General recipe to strip and split html tables
293 views
Skip to first unread message

Sebastian Lipp
Sep 2, 2017, 12:26:29 PM9/2/17
to openr...@googlegroups.com
Hello,
doing my first steps in OR I ran into another problem.
I want to have an html table like below split into several columns named
after table header (<th>) containing the table data (<td>).
This problem is so general that there must be a solution already, but I
can't find it online. Would anybody please help me on that?
Thank you,
Sebastian
<table class="GemVerz" id="reg09761000"> <thead><tr><th colspan="2">Augsburg</th></tr></thead>
<tbody><tr><th>Stand</th><td>2015-12-31</td></tr>
<tr><th>Bundesland</th><td>Bayern</td></tr>
<tr><th>Regierungsbezirk</th><td>Schwaben</td></tr>
<tr><th>Amtl. Gemeindeschl�ssel</th><td>09761000</td></tr>
<tr><th>Gemeindetyp</th><td>Kreisfreie Stadt</td></tr>
<tr><th>Postleitzahl</th><td>86150</td></tr>
<tr><th>Anschrift der Gemeinde</th><td>Stadt Augsburg</td></tr>
<tr><th class="indLft1">Stra�e</th><td>Postfach</td></tr>
<tr><th class="indLft1">Ort</th><td>86143 Augsburg</td></tr>
<tr><th>Fl�che km<sup>2</sup></th><td> 146,86</td></tr>
<tr><th>Einwohner</th><td>286.374</td></tr>
<tr><th class="indLft1">m�nnlich</th><td>140.323</td></tr>
<tr><th class="indLft1">weiblich</th><td>146.051</td></tr>
<tr><th class="indLft1">je km<sup>2</sup></th><td>1.950</td></tr>
</tbody>
</table>
<p>Quelle: Einwohner basieren auf den Ergebnissen des Zensus 2011.</p>
doing my first steps in OR I ran into another problem.
I want to have an html table like below split into several columns named
after table header (<th>) containing the table data (<td>).
This problem is so general that there must be a solution already, but I
can't find it online. Would anybody please help me on that?
Thank you,
Sebastian
<table class="GemVerz" id="reg09761000"> <thead><tr><th colspan="2">Augsburg</th></tr></thead>
<tbody><tr><th>Stand</th><td>2015-12-31</td></tr>
<tr><th>Bundesland</th><td>Bayern</td></tr>
<tr><th>Regierungsbezirk</th><td>Schwaben</td></tr>
<tr><th>Amtl. Gemeindeschl�ssel</th><td>09761000</td></tr>
<tr><th>Gemeindetyp</th><td>Kreisfreie Stadt</td></tr>
<tr><th>Postleitzahl</th><td>86150</td></tr>
<tr><th>Anschrift der Gemeinde</th><td>Stadt Augsburg</td></tr>
<tr><th class="indLft1">Stra�e</th><td>Postfach</td></tr>
<tr><th class="indLft1">Ort</th><td>86143 Augsburg</td></tr>
<tr><th>Fl�che km<sup>2</sup></th><td> 146,86</td></tr>
<tr><th>Einwohner</th><td>286.374</td></tr>
<tr><th class="indLft1">m�nnlich</th><td>140.323</td></tr>
<tr><th class="indLft1">weiblich</th><td>146.051</td></tr>
<tr><th class="indLft1">je km<sup>2</sup></th><td>1.950</td></tr>
</tbody>
</table>
<p>Quelle: Einwohner basieren auf den Ergebnissen des Zensus 2011.</p>

Ettore Rizza
Sep 2, 2017, 1:35:29 PM9/2/17
to OpenRefine
Where is stored this HTML table? In a file on your computer or in a single Open Refine cell?
Sebastian Lipp
Sep 2, 2017, 2:06:42 PM9/2/17
to OpenRefine
Hello Ettore,
Ettore Rizza <ettor...@gmail.com> writes:
> Where is stored this HTML table? In a file on your computer or in a single
> Open Refine cell?
For any row a version of this table is stored in a single cell. I want
it to "expand" to several new cells.
Ettore Rizza <ettor...@gmail.com> writes:
> Where is stored this HTML table? In a file on your computer or in a single
> Open Refine cell?
it to "expand" to several new cells.
Ettore Rizza
Sep 2, 2017, 2:33:44 PM9/2/17
to OpenRefine
So, you need to parse the HTML table. The best way to do that is to first extract each rows with this Grel formula :
Then to extract the headers with this one :
You can then split the new cells using the symbol | as separator. If you want the header values as column names, you need to do finally a "columnize by key value".
Here is a screencast, it will be more clear than my explanations.
forEach(value.parseHtml().select('td'), e, e.htmlText()).join('|')Then to extract the headers with this one :
forEach(value.parseHtml().select('th'), e, e.htmlText()).join('|')You can then split the new cells using the symbol | as separator. If you want the header values as column names, you need to do finally a "columnize by key value".
Here is a screencast, it will be more clear than my explanations.

Sebastian Lipp
Sep 4, 2017, 8:03:39 AM9/4/17
to OpenRefine
Following your recipe almost works but leaves strange results I don't
understand.
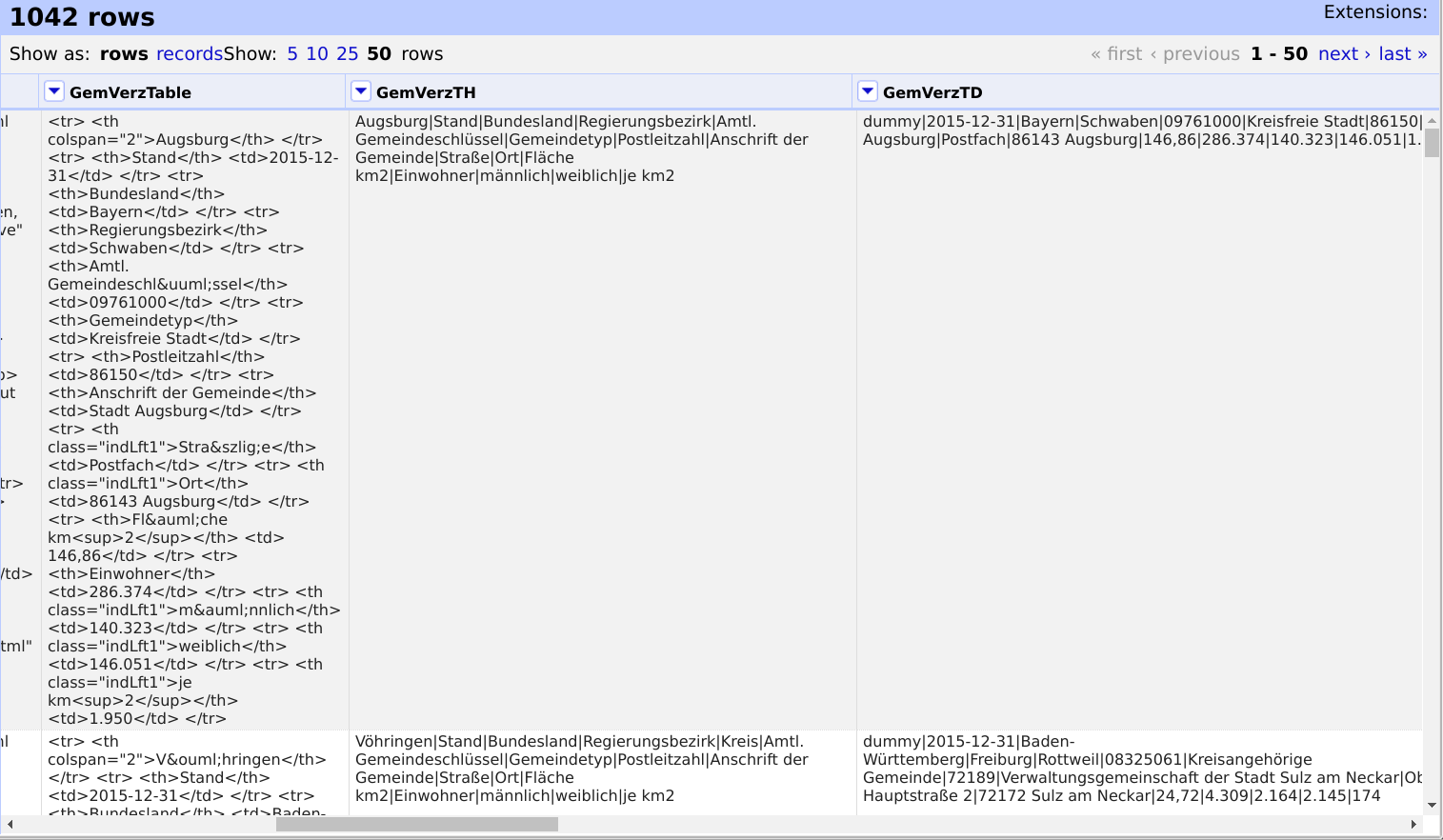
There are 1042 rows each containing a version of that HTML table in
GemVerzTable. They smoothly extract to GemVerzTH and GemVerzTD. (see
shot1, prepended "dummy" by intention)
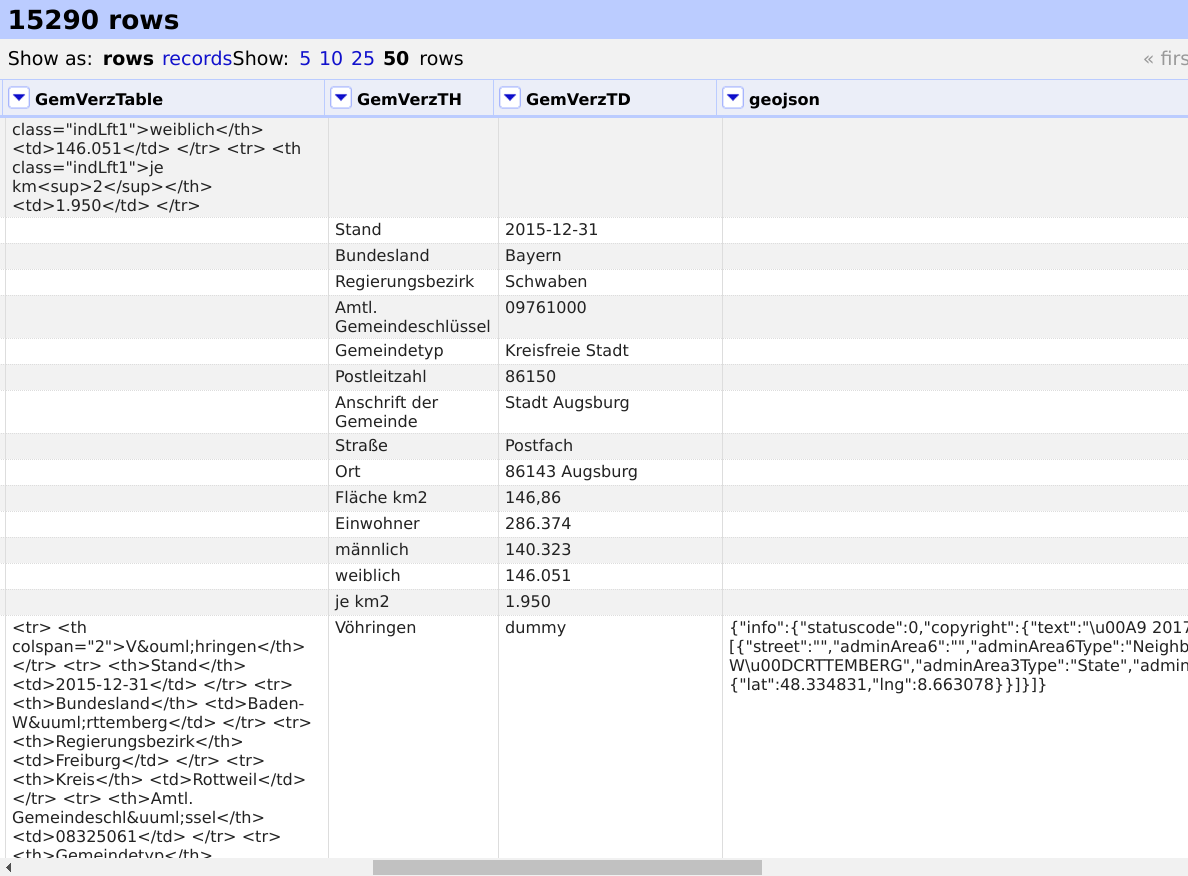
Splitting also looks very well. (shot2)
Now I set any column left of a "dummy" column to "dummy" to not have
several headers later. (shot3)
Columnizing by key column now works fine for those "dummy" columns. The
rest of the values of row 1 fall down to row 2. (shot4, note that there
are only 997 rows left from initially 1042)
All remaining values are just lost. Looks like they are virtually gone
through the top to row -1 and following.
Any clue what's going on here?
shot1: <https://transfer.sh/OJW9t/shot1.png>
shot2: <https://transfer.sh/12MyQm/shot2.png>
shot3: <https://transfer.sh/jjD7v/shot3.png>
shot4: <https://transfer.sh/K2Ffx/shot4.png>
Ettore Rizza <ettor...@gmail.com> writes:
> So, you need to parse the HTML table. The best way to do that is to first
> extract each rows with this Grel formula :
>
> forEach(value.parseHtml().select('td'), e, e.htmlText()).join('|')
>
> Then to extract the headers with this one :
>
> forEach(value.parseHtml().select('th'), e, e.htmlText()).join('|')
>
> You can then split the new cells using the symbol | as separator. If you
> want the header values as column names, you need to do finally a "columnize
> by key value".
>
> Here is a screencast, it will be more clear than my explanations.
>
> <https://lh3.googleusercontent.com/-qzjuwRUTQ08/War5LWAMl1I/AAAAAAAAUYs/YkG8QK8_Zn4cqs4kg74PgkKbyWRtO92YwCLcBGAs/s1600/screencast.gif>
> You received this message because you are subscribed to the Google Groups "OpenRefine" group.
> To unsubscribe from this group and stop receiving emails from it, send an email to openrefine+...@googlegroups.com.
> For more options, visit https://groups.google.com/d/optout.
understand.
There are 1042 rows each containing a version of that HTML table in
GemVerzTable. They smoothly extract to GemVerzTH and GemVerzTD. (see
shot1, prepended "dummy" by intention)
Splitting also looks very well. (shot2)
Now I set any column left of a "dummy" column to "dummy" to not have
several headers later. (shot3)
Columnizing by key column now works fine for those "dummy" columns. The
rest of the values of row 1 fall down to row 2. (shot4, note that there
are only 997 rows left from initially 1042)
All remaining values are just lost. Looks like they are virtually gone
through the top to row -1 and following.
Any clue what's going on here?
shot1: <https://transfer.sh/OJW9t/shot1.png>
shot2: <https://transfer.sh/12MyQm/shot2.png>
shot3: <https://transfer.sh/jjD7v/shot3.png>
shot4: <https://transfer.sh/K2Ffx/shot4.png>
Ettore Rizza <ettor...@gmail.com> writes:
> So, you need to parse the HTML table. The best way to do that is to first
> extract each rows with this Grel formula :
>
> forEach(value.parseHtml().select('td'), e, e.htmlText()).join('|')
>
> Then to extract the headers with this one :
>
> forEach(value.parseHtml().select('th'), e, e.htmlText()).join('|')
>
> You can then split the new cells using the symbol | as separator. If you
> want the header values as column names, you need to do finally a "columnize
> by key value".
>
> Here is a screencast, it will be more clear than my explanations.
>
>
>
>
>
> Le samedi 2 septembre 2017 20:06:42 UTC+2, Sebastian Lipp a écrit :
>>
>> Hello Ettore,
>>
>
>
>
> Le samedi 2 septembre 2017 20:06:42 UTC+2, Sebastian Lipp a écrit :
>>
>> Hello Ettore,
>>
>> Ettore Rizza <ettor...@gmail.com <javascript:>> writes:
>> > Where is stored this HTML table? In a file on your computer or in a
>> single
>> > Open Refine cell?
>>
>> For any row a version of this table is stored in a single cell. I want
>> it to "expand" to several new cells.
>>
>
> --
>> > Where is stored this HTML table? In a file on your computer or in a
>> single
>> > Open Refine cell?
>>
>> For any row a version of this table is stored in a single cell. I want
>> it to "expand" to several new cells.
>>
>
> You received this message because you are subscribed to the Google Groups "OpenRefine" group.
> To unsubscribe from this group and stop receiving emails from it, send an email to openrefine+...@googlegroups.com.
> For more options, visit https://groups.google.com/d/optout.
Ettore Rizza
Sep 4, 2017, 9:00:09 AM9/4/17
to OpenRefine
Columnize by key value doesn't accept columns with blank cells before the column you choose as a key. After splitting gemVerzTH and gemVerzTD, you must use a fill down on gemVerzTable and on all columns before it if you want to keep them (It's not for nothing that in my screencast, I deleted the column containing the HTML table before doing the columnize by key value)
Next time, it will be much simpler if you post a sample of your actual data rather than screenshots.
Sebastian Lipp
Sep 5, 2017, 2:59:04 PM9/5/17
to OpenRefine
Dear Ettore,
after following your last advice I realized that there's a problem
with the fetched HTML table. A sample of my data is attached.
The column "GemVerzHTML" is fetched via
'http://www.statistik-portal.de/Statistik-Portal/gemeindeverz.asp?G=' +
escape(value, 'url') based on "Ort".
Those HTML tables in "GemVerzHTML" do start with "<thead><tr><th
[something]</th></tr></thead>" followed by <tbody> containing the actual
data. As <thead> contains no <td> I lazily parse the table adding dummy
data via "dummy|" + forEach(value.parseHtml().select('td'), e,
e.htmlText()).join('|').
But I didn't realize that some querys return several matches and thus
several tables.
So to get rid of that incosistency - and hopefully finally solve my
problem here - I suppose I'd need parseHtml() to skip <thead>.
Would you help me once again doing that?
Thank you a lot,
Sebastian
after following your last advice I realized that there's a problem
with the fetched HTML table. A sample of my data is attached.
The column "GemVerzHTML" is fetched via
'http://www.statistik-portal.de/Statistik-Portal/gemeindeverz.asp?G=' +
escape(value, 'url') based on "Ort".
Those HTML tables in "GemVerzHTML" do start with "<thead><tr><th
[something]</th></tr></thead>" followed by <tbody> containing the actual
data. As <thead> contains no <td> I lazily parse the table adding dummy
data via "dummy|" + forEach(value.parseHtml().select('td'), e,
e.htmlText()).join('|').
But I didn't realize that some querys return several matches and thus
several tables.
So to get rid of that incosistency - and hopefully finally solve my
problem here - I suppose I'd need parseHtml() to skip <thead>.
Would you help me once again doing that?
Thank you a lot,
Sebastian
Ettore Rizza
Sep 5, 2017, 4:12:35 PM9/5/17
to OpenRefine
If you have many tables in the same cell and you want to extract them all, the easiest way to proceed is :
1 Extract the HTML code of each table in a new column using the following formula:
forEach(value.parseHtml().select('tbody'), e, e).join('||')2 Do a "Split multivalued cells" on the new column using '||' as a separator.
3 Now, you can use the GREL formulas that I mentioned in my first answers and split again the results.

{kind=link}
{kind=link}
Thad Guidry
Sep 5, 2017, 6:15:32 PM9/5/17
to OpenRefine
Sebastian,
I lot of us that do web scraping will also sometimes just use Outwit Hub, instead of OpenRefine.
Don't get us wrong, you can do a lot of OpenRefine, but as the saying goes, "use the right tool for the job".
I myself use Outwit Hub Pro for some of the extra features. But you can do A LOT with just the free version as well.
-Thad
Sebastian Lipp
Sep 11, 2017, 2:06:14 AM9/11/17
to OpenRefine
Dear Ettore,
I finally got it all right that weekend - thanks to your help.
Greetings
>> an email to openrefine+...@googlegroups.com <javascript:>.
I finally got it all right that weekend - thanks to your help.
Greetings
Ettore Rizza
Sep 11, 2017, 5:02:37 AM9/11/17
to OpenRefine
You're welcome. I'm glad to see that Open Refine can do this kind of thing relatively easily.
As Thad says, there are scraping softwares that greatly facilitate this kind of task. On the other hand, what you just did with Open Refine was an excellent initiation to web scraping. What you've done looks exactly like a scraping with the Python BeautifulSoup library, except that Open Refine saved you from having to write "for loops" and HTTP requests.
PS: If it was a professional project, and if these instructions saved you time and therefore money, do not forget to take a look at https://salt.bountysource.com/teams/openrefine :p
Reply all
Reply to author
Forward
0 new messages