Pentaho 8 - soon available
82 views
Skip to first unread message

Pedro Alves
Oct 30, 2017, 7:05:35 AM10/30/17
to pentaho-...@googlegroups.com
Forgot to send here, blogger last week at http://pedroalves-bi.blogspot.com/2017/10/pentaho80.html
-------------
Pentaho 8!

The first of a new Era
Wow - time flies... Another Pentaho World this week, and another blog post announcing another release. This time... the best release ever! ;)
This is our first Pentaho product announcement since we became Hitachi Vantara - and you'll see that some synergies are already appearing. And as I said before, again and again... the Community Edition is still around! We're not kidding - we're here to rule the world and we know it's though an open source core strategy that we'll get there :)
Pentaho 8.0 In a nutshell
Ok, let's get on with this cause there's a lot of people at the bar calling me to have a drink. And I know my priorities!
- Platform and Scalability
- Worker Nodes
- New theme
- Data Integration
- Streaming support!
- Run configurations for Jobs
- Filters in Data Explorer
- New Open / Save experience
- Big Data
- Improvements on AEL
- Big Data File Formats - Avro and Parquet
- Big Data Security - Support for Knox
- VFS improvements for Hadoop Clusters
- Others
- Ops Mart for Oracle, MySQL, SQL Server
- Platform password security improvements
- PDI mavenization
- Documentation changes on help.pentaho.com
- Feature Removals:
- Analyzer on MongoDB
- Mobile Plug-in (Deprecated in 7.1)
Is it done? Can I go now? No?.... damn, ok, now on to further details...
Platform and Scalability
Worker Nodes (EE)
This is big. I never liked the way we handled scalability in PDI. Having the ETL designer responsible for manually defining the slave server in advance, having to control the flow of each execution, praying for things not to go down... nah! Also, why ETL only? What about all the other components of the stack?
So a couple of years ago, after getting info from a bunch of people I submitted a design document with a proposal for this:

This was way before I knew the term "worker nodes" was actually not original... but hey, they're nodes, they do work, and I'm bad with names, so there's that... :p
It took time to get to this point, not because we didn't think this was important, but because of the underlying order of execution; We couldn't do this without merging the servers, without changing the way we handle the repository, without having AEL (the Adaptive Execution Layer). Now we got to it!
Fortunately, we have an engineering team that can execute things properly! They took my original design, took a look at it, laughed at me, threw me out of the room and came up with the proper way of doing things. Here's the high-level description:
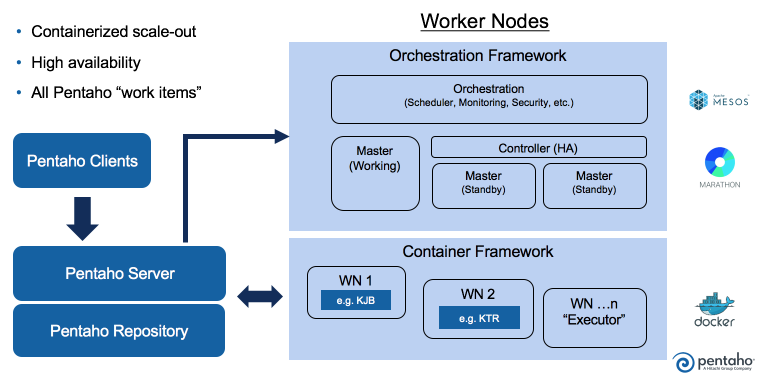
This is where I mentioned that we are already leveraging Hitachi Vantara resources. We are using Lumada Foundryfor worker nodes. Foundry is a platform for rapid development of service-based applications delivering the management of containers, communications, security, and monitoring toward creating enterprise products/applications, leveraging technology like docker, mesos, marathon, etc. More on this later, as it's something we'll be talking a lot more about...
Here's some of the features
- Deploy consistently in physical, virtual and cloud environments
- Scale and load balance services , helping to deal with peaks and limited time-windows, allocate the resources that are needed.
- Hybrid deployments can be used to distribute load, even when the on-premise resources are not sufficient, scaling out into the Cloud is possible to provide more resources.
So, how does this work in practice? Once you have a Pentaho Server installed, you can configure it to connect to the cluster of Pentaho Worker nodes. From that point on - things will work! No need to configure access to repositories, accesses, funky stuff. You only need to say "Execute at scale" and if the worker nodes are there, it's where things will be executed. Obviously, the "things will work" will have to obey the normal rules of clustered execution, for instance, don't expect a random node on the cluster to magically find out your file:///c:/my computer/personal files/my mom's excel file.xls.... :/
So what scenarios will this benefit the most? A lot! Now your server will not be bogged down executing a bunch of jobs and transformations as they will be handed out for execution in one of the nodes.
This does require some degree of control, because there may be cases where you don't want remote execution (for instance, a transformation to feed a dashboard). This is where Run Configurations come into play. Also important to note that even though the biggest benefits of this will be ETL work, this concept is for any kind of execution.
This a major part of the work we're doing with the Hitachi Vantara team; By leveraging Foundry we'll be able to do huge improvements on areas we've been wanting to tackle for a while but never were able to properly address on our own: better monitoring, improving lifecycle management and active-active HA, among others. In 8.0 we leapfrogged in this worker nodes story, and we expect much more going forward!
New Theme - Ruby (EE/CE)
One of the things you'll notice is that we have a new theme that reflects the Hitachi Vantara colors. The new theme is the default on new installations (not for upgrades) and the others are still available
Data Integration
Streaming Support: Kafka (EE/CE)
In Pentaho 8.0 we're introducing proper streaming support in PDI! In case you're thinking "hum... but don't we already have a bunch of steps for streaming datasources? JMS, MQTT, etc?" you're not wrong. But the problem is that PDI is a micro batching engine, and these streaming protocols introduce issues that can't be solved with the current approach. Just think about it - a streaming datasource requires an always running transformation, and in PDI execution all steps run in different threads while the data pipeline is being processed; There are cases, when something goes wrong, where we don't have the ability to do proper error processing. It's simply not as simple as a database query or any other call where we get a finite and well known amount of data.
So we took a different approach - somewhat similar to sub-transformations but not quite... First of all, you'll see a new section in PDI:

Kafka is the one that was prioritized as being the most important for now, but this will actually be something that will be extended for other streaming sources.
The secret here is on the Kafka Consumer step:
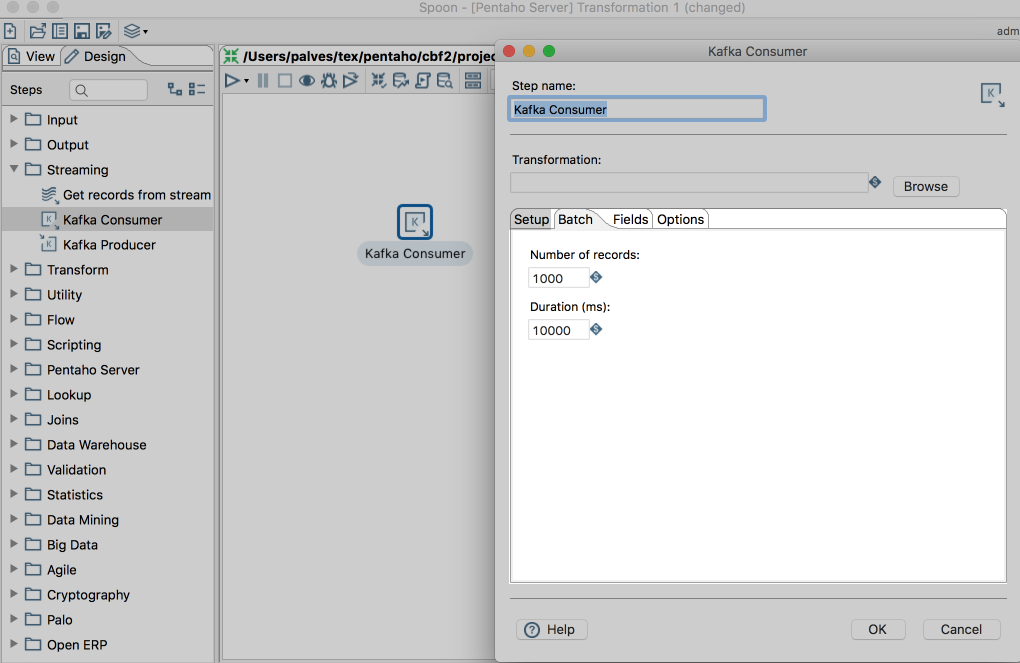
The highlighted tabs should be generic for pretty much all the steps, and the Batch is what controls the flow. So what we did was instead of having an always running transformation at the top level, we break the input data into chunks - either by number of records or duration and the second transformation takes that input, the fields structure and does a normal execution. In here, the abort step was also improved to give you more control the flow of this execution. This is actually something that's been a long standing request from the community - we can now specify if we want to abort with error or without, having an extra ability to control the flow of our ETL.
Here's an example of this thing put together:

Now, even more interesting that that is that this also works in AEL (our Adaptive Execution Layer, introduced in Pentaho 7.1), so when you run this on a cluster you'll get spark native kafka support being executed at scale, which is really nice...
Like I mentioned before, moving forward you'll see more developments here, namely:
- More streaming steps, and currently MQTT seems the best candidate for the short term
- (and my favorite) Developer's documentation with a concrete example so that it's easy for anyone on the community to develop (and hopefully submit) their own implementations without having to worry about the 90% of the stuff that's common to all of them
New Open / Save experience (EE/CE)
In Pentaho 7.0 we merged the servers (no more that nonsense of having a distinct "BA Server" and a "DI Server") and introduced the unified Pentaho Server with a new and great looking experience to connect to it:

but then I clicked on Open file from repository and felt sick... That thing was absolutely horrible and painfully slow. We were finally able to do something about that! Now the experience is ... well... slightly better (as in, I don't feel like throwing up anymore!):
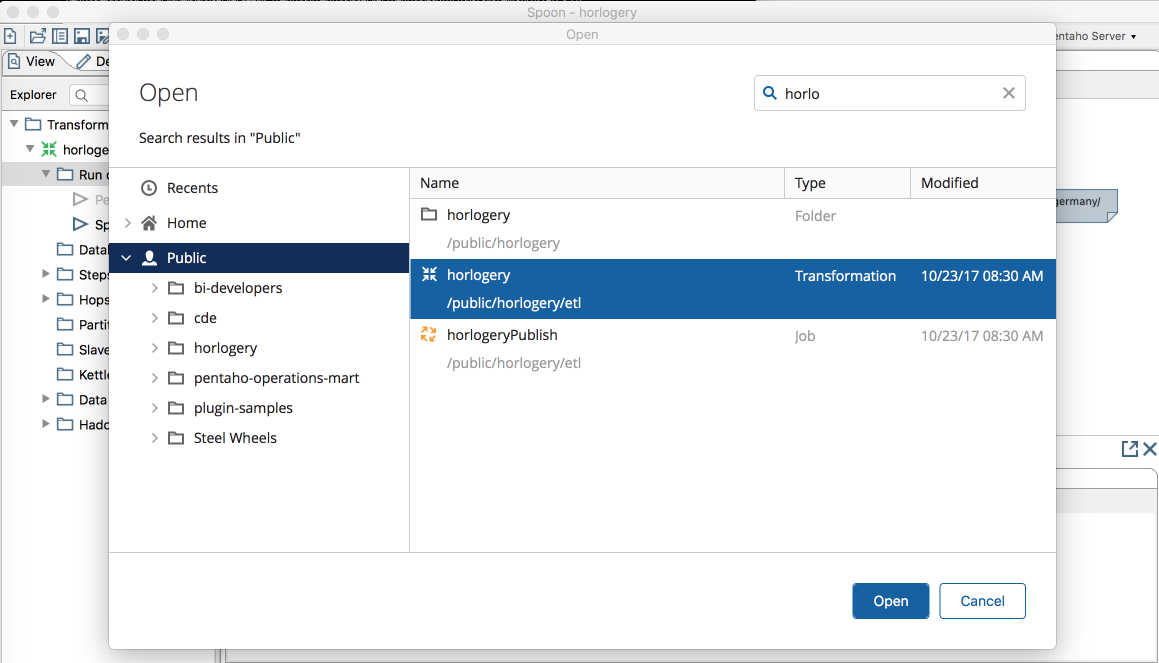
A bit better, no? :) Also with search capabilities and all the kind of stuff that you've been expecting from a dialog like this on the past 10 years! Same for the save experience.
This is another small but IMO always important step in unifying the user experience and work towards a product that gets progressively more pleasant to use. It's a never-ending journey but that's not an excuse not to take it.
Filters in Data Explorer (EE)
Now that I was able to open my transformation, I can show some of the improvements that we did on our Data Explorer experience in PDI. We now support the first set of filters and actions! This one is easy to show but extremely powerful to use.
Here's filters - depending on the data type you'll have a few options, like excluding nulls, equals, greater/lesser than and a few others. Like mentioned, others will come with time.
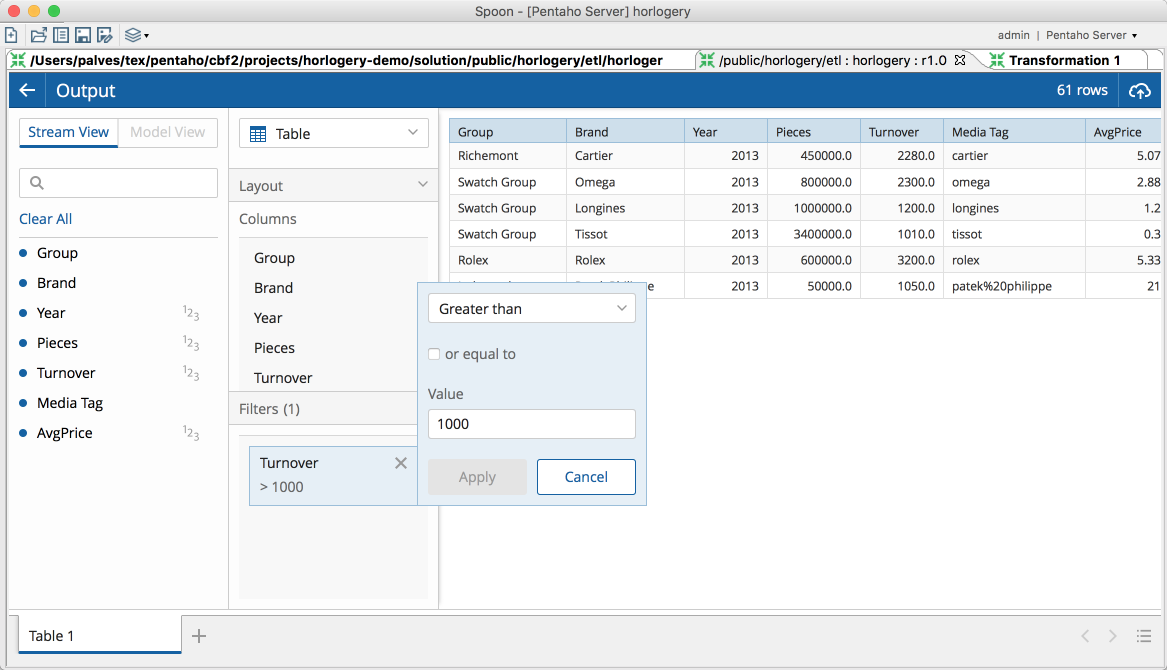
Also, while previous version only allowed for drill down, we can now do more operations on the visualizations.
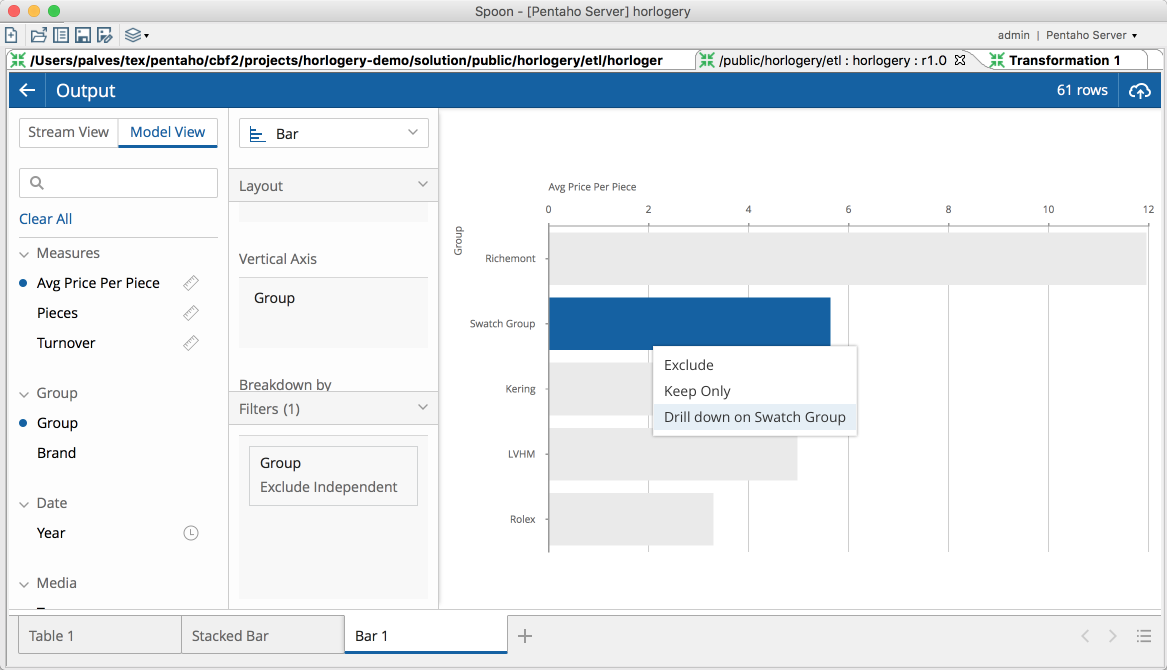
Run configuration: Leveraging worker nodes and execute on server (EE/CE)
Now that we are connected to the repository, opened our transformation with a really nice experience and took benefit of these data exploration improvements to make sure our logic is spot on, we are ready to execute it to the server.
Now this is where the run configuration part comes in. I have my transformation, defined it, played with it, verified that really works as expected on my box. And now, I will want to make sure it also runs well on the server. What before was a very convoluted process, it's now much simplified.
What I do is define a new Run Configuration, like described in 7.1 for AEL, but with a little twist: I don't want it to use the spark engine; I want it to use the pentaho engine but on the server, not the one local to spoon:
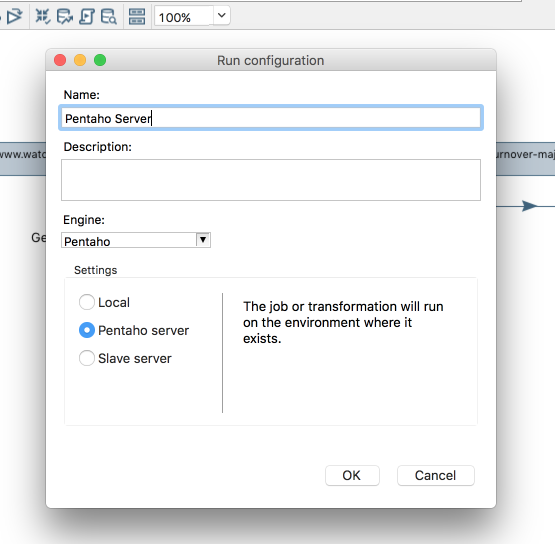
Now, what happens when I execute this selecting the Pentaho Server run configuration?

Yep, that!! \o/

This screenshot shows PDI trigger the execution and my Pentaho Server console logging it's execution.
And if I had worker nodes configured, what I would see would be my Pentaho Server automatically dispatching the execution of my transformation to an available worker node!
This doesn't apply to the immediate execution only; We can now specify the run configuration on the job entry as well, allowing a full control of the flow of our more complex ETL
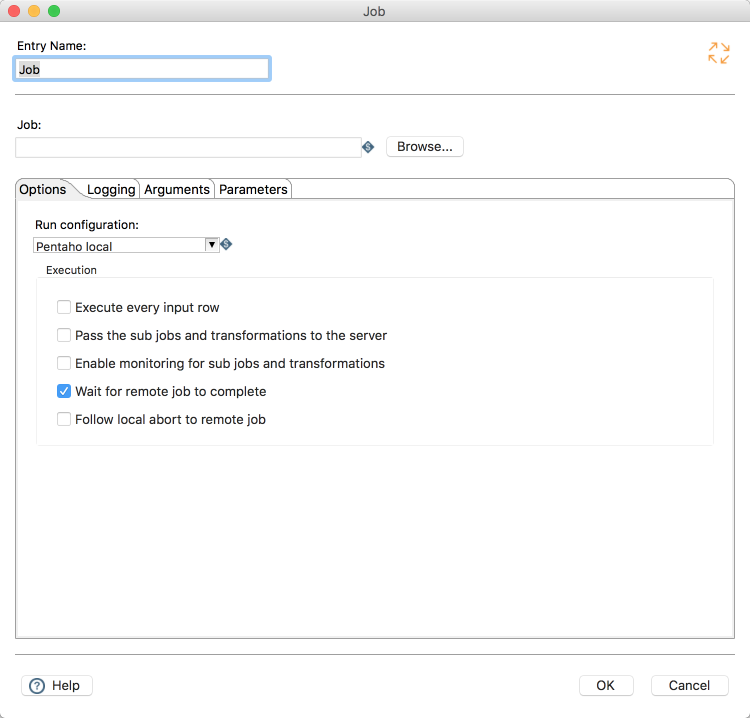
Big Data
Improvements on AEL (EE/CE apart from the security bits)
As expected, a lot of work was done on AEL. The biggest ones:
- Communicates with Pentaho client tools over WebSocket; does NOT require Zookeeper
- Uses distro-specific Spark library
- Enhanced Kerberos impersonation on client-side
This brings a bunch of benefits:
- Reduced number of steps to setup
- Enable fail-over, load-balancing
- Robust error and status reporting
- Customization of Spark jobs (i.e. memory , settings)
- Client to AEL connection can be secured
- Kerberos impersonation from client tool
And not to mention performance improvements... One benchmark I saw that I found particularly impressive is that AEL is practically on pair with native spark execution! And this is impressive! Kudos for the team, just spectacular work!
Big Data File Formats - Avro and Parquet (EE/CE)
Big data platforms introduced various data formats to improve performance, compression and interoperability, and we added full support for these very popular big data formats: Avro and Parquet. Orc will come next.
When you run in AEL, these will also be natively interpreted by the engine, which adds a lot to the value of this.
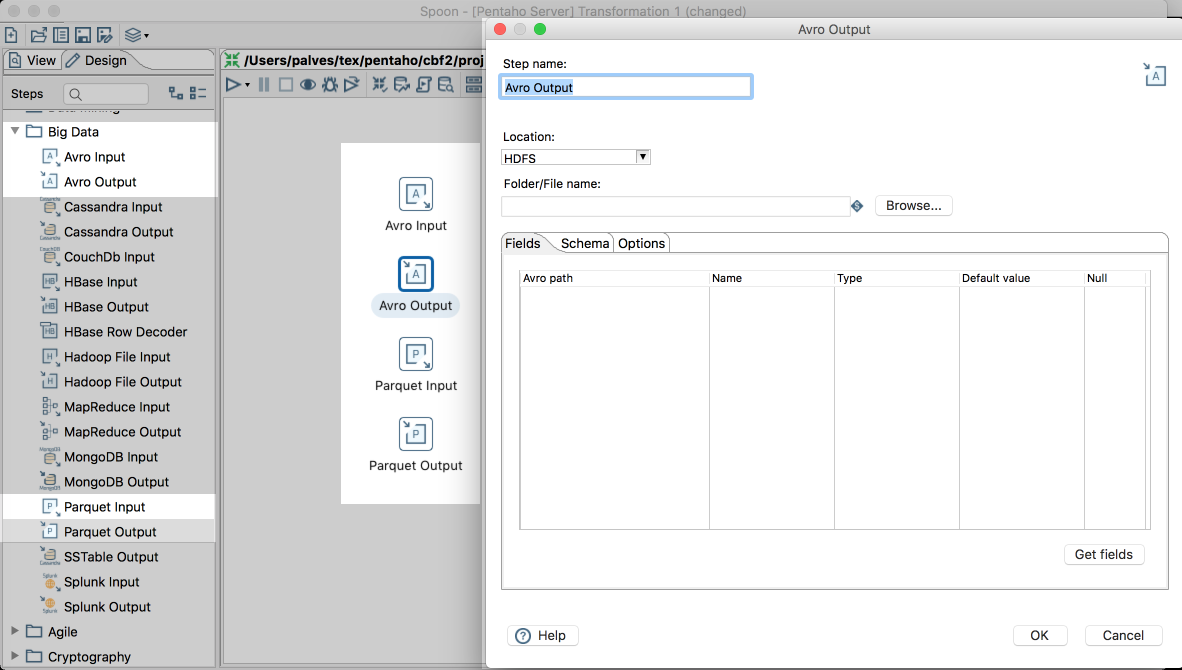
The old steps will still be available on the marketplace but we don't recommend using them.
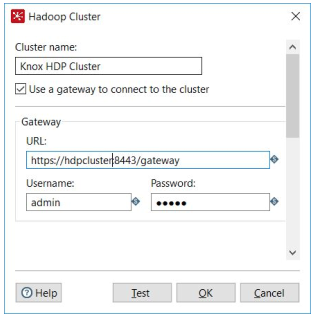
Big Data Security - Support for Knox
Knox provides perimeter security so that the enterprise can confidently extend Hadoop access to more of those new users while also maintaining compliance with enterprise security policies and used in some HortonWorks deployments. It is now supported on the Hadoop Clusters' definition if you enable the property KETTLE_HADOOP_CLUSTER_GATEWAY_CONNECTION on the kettle.properties file.
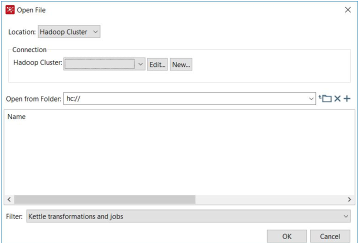
VFS improvements for Hadoop Clusters (EE/CE)
In order to simplify the overall lifecycle of jobs and transformations we made the hadoop clusters available through VFS, on the format hc://hadoop_cluster/.
Others
There are some other generic improvements worth noting
Ops Marts extended support (EE)
Ops Mart now supports Oracle, MySQL and SQL Server. I can't really believe I'm still writing about this thing :(
PDI Mavenization (CE)
Now, this is actually nice! PDI is now fully mavenized. Go to https://github.com/pentaho/pentaho-kettle, do a mvn package and you're done!!!
-----------
Pentaho 8 will be available to download mid-November.
Learn more about Pentaho 8.0 and a webinar here: http://www.pentaho.com/product/version-8-0
Also, you can get a glimpse of PentahoWorld this week watching it live at: http://siliconangle.tv/pentaho-world-2017/
Last but not See you in a few weeks at the Pentaho Community meeting in Mainz! https://it-novum.com/en/pcm17/
That's it - I'm going to the bar!
-pedro
Reply all
Reply to author
Forward
0 new messages