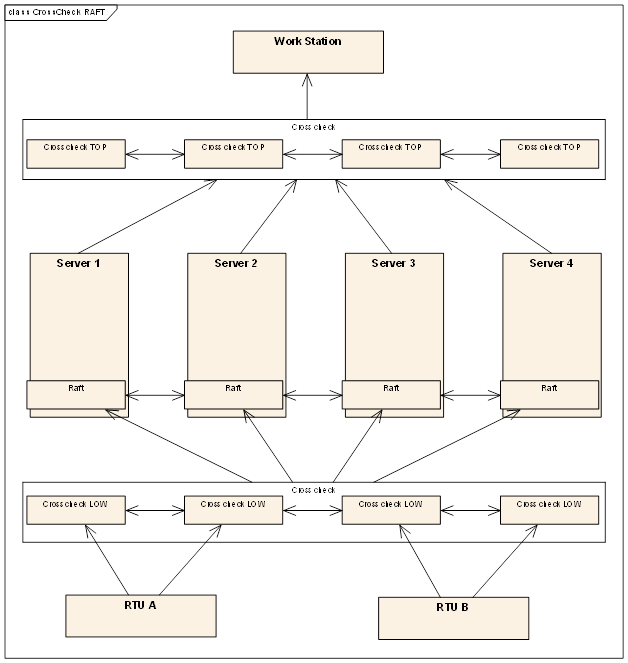
I am trying to decide whether raft fulfills all our main requirements. I will try to describe the current situation I am dealing with and hopefully you guys with experiences could help me. If this isn't the right place to do so, I do apologize and just ignore written bellow but do let me know if such place exists :) During my description I will try to bold my main concerns.
Our main requirement on the project is safety therefore distributed system is kinda of a must. I have been reading a lot about distributed system for the past few days and during that time also came across raft (and paxos beforehand). Everything is great, I'm just not sure if such an algorithm fulfills our safety requirements. Note that I haven't yet gone into code since it's far to early to do so.
Our system is divided into three units:
- RTU
- Server
- WorkStation
RTUs and WorkStations can be considered as clients in raft scenarios which initiate requests and server is considered as state machine processing the requests. Every request (input) and respond (output) must be cross checked to secure safe information to the WorkStation presenting (GUI) the current Server state. Does raft fulfill cross checking requirement?
RTUs are divided into two separated channels communicating with 2 servers on each channel, having four servers. Does raft operate with four servers or does the number of state machines have to odd number? Those two channels provide the same inputs in same sequence but with some extra delay on one of the channels. Note that Servers are pooling the data from RTUs and not the other way around. Probably some kind of extra mechanism would be required here to cross check the data in then trigger the processing of the inputs via leading Server?
In the next step raft algorithm would insure deterministic state and provide graphical response to the connected WorkStation(s). In this step the response should also be cross checked to detect any faulty processing. Does this require Byzantine fault tolerance or is raft sufficient?
I am ignoring the other direction (WorkStation->Server->RTU) but it's mostly dealing with same kind of processing.
Oh one more thing, we decided to go with 4 server architecture (before analyzing current world knowledge of distributed systems) to avoid dealing with any memory and CPU tests during run time. If faulty data is detected on 1-3 of the 4 servers, system is still operational with exception of executing safety relevant commands. We haven't yet discussed how would the faulty detection take place in this case. As you can see many unclear things came up and many more may follow after those are cleared.
Do you think such things are solved "simply" by using consensus algorithms such as raft or are out requirements waaay out of this league, hopefully not! :)
Hopefully I have described my questions clear enough. Attaching picture for better understanding. Thank you.

Diego Ongaro
Mar 5, 2015, 12:31:51 PM3/5/15
to Blaž Križaj, raft...@googlegroups.com
Hi Blaž,
I don't think I understand the requirements well enough. Specifically,
what is the exact purpose of cross-checking? It sounds like you may be
trying to build a Byzantine fault tolerant system, in which case I'd
recommend Miguel Castro and Barbara Liskov's PBFT work:
http://pmg.csail.mit.edu/papers/osdi99.pdf
-Diego
> --
> You received this message because you are subscribed to the Google Groups
> "raft-dev" group.
> To unsubscribe from this group and stop receiving emails from it, send an
> email to raft-dev+u...@googlegroups.com.
> For more options, visit https://groups.google.com/d/optout.
I don't think I understand the requirements well enough. Specifically,
what is the exact purpose of cross-checking? It sounds like you may be
trying to build a Byzantine fault tolerant system, in which case I'd
recommend Miguel Castro and Barbara Liskov's PBFT work:
http://pmg.csail.mit.edu/papers/osdi99.pdf
-Diego
> You received this message because you are subscribed to the Google Groups
> "raft-dev" group.
> To unsubscribe from this group and stop receiving emails from it, send an
> email to raft-dev+u...@googlegroups.com.
> For more options, visit https://groups.google.com/d/optout.
Message has been deleted
Blaž Križaj
Mar 5, 2015, 4:32:04 PM3/5/15
to raft...@googlegroups.com, blaz....@gmail.com
Ye, was kinda worried about that.
Cross check process in this case insures all state machines are receiving same input from RTUs and insures all state machines came to same result/respond while processing the input. Would Byzantine fault tolerant system insure such requirement? I was reading this work which you suggested few posts ago: http://www.scs.stanford.edu/14au-cs244b/labs/projects/copeland_zhong.pdf.
Please let me know if you need more info, I am more then happy to provide you details.
Blaž Križaj
Mar 6, 2015, 4:34:48 AM3/6/15
to raft...@googlegroups.com, blaz....@gmail.com
Oh one more thing I forgot to mention. The reason we are trying to have such mechanism is so we could detect faulty replica, mark it as appropriately and ignore it till fixed. No clue what fixing procedure would actually do, maybe just restart the state machine? We haven't tough about that much, it might be that our requirements just aren't reasonable enough. If restart would take place, log replication algorithm could be used to restore the state of restarted state machine.
With that in mind, we could bypass the majority algorithm and just work with safe replicas in so called unsafe state and still provide graphical presentation of the current state to the clients (WorkStations). There is one downside to such architecture which I am trying to somehow workaround which is that there is no way one can detect safe/unsafe replica in 2:2 case i.e. where two servers process different result as the other two.
As stated above requirements that we are dealing could still be a matter of change if found that they aren't able to be realized. I find it strange that others aren't dealing with such requirements making me think that we are just asking for too much or asking for something that isn't even useful?
Currently reading the paper you provided. Thank you for your time.
On Thursday, 5 March 2015 18:31:51 UTC+1, Diego Ongaro wrote:

{kind=link}
Oren Eini (Ayende Rahien)
Mar 6, 2015, 4:46:01 AM3/6/15
to Blaž Križaj, raft...@googlegroups.com
Do you have the potential for _BAD_ nodes?
Nodes that are intentionally trying to game the system?
Hibernating Rhinos Ltd
Oren Eini l CEO l Mobile: + 972-52-548-6969
Office: +972-4-622-7811 l Fax: +972-153-4-622-7811
Blaž Križaj
Mar 6, 2015, 5:56:20 AM3/6/15
to raft...@googlegroups.com, blaz....@gmail.com
What do you mean by game the system? We have a potential of having a corrupted memory, CPU and such which could result in faulty processing (in theory). Oh btw, also forgot to mention that network is of closed type if that by any chance makes and difference.
Oren Eini (Ayende Rahien)
Mar 6, 2015, 6:51:37 AM3/6/15
to Blaž Križaj, raft...@googlegroups.com
There is a limit manner of ways that a process can fail. And most of them aren't going to cause your software to work in random ways.
That means that you don't need to protect yourself from rouge client, so you don't need cross checking.
Blaž Križaj
Mar 6, 2015, 7:27:55 AM3/6/15
to raft...@googlegroups.com, blaz....@gmail.com
Using Raft or Byzantine Fault Tolerance Raft? I do agree with you, is there any proof for that statement? I am currently reading paper Diego posted, not finished yet but on page 3 it says, quote:
"The algorithm works roughly as follows:
1. A client sends a request to invoke a service operation
to the primary
2. The primary multicasts the request to the backups
3. Replicas execute the request and send a reply to the
client
4. The client waits for 1 replies from different
replicas with the same result; this is the result of
the operation.
Like all state machine replication techniques [34],
we impose two requirements on replicas: they must
be deterministic (i.e., the execution of an operation in
a given state and with a given set of arguments must
always produce the same result) and they must start in the
same state."
Note: Primary is leader, backups are followers.
This seems like a cross checking process to me. In Raft nothing is mentioned about client receiving more then one result from the replicas but only from leader or did I miss something out?
Oren Eini (Ayende Rahien)
Mar 6, 2015, 8:04:03 AM3/6/15
to Blaž Križaj, raft...@googlegroups.com
Nope, only the leader is sending the result to the client.
The replicas are also running the same code, but they don't send result to the client.
The client get a single result.
Blaž Križaj
Mar 6, 2015, 8:28:49 AM3/6/15
to raft...@googlegroups.com, blaz....@gmail.com
OK, I didn't miss anything important then. So you are saying that cross checking isn't required for Raft but as stated above is provided by Byzantine Fault Tolerant system mentioned by Diego.
Just to sum it all up, you are saying that even tho state replicas can't provide a 100% safe node status because of memory, CPU corruptions cross checking isn't required. If so, is there any proof, written paper about it I could check?
Oren Eini (Ayende Rahien)
Mar 6, 2015, 8:36:47 AM3/6/15
to Blaž Križaj, raft...@googlegroups.com
What is 100% safe node status?
A replica can be behind the leader (sometimes by a lot), but it is always consistent in the sense that everything happens in the same order.
Blaž Križaj
Mar 6, 2015, 9:08:08 AM3/6/15
to raft...@googlegroups.com, blaz....@gmail.com
They can't trust each other e.g. some node can process request differently for what so ever reason, doesn't even have to be leader node.
Diego Ongaro
Mar 10, 2015, 5:15:19 PM3/10/15
to Blaž Križaj, raft...@googlegroups.com, Oren Eini (Ayende Rahien)
Guys, please try to be clear about when you're talking about Raft
(which handles omission failures) and when you're talking about other
approaches that handle Byzantine=arbitrary failures.
Blaž, if you're worried about undetected corruptions in
memory/CPU/disk, those failures are considered Byzantine. Since Raft
doesn't address Byzantine faults, Raft cannot guarantee that they will
not affect correctness (but you might get lucky, or a checksum might
catch it). On the other hand, Byzantine fault tolerant algorithms
typically guarantee correctness even if up to f of the servers
experience arbitrary failures for a cluster size >= 3f+1.
If we could all get Byzantine fault tolerance for free, we'd be doing
it. There's a cost in complexity and performance, however, so many
people settle for simpler algorithms that only handle omission
failures instead.
-Diego
(which handles omission failures) and when you're talking about other
approaches that handle Byzantine=arbitrary failures.
Blaž, if you're worried about undetected corruptions in
memory/CPU/disk, those failures are considered Byzantine. Since Raft
doesn't address Byzantine faults, Raft cannot guarantee that they will
not affect correctness (but you might get lucky, or a checksum might
catch it). On the other hand, Byzantine fault tolerant algorithms
typically guarantee correctness even if up to f of the servers
experience arbitrary failures for a cluster size >= 3f+1.
If we could all get Byzantine fault tolerance for free, we'd be doing
it. There's a cost in complexity and performance, however, so many
people settle for simpler algorithms that only handle omission
failures instead.
-Diego
Reply all
Reply to author
Forward
0 new messages