Getting started with nearest neighbour over multiple data values
11 views
Skip to first unread message

Dave Clissold
Mar 15, 2017, 5:05:59 PM3/15/17
to Neo4j
I should first point out I have no background in mathematics nor in programming, but am teaching myself the basics to be able to oversee a project, hire a team of developers and begin to plot out the data model, so apologies if my terminology is not correct. After a lot of research Neo4J seems the logical choice me and the start-up, mainly because of the simplicity in which queries can be compiled in cypher, but I would like to ask the community a question and hope that someone might be able to point in the right direction for further reading or possibly a foundation from which to build a query from.
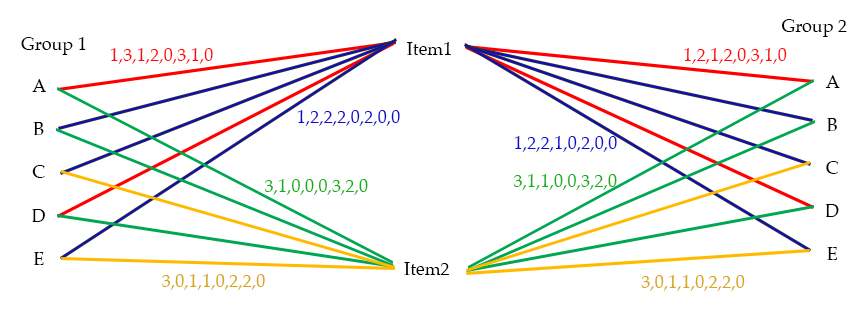
I am creating an application that will take a set of data values about the user, a set of personal preferences, and a set of data about an item, ratings on different aspects of the item. What I would like to achieve is (have also attached a graphic to help with visualising this)
1. A nearest neighbour weighting for their personal preferences matching a minimum of any 7 out of 10 responses (groups in the graphics).
2. A nearest neighbour based on the scores for the product, 15 different values (in the graphics I've shown 8), with results being returned biased by the above personal preferences nearest neighbour weighting
So in the graphical example, I could return all the green relationships from Group 1 and run a count on them
I have read the following and it seems to be a start but I would like some advice on where to look next to develop this further
https://neo4j.com/graphgist/a7c915c8-a3d6-43b9-8127-1836fecc6e2f
https://neo4j.com/graphgist/a7c915c8-a3d6-43b9-8127-1836fecc6e2f
Thanks in advance for any advice and assistance
{kind=link}
Reply all
Reply to author
Forward
0 new messages