Request for comments: data extension API
96 views
Skip to first unread message

Antonin Delpeuch (lists)
Jul 6, 2017, 5:52:29 PM7/6/17
to OpenRefine
Hi all,
I have finally taken the time to draft a data extension API, to be
implemented by reconciliation services (as an optional feature). This
will let users use their reconciled columns to pull data from the source
database, extending their OpenRefine projects with new columns.
The draft is here:
https://github.com/OpenRefine/OpenRefine/wiki/Data-Extension-API
My main goal in designing this API was to make it as simple as possible
so that many services could implement it easily. There are details at
the end that still need to be specified: feel free to edit the wiki to
propose your solution!
Cheers,
Antonin
I have finally taken the time to draft a data extension API, to be
implemented by reconciliation services (as an optional feature). This
will let users use their reconciled columns to pull data from the source
database, extending their OpenRefine projects with new columns.
The draft is here:
https://github.com/OpenRefine/OpenRefine/wiki/Data-Extension-API
My main goal in designing this API was to make it as simple as possible
so that many services could implement it easily. There are details at
the end that still need to be specified: feel free to edit the wiki to
propose your solution!
Cheers,
Antonin

qi cui
Jul 6, 2017, 8:41:08 PM7/6/17
to OpenRefine, li...@antonin.delpeuch.eu
Not sure if the MQL is really die or not. But I feel partial implementation could be an option if it is technically feasible. At least there is something developer can follow also user is familiar with the language. Come up with something completely new might not be a shortcut unless there is a open standard that can follow to allow implement it in a systematic way.

Thad Guidry
Jul 6, 2017, 9:19:13 PM7/6/17
to OpenRefine
Hi Antonin,
Good work so far on the draft. Makes sense thus far.
Supporting a "limit" property is a requirement as you have noted along with others. Most APIs have this, and if a "no type" was supplied, the endpoint might return 2000 properties to the OpenRefine client, leaving the dialog management to have to filter or constrain the listing of 2000 properties.
My suggestion would be to not hastily make a decision. I know you have some bandwidth and are excited about seeing some progress, but I also want you to take a step back and take in the wider picture of other query languages and perhaps alternative ideas that have been done before.
So...
The only other semi-standard query language that I know of that is also supported on many graph databases already and with lots of client libraries is Gremlin via https://tinkerpop.apache.org/ (examples http://tinkerpop.apache.org/docs/3.0.1-incubating/#traversal )
Gremlin has similar dot notation syntax to GREL.
gremlin> g.V(1).out().values('name')
gremlin> g.V(1).out().map {it.get().value('name')}
gremlin> g.V().filter {it.get().label() == 'person'}
Barak Michener actually wrote the Cayley graph database (inspired by Freebase) and incorporated Gremlin inspired JavaScript query language called Gizmo, as well as a simplified MQL, as well as a GraphQL-inspired query language , so take a look also : https://github.com/cayleygraph/cayley and https://github.com/cayleygraph/cayley/tree/master/query
In the end, I think what will be best for the broader Data Community and even OpenRefine users will be something that is relatively familiar, or at least has familiar approachable syntax, and that allows enough expressivity for the 2 primary functions of any Query language - filtering (where clauses) and limiting...since the assumption of the 3rd function of "extend" will always be that of a intersect or join.
I do not think that tree-like structure of nested objects and properties is always approachable, but certainly that particular MQL way was inspired by JSON in that regard and JSON syntax has proliferated on the internet in the last 10 years.
I don't want to push any particular preference from my side, since I deal with many query languages all day long as a Data Architect, but just wanted you to ponder the above info before you jump head first in any decision. Ultimately, I'd say its your call Antonin, and I think Jacky and I will support your decision either way if given good reasons for your choices.
Thanks and happy hacking dude !
-Thad
--
You received this message because you are subscribed to the Google Groups "OpenRefine" group.
To unsubscribe from this group and stop receiving emails from it, send an email to openrefine+...@googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
Antonin Delpeuch (lists)
Jul 7, 2017, 4:54:27 AM7/7/17
to openr...@googlegroups.com
Hi Jacky,
Thanks for your feedback!
On 07/07/2017 02:41, qi cui wrote:
> Not sure if the MQL is really die or not. But I feel partial
> implementation could be an option if it is technically feasible. At
> least there is something developer can follow
May I ask where?
> also user is familiar with
> the language.
I am sure you are familiar with it, but is this skill really widespread
in our user base? It seems to me that many of our users are librarians
or scientists - it not clear that MQL is known in these communities, as
far as I can tell.
I think one of the main strengths of OpenRefine is that it allows to do
many powerful data transformations without any knowledge of programming
or of query languages. So ideally the underlying query language should
not be exposed to the user (just like the internals of the
reconciliation API are hidden behind human-readable forms).
Of course, power users want to have direct access to flexible APIs. In
that case, the value of a user interface that abstracts away the query
language is more debatable: these power users just want a text area
where they can type their clever query.
> Come up with something completely new might not be a
> shortcut unless there is a open standard that can follow to allow
> implement it in a systematic way.
I would love to reuse an existing standard. My main concern is that
requiring the implementation of a full-blown graph query language (in
addition to the API helpers for property suggestion and auto-completion)
will make it a lot harder for data providers to comply.
Here are a few examples:
- https://github.com/okfn/reconcile-csv creates a reconciliation service
out of a CSV file. That's fantastic! And it would be great if you could
then retrieve columns of the CSV file without having to import the CSV
in OpenRefine and do a join yourself. Do we really want to ask the
maintainer of that tool to implement some version of MQL? Or Gremlin, or
GraphQL? It is clearly overkill for such a simple database and it will
probably just not happen.
- https://github.com/codeforkjeff/conciliator creates reconciliation
interfaces for various databases, for instance ORCID. It does so by
calling the public APIs of these services. Many of these databases are
not graph-based and therefore do not expose any graph query language. Do
we expect maintainers of these reconciliation services to bake their own
MQL engine on top of the poor rate-limited public APIs they have access to?
- the Wikidata community uses primarily SPARQL as a query language. We
could ask Wikimedia Deutschland to implement another query interface to
Wikidata (and indeed, MQL was originally considered for that) but it
seems rather unlikely that this would happen any time soon. I really
believe OpenRefine has a lot of potential in the Wikidata community
(which can provide both users and developers) but if you ask the
community to switch to another query language just for that tool, I fear
that this will really slow down adoption a lot.
Antonin
>
> On Thursday, July 6, 2017 at 5:52:29 PM UTC-4, Antonin Delpeuch (lists)
> wrote:
>
> Hi all,
>
> I have finally taken the time to draft a data extension API, to be
> implemented by reconciliation services (as an optional feature). This
> will let users use their reconciled columns to pull data from the
> source
> database, extending their OpenRefine projects with new columns.
>
> The draft is here:
> https://github.com/OpenRefine/OpenRefine/wiki/Data-Extension-API
> <https://github.com/OpenRefine/OpenRefine/wiki/Data-Extension-API>
>
> My main goal in designing this API was to make it as simple as possible
> so that many services could implement it easily. There are details at
> the end that still need to be specified: feel free to edit the wiki to
> propose your solution!
>
> Cheers,
> Antonin
>
Thanks for your feedback!
On 07/07/2017 02:41, qi cui wrote:
> Not sure if the MQL is really die or not. But I feel partial
> implementation could be an option if it is technically feasible. At
> least there is something developer can follow
> also user is familiar with
> the language.
in our user base? It seems to me that many of our users are librarians
or scientists - it not clear that MQL is known in these communities, as
far as I can tell.
I think one of the main strengths of OpenRefine is that it allows to do
many powerful data transformations without any knowledge of programming
or of query languages. So ideally the underlying query language should
not be exposed to the user (just like the internals of the
reconciliation API are hidden behind human-readable forms).
Of course, power users want to have direct access to flexible APIs. In
that case, the value of a user interface that abstracts away the query
language is more debatable: these power users just want a text area
where they can type their clever query.
> Come up with something completely new might not be a
> shortcut unless there is a open standard that can follow to allow
> implement it in a systematic way.
requiring the implementation of a full-blown graph query language (in
addition to the API helpers for property suggestion and auto-completion)
will make it a lot harder for data providers to comply.
Here are a few examples:
- https://github.com/okfn/reconcile-csv creates a reconciliation service
out of a CSV file. That's fantastic! And it would be great if you could
then retrieve columns of the CSV file without having to import the CSV
in OpenRefine and do a join yourself. Do we really want to ask the
maintainer of that tool to implement some version of MQL? Or Gremlin, or
GraphQL? It is clearly overkill for such a simple database and it will
probably just not happen.
- https://github.com/codeforkjeff/conciliator creates reconciliation
interfaces for various databases, for instance ORCID. It does so by
calling the public APIs of these services. Many of these databases are
not graph-based and therefore do not expose any graph query language. Do
we expect maintainers of these reconciliation services to bake their own
MQL engine on top of the poor rate-limited public APIs they have access to?
- the Wikidata community uses primarily SPARQL as a query language. We
could ask Wikimedia Deutschland to implement another query interface to
Wikidata (and indeed, MQL was originally considered for that) but it
seems rather unlikely that this would happen any time soon. I really
believe OpenRefine has a lot of potential in the Wikidata community
(which can provide both users and developers) but if you ask the
community to switch to another query language just for that tool, I fear
that this will really slow down adoption a lot.
Antonin
>
> On Thursday, July 6, 2017 at 5:52:29 PM UTC-4, Antonin Delpeuch (lists)
> wrote:
>
> Hi all,
>
> I have finally taken the time to draft a data extension API, to be
> implemented by reconciliation services (as an optional feature). This
> will let users use their reconciled columns to pull data from the
> source
> database, extending their OpenRefine projects with new columns.
>
> The draft is here:
> https://github.com/OpenRefine/OpenRefine/wiki/Data-Extension-API
> <https://github.com/OpenRefine/OpenRefine/wiki/Data-Extension-API>
>
> My main goal in designing this API was to make it as simple as possible
> so that many services could implement it easily. There are details at
> the end that still need to be specified: feel free to edit the wiki to
> propose your solution!
>
> Cheers,
> Antonin
>
> --
> You received this message because you are subscribed to the Google
> Groups "OpenRefine" group.
> To unsubscribe from this group and stop receiving emails from it, send
> an email to openrefine+...@googlegroups.com
> <mailto:openrefine+...@googlegroups.com>.
> You received this message because you are subscribed to the Google
> Groups "OpenRefine" group.
> To unsubscribe from this group and stop receiving emails from it, send
> an email to openrefine+...@googlegroups.com
Antonin Delpeuch (lists)
Jul 7, 2017, 5:22:50 AM7/7/17
to openr...@googlegroups.com
Hi Thad,
Thanks a lot for the feedback!
On 07/07/2017 03:18, Thad Guidry wrote:
>
> Supporting a "limit" property is a requirement as you have noted along
> with others. Most APIs have this, and if a "no type" was supplied, the
> endpoint might return 2000 properties to the OpenRefine client, leaving
> the dialog management to have to filter or constrain the listing of 2000
> properties.
That totally makes sense! I will add that to the proposal.
> The only other semi-standard query language that I know of that is also
> supported on many graph databases already and with lots of client
> libraries is Gremlin via https://tinkerpop.apache.org/
> (examples http://tinkerpop.apache.org/docs/3.0.1-incubating/#traversal
> <https://github.com/blazegraph/tinkerpop3> )
Jacky I don't think it would be a smart move to ask reconciliation
services to implement any of these. They are too rich.
I think these query languages would be best supported by dedicated
extensions, just like the existing pull request adds MQL support for
arbitrary endpoints as an extension.
> In the end, I think what will be best for the broader Data Community and
> even OpenRefine users will be something that is relatively familiar, or
> at least has familiar approachable syntax, and that allows enough
> expressivity for the 2 primary functions of any Query language -
> filtering (where clauses) and limiting...since the assumption of the 3rd
> function of "extend" will always be that of a intersect or join.
Look at the existing reconciliation API. I do not think many people use
it manually, and surely most OpenRefine users are not familiar at all
with its syntax (they just deal with it through OpenRefine's interface).
It is not very expressive either (no support of nested properties). But
it is really successful! It is generic enough (it applies naturally to
both relational and graph databases). As a result, we have many
reconciliable data sources, because it is very simple to implement this API.
All I am saying is that it should be possible to pull data exactly in
the same way:
- not requiring any knowledge of a query language for users;
- not requiring compliance to a full-blown standard for data providers.
> I do not think that tree-like structure of nested objects and properties
> is always approachable, but certainly that particular MQL way was
> inspired by JSON in that regard and JSON syntax has proliferated on the
> internet in the last 10 years.
I definitely agree: JSON is the way to go. And I also agree that the
structure of nested objects and properties is not always desirable. The
current proposal assumes a flat structure on objects and properties
(just like the reconciliation service).
>
> I don't want to push any particular preference from my side, since I
> deal with many query languages all day long as a Data Architect, but
> just wanted you to ponder the above info before you jump head first in
> any decision. Ultimately, I'd say its your call Antonin, and I think
> Jacky and I will support your decision either way if given good reasons
> for your choices.
Of course the decision is not mine, we are a community and we need to
decide on what best serves the project as broadly as possible!
Antonin
> +ThadGuidry <https://www.google.com/+ThadGuidry>
Thanks a lot for the feedback!
On 07/07/2017 03:18, Thad Guidry wrote:
>
> Supporting a "limit" property is a requirement as you have noted along
> with others. Most APIs have this, and if a "no type" was supplied, the
> endpoint might return 2000 properties to the OpenRefine client, leaving
> the dialog management to have to filter or constrain the listing of 2000
> properties.
> The only other semi-standard query language that I know of that is also
> supported on many graph databases already and with lots of client
> libraries is Gremlin via https://tinkerpop.apache.org/
> (examples http://tinkerpop.apache.org/docs/3.0.1-incubating/#traversal
>
> Gremlin has similar dot notation syntax to GREL.
>
> gremlin> g.V(1).out().values('name')
> gremlin> g.V(1).out().map {it.get().value('name')}
> gremlin> g.V().filter {it.get().label() == 'person'}
>
> Barak Michener actually wrote the Cayley graph database (inspired by
> Freebase) and incorporated Gremlin inspired JavaScript query language
> called Gizmo, as well as a simplified MQL, as well as a GraphQL-inspired
> query language , so take a look also
> : https://github.com/cayleygraph/cayley and https://github.com/cayleygraph/cayley/tree/master/query
>
These query languages are fantastic, but as explained in my reply to
> Gremlin has similar dot notation syntax to GREL.
>
> gremlin> g.V(1).out().values('name')
> gremlin> g.V(1).out().map {it.get().value('name')}
> gremlin> g.V().filter {it.get().label() == 'person'}
>
> Barak Michener actually wrote the Cayley graph database (inspired by
> Freebase) and incorporated Gremlin inspired JavaScript query language
> called Gizmo, as well as a simplified MQL, as well as a GraphQL-inspired
> query language , so take a look also
> : https://github.com/cayleygraph/cayley and https://github.com/cayleygraph/cayley/tree/master/query
>
Jacky I don't think it would be a smart move to ask reconciliation
services to implement any of these. They are too rich.
I think these query languages would be best supported by dedicated
extensions, just like the existing pull request adds MQL support for
arbitrary endpoints as an extension.
> In the end, I think what will be best for the broader Data Community and
> even OpenRefine users will be something that is relatively familiar, or
> at least has familiar approachable syntax, and that allows enough
> expressivity for the 2 primary functions of any Query language -
> filtering (where clauses) and limiting...since the assumption of the 3rd
> function of "extend" will always be that of a intersect or join.
it manually, and surely most OpenRefine users are not familiar at all
with its syntax (they just deal with it through OpenRefine's interface).
It is not very expressive either (no support of nested properties). But
it is really successful! It is generic enough (it applies naturally to
both relational and graph databases). As a result, we have many
reconciliable data sources, because it is very simple to implement this API.
All I am saying is that it should be possible to pull data exactly in
the same way:
- not requiring any knowledge of a query language for users;
- not requiring compliance to a full-blown standard for data providers.
> I do not think that tree-like structure of nested objects and properties
> is always approachable, but certainly that particular MQL way was
> inspired by JSON in that regard and JSON syntax has proliferated on the
> internet in the last 10 years.
structure of nested objects and properties is not always desirable. The
current proposal assumes a flat structure on objects and properties
(just like the reconciliation service).
>
> I don't want to push any particular preference from my side, since I
> deal with many query languages all day long as a Data Architect, but
> just wanted you to ponder the above info before you jump head first in
> any decision. Ultimately, I'd say its your call Antonin, and I think
> Jacky and I will support your decision either way if given good reasons
> for your choices.
decide on what best serves the project as broadly as possible!
Antonin
> +ThadGuidry <https://www.google.com/+ThadGuidry>
>
>
>
> On Thu, Jul 6, 2017 at 4:52 PM Antonin Delpeuch (lists)
> <li...@antonin.delpeuch.eu <mailto:li...@antonin.delpeuch.eu>> wrote:
>
> Hi all,
>
> I have finally taken the time to draft a data extension API, to be
> implemented by reconciliation services (as an optional feature). This
> will let users use their reconciled columns to pull data from the source
> database, extending their OpenRefine projects with new columns.
>
> The draft is here:
> https://github.com/OpenRefine/OpenRefine/wiki/Data-Extension-API
>
> My main goal in designing this API was to make it as simple as possible
> so that many services could implement it easily. There are details at
> the end that still need to be specified: feel free to edit the wiki to
> propose your solution!
>
> Cheers,
> Antonin
>
> --
> You received this message because you are subscribed to the Google
> Groups "OpenRefine" group.
> To unsubscribe from this group and stop receiving emails from it,
> send an email to openrefine+...@googlegroups.com
> <mailto:openrefine%2Bunsu...@googlegroups.com>.
>
>
> On Thu, Jul 6, 2017 at 4:52 PM Antonin Delpeuch (lists)
> <li...@antonin.delpeuch.eu <mailto:li...@antonin.delpeuch.eu>> wrote:
>
> Hi all,
>
> I have finally taken the time to draft a data extension API, to be
> implemented by reconciliation services (as an optional feature). This
> will let users use their reconciled columns to pull data from the source
> database, extending their OpenRefine projects with new columns.
>
> The draft is here:
> https://github.com/OpenRefine/OpenRefine/wiki/Data-Extension-API
>
> My main goal in designing this API was to make it as simple as possible
> so that many services could implement it easily. There are details at
> the end that still need to be specified: feel free to edit the wiki to
> propose your solution!
>
> Cheers,
> Antonin
>
> --
> You received this message because you are subscribed to the Google
> Groups "OpenRefine" group.
> To unsubscribe from this group and stop receiving emails from it,
> send an email to openrefine+...@googlegroups.com
> --
> You received this message because you are subscribed to the Google
> Groups "OpenRefine" group.
> To unsubscribe from this group and stop receiving emails from it, send
> an email to openrefine+...@googlegroups.com
> <mailto:openrefine+...@googlegroups.com>.
> You received this message because you are subscribed to the Google
> Groups "OpenRefine" group.
> To unsubscribe from this group and stop receiving emails from it, send
> an email to openrefine+...@googlegroups.com
qi cui
Jul 7, 2017, 8:22:49 AM7/7/17
to OpenRefine, li...@antonin.delpeuch.eu
When I say not really die, I mean it could be extended to something else but with different name. My main concern is to adopt something open so user don't have to be locked by one service and one data source.
On Thursday, July 6, 2017 at 5:52:29 PM UTC-4, Antonin Delpeuch (lists) wrote:
Antonin Delpeuch (lists)
Jul 7, 2017, 9:13:42 AM7/7/17
to openr...@googlegroups.com
On 07/07/2017 14:22, qi cui wrote:
>
> This page <https://github.com/nchah/freebase-mql> mentioned: The
> facebook GraphQL
> <https://facebook.github.io/react/blog/2015/05/01/graphql-introduction.html>.
OpenRefine extension which would add GraphQL query capabilities.
But again, I think it would be a burden for data providers if they were
required to implement that. And extracting a fragment of the language
would also be a lot of work.
> When I say not really die, I mean it could be extended to something else
> but with different name.
Sure, MQL's legacy is clearly present in many other languages, so it is
still alive through its offspring! :)
> My main concern is to adopt something open so
> user don't have to be locked by one service and one data source.
I agree that the specification of the protocol have to be freely
available and implementable by anyone.
Antonin
>
> On Thursday, July 6, 2017 at 5:52:29 PM UTC-4, Antonin Delpeuch (lists)
> wrote:
>
> Hi all,
>
> I have finally taken the time to draft a data extension API, to be
> implemented by reconciliation services (as an optional feature). This
> will let users use their reconciled columns to pull data from the
> source
> database, extending their OpenRefine projects with new columns.
>
> The draft is here:
> https://github.com/OpenRefine/OpenRefine/wiki/Data-Extension-API
> <https://github.com/OpenRefine/OpenRefine/wiki/Data-Extension-API>
>
> My main goal in designing this API was to make it as simple as possible
> so that many services could implement it easily. There are details at
> the end that still need to be specified: feel free to edit the wiki to
> propose your solution!
>
> Cheers,
> Antonin
>
>
> This page <https://github.com/nchah/freebase-mql> mentioned: The
> facebook GraphQL
> <https://facebook.github.io/react/blog/2015/05/01/graphql-introduction.html>.
> It is close to MQL. Maybe worth taking a look.
It looks great indeed! I think it would be fantastic to have an
OpenRefine extension which would add GraphQL query capabilities.
But again, I think it would be a burden for data providers if they were
required to implement that. And extracting a fragment of the language
would also be a lot of work.
> When I say not really die, I mean it could be extended to something else
> but with different name.
still alive through its offspring! :)
> My main concern is to adopt something open so
> user don't have to be locked by one service and one data source.
available and implementable by anyone.
Antonin
>
> On Thursday, July 6, 2017 at 5:52:29 PM UTC-4, Antonin Delpeuch (lists)
> wrote:
>
> Hi all,
>
> I have finally taken the time to draft a data extension API, to be
> implemented by reconciliation services (as an optional feature). This
> will let users use their reconciled columns to pull data from the
> source
> database, extending their OpenRefine projects with new columns.
>
> The draft is here:
> https://github.com/OpenRefine/OpenRefine/wiki/Data-Extension-API
> <https://github.com/OpenRefine/OpenRefine/wiki/Data-Extension-API>
>
> My main goal in designing this API was to make it as simple as possible
> so that many services could implement it easily. There are details at
> the end that still need to be specified: feel free to edit the wiki to
> propose your solution!
>
> Cheers,
> Antonin
>
Thad Guidry
Jul 7, 2017, 11:31:53 AM7/7/17
to openr...@googlegroups.com
These query languages are fantastic, but as explained in my reply to
Jacky I don't think it would be a smart move to ask reconciliation
services to implement any of these. They are too rich.
I think these query languages would be best supported by dedicated
extensions, just like the existing pull request adds MQL support for
arbitrary endpoints as an extension.
Oh you must have misunderstood me partially. I was simply trying to educate you a little bit. I completely agree that your need here is to deliver a simple way to extend data, just as we once had with Freebase. We are talking about 2 things.
1. Reconciliation and Extending Data after that fact
2 Querying a Graph Database
Your focus is one # 1 to deliver Reconciliation and extending data with additional data..
Agree that other developers later on can implement # 2 with OpenRefine Extensions to perform SQL, MQL, GraphQL, etc to query databases.
Look at the existing reconciliation API. I do not think many people use
it manually, and surely most OpenRefine users are not familiar at all
with its syntax (they just deal with it through OpenRefine's interface).
It is not very expressive either (no support of nested properties). But
it is really successful! It is generic enough (it applies naturally to
both relational and graph databases). As a result, we have many
reconciliable data sources, because it is very simple to implement this API.
All I am saying is that it should be possible to pull data exactly in
the same way:
- not requiring any knowledge of a query language for users;
- not requiring compliance to a full-blown standard for data providers.
Yeah, they don't use the API directly. OpenRefine is about hiding complexity for our users with a rich tool. In that light, We don't want to make extending your data a complicated mess, or even have to learn and use a query language or even know GREL syntax for that matter. A simple dialog should suffice, and where that dialog can get smarter as the backend gets smarter as well (your API code and Wikidata's metadata or others)
I definitely agree: JSON is the way to go. And I also agree that the
structure of nested objects and properties is not always desirable. The
current proposal assumes a flat structure on objects and properties
(just like the reconciliation service).
Cool.
Of course the decision is not mine, we are a community and we need to
decide on what best serves the project as broadly as possible!
Antonin
Well, I agree that what is best is whatever makes it simple for data providers and our users. The requirements are already pretty simple, and we control that without the use of standards if we desire. I understand what Jacky is alluding to about Standards having their place, but my personal take is that sometimes in the life of software projects like OpenRefine...it makes sense to build your own standards...and oftentimes later on they end up becoming useful for the entire world. David Huynh and I saw the Reconcile Service as being a potential standard to implement by others and so that interface was documented and then what do you know...it was implemented by others :)
Antonin, I'd say go forth and continue your development, using a simple dialog to start with, and bring back the essence of what we had with Freebase reconciling and extending data against Wikidata. Others can pick up from that like VIAF, etc.
What Jacky is hinting at is that just try to make that interface of extending users data in OpenRefine using some sort of standard if you can...but honestly, I myself don't think there is one, other than the standard in the database world of an intersect or join function... how we perform that and present that to our OpenRefine users is entirely up to us and we don't have to resort to any specific standard to do so. And we don't even have to expose our users to a Query language either to perform that intersect or join function, but instead could eventually hide it all under the covers with nice dialogs and for power users an API interface underneath that can evolve with time. Your proposal looks fine for accomplishing that.
-Thad
Antonin Delpeuch (lists)
Jul 16, 2017, 7:25:56 AM7/16/17
to openr...@googlegroups.com
A draft implementation is available here:
https://github.com/OpenRefine/OpenRefine/pull/1210
The server-side (Wikidata's reconciliation endpoint) is not optimized
yet so the feature is quite slow. I will optimize it once we agree on an
API.
Feedback welcome!
Antonin
https://github.com/OpenRefine/OpenRefine/pull/1210
The server-side (Wikidata's reconciliation endpoint) is not optimized
yet so the feature is quite slow. I will optimize it once we agree on an
API.
Feedback welcome!
Antonin
Antonin Delpeuch (lists)
Jul 18, 2017, 4:28:28 AM7/18/17
to openr...@googlegroups.com
Thad kindly merged my PR so the feature is available in the official
repository.
Thad & Jacky: do you think it would be possible to add me to the
OpenRefine organization? I would continue to use pull requests in the
same way but that would enable me to work on GitHub issues (cleaning up
existing ones) and GitHub projects (creating one for Wikidata integration).
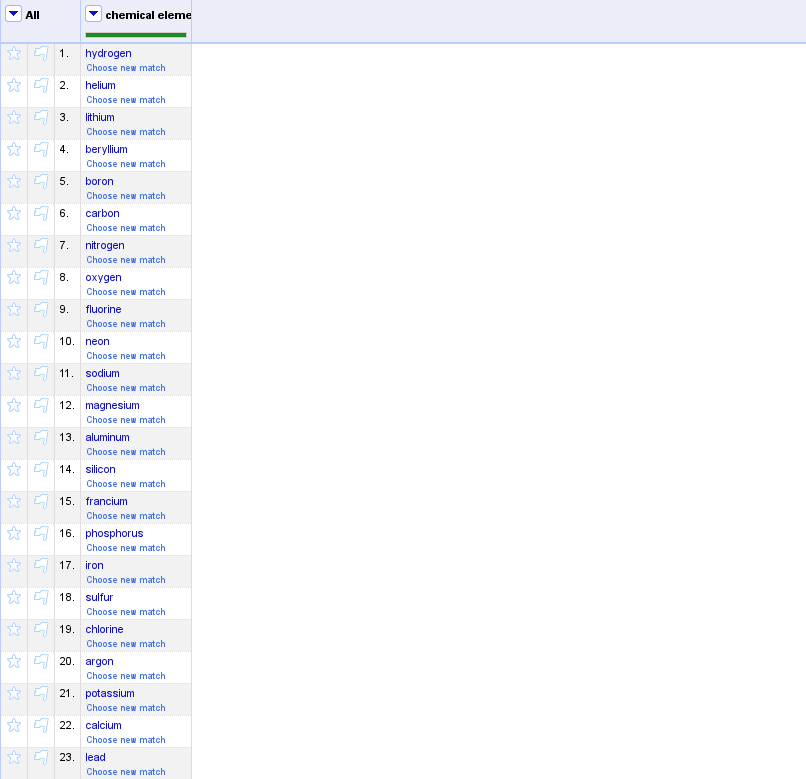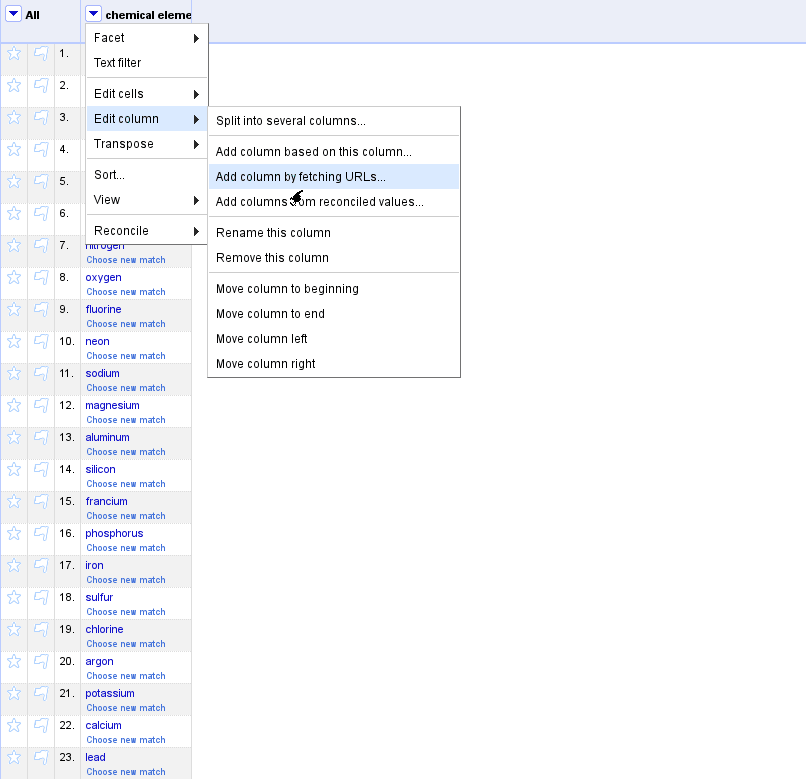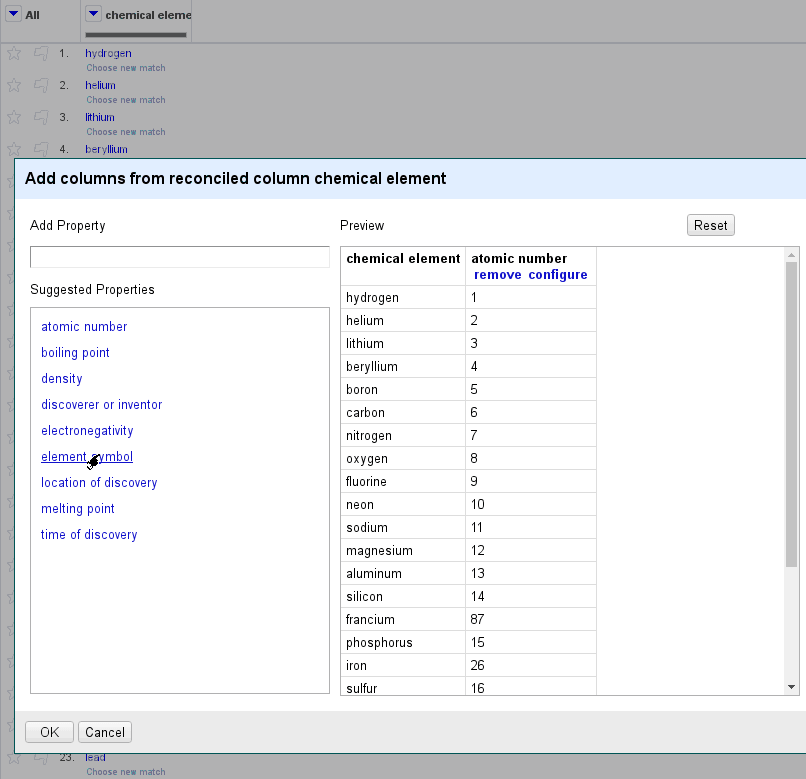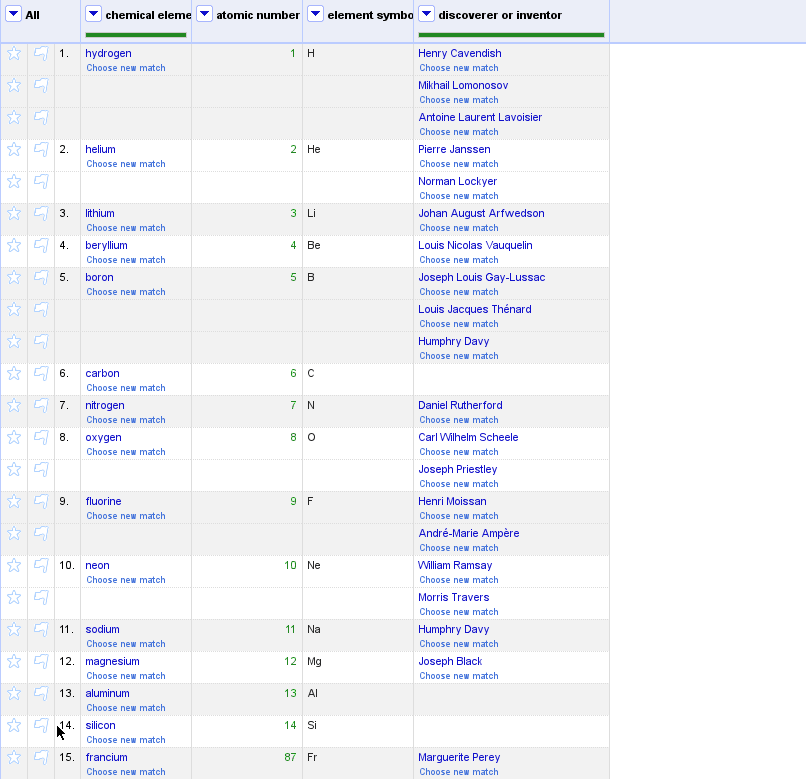
Any feedback on the user experience or on the details of the API would
be very welcome! A screencast is attached (expect things to be very
slow: it is normal, I have plans to speed them up).
Cheers,
Antonin
repository.
Thad & Jacky: do you think it would be possible to add me to the
OpenRefine organization? I would continue to use pull requests in the
same way but that would enable me to work on GitHub issues (cleaning up
existing ones) and GitHub projects (creating one for Wikidata integration).
Any feedback on the user experience or on the details of the API would
be very welcome! A screencast is attached (expect things to be very
slow: it is normal, I have plans to speed them up).
Cheers,
Antonin

Owen Stephens
Jul 18, 2017, 5:04:49 AM7/18/17
to OpenRefine, li...@antonin.delpeuch.eu
Just to say that I haven't looked at the actual code, so can't comment on that, but in terms of the functionality it looks brilliant!
I can see this being very useful.
Owen

Ettore Rizza
Jul 18, 2017, 6:10:08 AM7/18/17
to OpenRefine, li...@antonin.delpeuch.eu
Brilliant is the appropriate word !

I do not see a list of suggested properties, such as in the Antonin screencast, but it works !
Ettore Rizza
Jul 18, 2017, 6:25:39 AM7/18/17
to OpenRefine, li...@antonin.delpeuch.eu
Would it be technically possible to get information that is NOT a Wikidata property, such as the description or the corresponding Wikipedia pages?
Antonin Delpeuch (lists)
Jul 18, 2017, 6:26:20 AM7/18/17
to openr...@googlegroups.com
On 18/07/2017 11:10, Ettore Rizza wrote:
> Brilliant is the appropriate word !
Glad you like it !
> Brilliant is the appropriate word !
>
> I do not see a list of suggested properties, such as in the Antonin
> screencast, but it works !
- to have reconciled your column against a particular type
- that this type (or any super-class of it) uses "property for this
type" (https://www.wikidata.org/wiki/Property:P1963) to suggest properties.
We could also change this to rely on a sample of reconciled values
instead of the target reconciliation type… I think it makes life
slighlty harder for service providers though. This is typically the sort
of thing we should discuss!
Antonin
>
> Le mardi 18 juillet 2017 11:04:49 UTC+2, Owen Stephens a écrit :
>
> Just to say that I haven't looked at the actual code, so can't
> comment on that, but in terms of the functionality it looks brilliant!
>
> I can see this being very useful.
>
> Owen
>
> On Tuesday, July 18, 2017 at 9:28:28 AM UTC+1, Antonin Delpeuch
> (lists) wrote:
>
> Thad kindly merged my PR so the feature is available in the
> official
> repository.
>
> Thad & Jacky: do you think it would be possible to add me to the
> OpenRefine organization? I would continue to use pull requests
> in the
> same way but that would enable me to work on GitHub issues
> (cleaning up
> existing ones) and GitHub projects (creating one for Wikidata
> integration).
>
> Any feedback on the user experience or on the details of the API
> would
> be very welcome! A screencast is attached (expect things to be very
> slow: it is normal, I have plans to speed them up).
>
> Cheers,
> Antonin
>
>
>
>
Antonin Delpeuch (lists)
Jul 18, 2017, 6:28:20 AM7/18/17
to Ettore Rizza, OpenRefine
On 18/07/2017 11:25, Ettore Rizza wrote:
> Would it be technically possible to get information that is NOT a
> Wikidata property, such as the description or the corresponding
> Wikipedia pages?
This is not possible yet but it would not be very hard to implement. It
> Would it be technically possible to get information that is NOT a
> Wikidata property, such as the description or the corresponding
> Wikipedia pages?
would actually be a good idea of default property to suggest.
Adding it as a feature request on the service:
https://github.com/wetneb/openrefine-wikidata/issues/17
Antonin
Ettore Rizza
Jul 18, 2017, 6:34:15 AM7/18/17
to OpenRefine, ettor...@gmail.com, li...@antonin.delpeuch.eu
Thank you for these details and for this work, Antonin. Just a last question, a bit on the side : your service seems rather quick. Is it based on SPARQL queries, as is the case with the Deri's RDF extension ? Can we use your reconciliation service in a Python script without going through Open Refine?
Antonin Delpeuch (lists)
Jul 18, 2017, 6:46:06 AM7/18/17
to Ettore Rizza, OpenRefine
You are very welcome to use the API without going through OpenRefine. It
has not been advertised for that but I plan to do so.
The service currently uses the Wikidata API to fetch properties. But
there is a lot of optimization that can still be done.
In some cases SPARQL would be quicker. For instance if you want to fetch
multiple properties on a batch of items, you can do that:
SELECT ?s ?p ?o WHERE {
VALUES ?s { wd:Q42 wd:Q30 … all my qids … }
VALUES ?p { wdt:P31 wdt:P2427 … all my properties … }
?s ?p ?o
}
But that does not work as soon as some of your properties are property
paths…
Antonin
> <https://github.com/wetneb/openrefine-wikidata/issues/17>
>
> Antonin
>
has not been advertised for that but I plan to do so.
The service currently uses the Wikidata API to fetch properties. But
there is a lot of optimization that can still be done.
In some cases SPARQL would be quicker. For instance if you want to fetch
multiple properties on a batch of items, you can do that:
SELECT ?s ?p ?o WHERE {
VALUES ?s { wd:Q42 wd:Q30 … all my qids … }
VALUES ?p { wdt:P31 wdt:P2427 … all my properties … }
?s ?p ?o
}
But that does not work as soon as some of your properties are property
paths…
Antonin
>
> Antonin
>
Thad Guidry
Jul 18, 2017, 10:18:41 AM7/18/17
to openr...@googlegroups.com
We could also change this to rely on a sample of reconciled values
instead of the target reconciliation type… I think it makes life
slighlty harder for service providers though. This is typically the sort
of thing we should discuss!
Antonin
It not only makes life harder for service providers...it also makes the data quality a moving target. We actually tried some of that when Freebase was around as a few Freebase Apps (APIs).
Datasets are not created equal !! or created equally well !! Sometimes folks have very messy data that is not neatly tucked and categorized into a single column or rows of categories. They sometimes have multiple types in a column where they are using OpenRefine to facet and discover those types and then polish the data against each type with a reconciling pass.
For now, I think its best to just show the "possible" types and then let the human decide which type they'd like to reconcile and work with first...and then letting them extend and backfill knowledge from Wikidata and service providers. They can then make many more passes to reconcile on additional types as they discover and learn more about the awful quality of their dataset :) and refine and polish it to hopefully share back with the world....perhaps against a Datproject registry or CKAN instance or Google Spreadsheet...or Wikidata itself with additional clean data.
-Thad
Thad Guidry
Jul 18, 2017, 10:27:21 AM7/18/17
to openr...@googlegroups.com
Antonin,
I'll personally have no problem pulling you in as a contributor to OpenRefine. I know there are parts that you could help with and others were you and I both don't have a clue :) That's when we rely on Jacky and others to help out. :)
I created 2 project goals for this year of 2017 if you haven't seen them yet and you probably could help with those as well.
Another project goal could be against more Wikidata integration and having you part of that discussion would be ideal !
Incidentally, we have our other mailing list for Developers that we can start using and coordinating in, so we don't bother our user base too much.
Jacky, do you have any hesitation about any of the above ?
-Thad

{kind=link}
magdmartin
Jul 18, 2017, 3:02:35 PM7/18/17
to OpenRefine
+1 to make Antonin part of the OpenRefine Organization on Github
qi cui
Jul 18, 2017, 8:39:33 PM7/18/17
to OpenRefine
+1 to add Antony
Thad Guidry
Jul 18, 2017, 9:49:05 PM7/18/17
to OpenRefine
DONE ! Welcome Antonin to our core team and also design team ! (accept on your email invites that were sent)
-Thad
On Tue, Jul 18, 2017 at 7:39 PM qi cui <cuiq...@gmail.com> wrote:
+1 to add Antony
--
You received this message because you are subscribed to the Google Groups "OpenRefine" group.
To unsubscribe from this group and stop receiving emails from it, send an email to openrefine+...@googlegroups.com.
Ettore Rizza
Aug 21, 2017, 8:11:24 AM8/21/17
to OpenRefine, li...@antonin.delpeuch.eu
Looks like de data extension API doesn't work anymore with the last development version.

Reply all
Reply to author
Forward
0 new messages