scikit-learn as optional dependency - case: covariances
37 views
Skip to first unread message

josef...@gmail.com
Sep 18, 2016, 12:26:55 PM9/18/16
to pystatsmodels
One set of tools that we need for various models are covariance or
precision (inverse covariance) estimators that are penalized,
sparsified or robust to outliers. (*)
I was looking at the related scikit-learn functionality and that's too
much code and implementation details to copy or duplicate it in
statsmodels.
So, I think it would be useful to add scikit-learn as optional
dependency and wrap it for some optional alternative implementation or
methods. A possible pattern would be to have a simple version of our
own, and delegate fancier methods to scikit-learn.
One implementation detail is for example cross-validation and the
choice of regularization, shrinkage or thresholding. I don't know
whether it's a theoretical or an implementation problem, but k-fold
likelihood cross-validation doesn't seem to work well if the data has
nobs > k_vars.
I ran into CV problems in
https://github.com/statsmodels/statsmodels/issues/3197 but I also seem
to run into problems with scikit-learn GraphLassoCV.
an example based on the scikit-learn example with larger nobs and less sparsity
n_samples = 600
n_features = 20
alpha=0.7 # sparsity in random sample
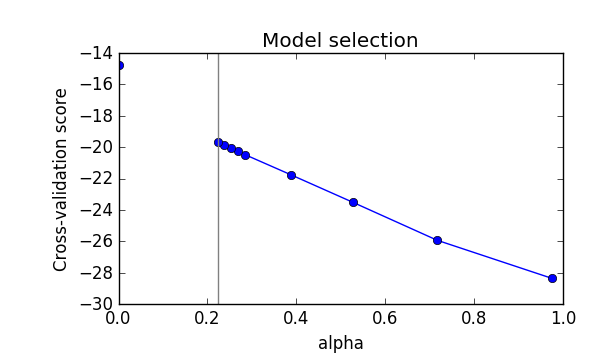
graph lasso cross-validation doesn't converge for small positive
regularization and over sparsifies. In the range that CV is plotted,
the CV score looks monotonic decreasing.
The Ledoit-Wolf estimate in the plot has been changed to thresholding
at a semi arbitrary partial correlation threshold of 0.05, and that
looks good
>>> (prec == 0).mean() # true, data generating zero entries in inverse covariance (precision) matrix
0.40999999999999998
>>> (lwp == 0).mean() # zeros in thresholded ledoit_wolf precision matrix
0.39500000000000002
>>> ((lwp == 0) & (prec == 0)).mean() common
0.34999999999999998
>>> ((lwp != 0) & (prec == 0)).mean() false non-zeros
0.059999999999999998
>>> ((lwp == 0) & (prec != 0)).mean() false zeros
0.044999999999999998
----
(*)
sparse: there is no way to estimate an even a bit larger VAR or VECM
model without a lot of sparsity. sparse inverse covariance is needed
for efficient estimation
outlier robust: We need a robust version of something like Mahalanobis
distance to remove the distorting effect influential outlier
observations.
penalized/shrunk: We need regularized covariances, shrunk but not
necessarily sparse, when we cannot estimate covariances with good
statistical precision, e.g. for robust sandwich covariance, GMM
weights or GEE correlations.
Josef
precision (inverse covariance) estimators that are penalized,
sparsified or robust to outliers. (*)
I was looking at the related scikit-learn functionality and that's too
much code and implementation details to copy or duplicate it in
statsmodels.
So, I think it would be useful to add scikit-learn as optional
dependency and wrap it for some optional alternative implementation or
methods. A possible pattern would be to have a simple version of our
own, and delegate fancier methods to scikit-learn.
One implementation detail is for example cross-validation and the
choice of regularization, shrinkage or thresholding. I don't know
whether it's a theoretical or an implementation problem, but k-fold
likelihood cross-validation doesn't seem to work well if the data has
nobs > k_vars.
I ran into CV problems in
https://github.com/statsmodels/statsmodels/issues/3197 but I also seem
to run into problems with scikit-learn GraphLassoCV.
an example based on the scikit-learn example with larger nobs and less sparsity
n_samples = 600
n_features = 20
alpha=0.7 # sparsity in random sample
graph lasso cross-validation doesn't converge for small positive
regularization and over sparsifies. In the range that CV is plotted,
the CV score looks monotonic decreasing.
The Ledoit-Wolf estimate in the plot has been changed to thresholding
at a semi arbitrary partial correlation threshold of 0.05, and that
looks good
>>> (prec == 0).mean() # true, data generating zero entries in inverse covariance (precision) matrix
0.40999999999999998
>>> (lwp == 0).mean() # zeros in thresholded ledoit_wolf precision matrix
0.39500000000000002
>>> ((lwp == 0) & (prec == 0)).mean() common
0.34999999999999998
>>> ((lwp != 0) & (prec == 0)).mean() false non-zeros
0.059999999999999998
>>> ((lwp == 0) & (prec != 0)).mean() false zeros
0.044999999999999998
----
(*)
sparse: there is no way to estimate an even a bit larger VAR or VECM
model without a lot of sparsity. sparse inverse covariance is needed
for efficient estimation
outlier robust: We need a robust version of something like Mahalanobis
distance to remove the distorting effect influential outlier
observations.
penalized/shrunk: We need regularized covariances, shrunk but not
necessarily sparse, when we cannot estimate covariances with good
statistical precision, e.g. for robust sandwich covariance, GMM
weights or GEE correlations.
Josef
{kind=link}
{kind=link}
Reply all
Reply to author
Forward
0 new messages